记一次内存泄漏排查
背景
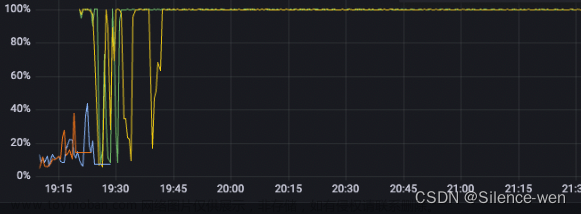
最近某项目的服务突然告警,cpu超85%,随后就是服务宕机。交付重启服务后恢复正常但是随后不久又开始告警,特别是白天,严重影响客户业务进行。
问题排查
1、分析日志
查看日志的过程中发现存在内存溢出(OOM),思考要么存在内存泄漏要么业务上触发了某个接口存在大对象,结合业务情况,应该是前一种情况大一些。
2、查看CPU占用高的线程
按步骤
- top 找到cpu高的进程
- top -Hp pid 找到进程中cpu占的比较高的线程
- printf ‘%x’ 线程id 打印出线程16进制id
- jstack pid >xxx.txt 将线程信息输出到某个文件方便查询
- 将cpu高的那个在步骤4中的xxx.txt中搜索出来
排查出线程都是: gc task thread parallelgc 这类线程(忘记截图了)占用CPU高。那么这里其实可以大致得出结论了。
3、用arthas dashboard 查看应用运行情况
老年代占比98%,随后CPU飙升(很多公司生产可能都不允许使用arthas,上面步骤2其实基本可以得出结论了)
4、结论
代码存在内存泄漏,老年代占用率过高,导致系统频繁full gc ,从而系统CPU飙升直至宕机。
问题处理
1、给启动参数加上 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${目录} (这块疏忽,之前没加)
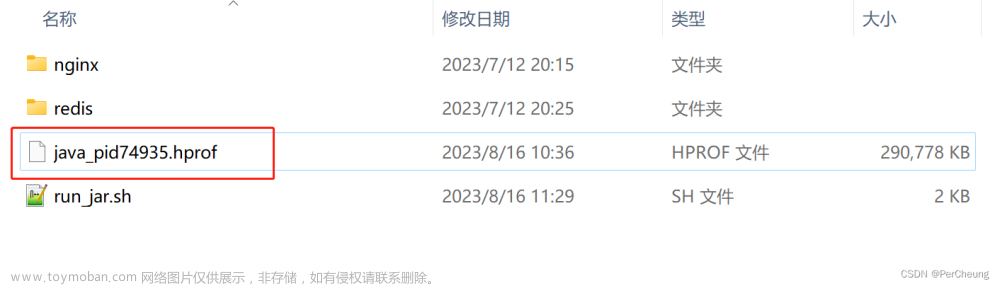
2、使用 MAT 分析 hprof文件
这里有个插曲,hprof文件太大,导致MAT打开报OOM。如果你是eclipse中安装的MAT 插件,可以在 setting(perferences)-> java -> Installed JREs -> jre -> edit -> variables 设置 内存大小 :
server -Xms4096m -Xmx4096m -XX:PermSize=512m -XX:MaxPermSize=512m

3、找到内存泄漏代码
有MAT帮忙,找到对应泄漏代码其实就简单多了。找到内存占用最大得结果线程进行查看就能看到对应的代码。



4、修改代码
看了下,是代码查询的时候,一次查询list过大导致的。后续和相关开发沟通后,优化了sql,重新发包部署。
5、观察
一段时间后服务器cpu恢复平稳~~~~~ 文章来源:https://www.toymoban.com/news/detail-415134.html
文章来源:https://www.toymoban.com/news/detail-415134.html
至此,本次排查结束,服务CPU恢复正常状态。后面又了解,为啥之前服务运行的好好的,最近这么频繁宕机,一个是内存泄漏,还有就是业务方系统全面铺开,业务压力骤增,从原来的日均五万的量增加到了十万,后续可能还会增加,借此机会和业务方沟通,又升级了服务硬件配置,嘻~~~~文章来源地址https://www.toymoban.com/news/detail-415134.html
到了这里,关于记一次内存泄漏排查的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[JAVA]websocket引起的内存泄漏问题排查](https://imgs.yssmx.com/Uploads/2024/02/544204-1.png)