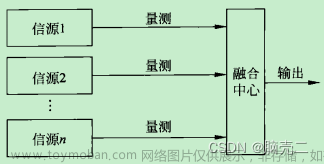
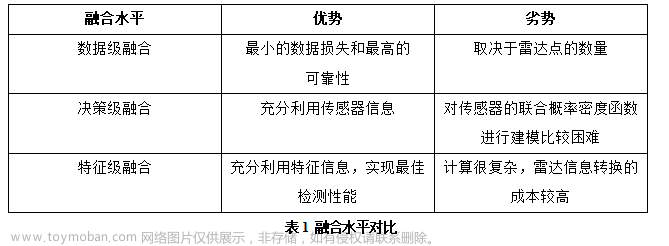
该列表会不定期更新…
困惑与解答:
问题:匈牙利算法中的增广矩阵路径是什么意思
解答:
匈牙利算法是解决二分图最大匹配的经典算法之一。其中的增广矩阵路径指的是在当前匹配下,从一个未匹配节点开始,沿着交替路(交替路是指依次经过未匹配点、已匹配点、未匹配点……的路径)不断寻找增广路(增广路是指起点和终点都是未匹配点的路),直到找到一条增广路为止。
在匈牙利算法中,通过搜索增广矩阵路径来更新匹配关系,每次找到一条增广路就可以将当前的匹配数加1,直至不存在增广路为止。因此,增广矩阵路径是匈牙利算法中非常重要的概念。
个人理解概述:
- 增广路径是从一个未匹配点开始,沿着路径(未匹配点与匹配点来回交替的路径),一直找到另一个未匹配点结束的路径。
文章来源地址https://www.toymoban.com/news/detail-415201.html
问题:扩展卡尔曼滤波是非线性方程求解问题,是将非线性方程拟合为线性方程吗
解答:
扩展卡尔曼滤波(Extended Kalman Filter,EKF)是一种用于非线性系统状态估计的滤波算法,在某些情况下可以将非线性方程的求解问题转化为线性方程的求解问题。
具体来说,扩展卡尔曼滤波通过对非线性系统的状态方程和观测方程进行一阶泰勒展开,将非线性问题线性化。然后,根据线性化的模型设计卡尔曼滤波器,对系统的状态进行估计。在每个时间步骤中,扩展卡尔曼滤波都要预测下一个时刻的状态,并根据实际的测量结果进行修正预测值。由于扩展卡尔曼滤波是基于线性化模型进行求解的,因此其准确性和鲁棒性取决于线性化模型的正确性和精度。
总之,扩展卡尔曼滤波是一种将非线性问题线性化之后应用卡尔曼滤波来完成状态估计的方法。虽然EKF可以将原非线性问题转化为线性问题进行求解,但这并不等同于将非线性方程拟合为线性方程。在使用EKF时,仍需要考虑模型的精度和误差对滤波器性能的影响。
个人理解概述:
- 增广路径是从一个未匹配点开始,沿着路径(未匹配点与匹配点来回交替的路径),一直找到另一个未匹配点结束的路径。
文章来源:https://www.toymoban.com/news/detail-415201.html
问题:自动驾驶中用到的是扩展卡尔曼滤波还是无损卡尔曼滤波
解答:
在自动驾驶中,常常使用扩展卡尔曼滤波(Extended Kalman Filter,EKF)来实现对车辆状态的估计和预测。
EKF是一种针对非线性状态估计问题的滤波算法,可以将非线性系统状态方程和观测方程进行一阶泰勒展开,将非线性问题近似为线性问题,然后应用卡尔曼滤波来完成状态估计。在自动驾驶中,由于车辆的运动和环境变化都是非线性的,因此EKF被广泛应用于车辆状态的估计和预测,包括位置、速度、加速度以及车辆姿态等。
相比之下,无损卡尔曼滤波(Unscented Kalman Filter,UKF)则是另外一种针对非线性问题的卡尔曼滤波扩展形式。它通过使用称为“sigma点”的方法来捕捉非线性函数的统计特征,从而避免了在扩展卡尔曼滤波中需要进行一阶泰勒展开的缺陷。不过,在实际应用中,EKF通常被认为更加稳定可靠,更容易调整和优化。
因此,在自动驾驶中,一般使用扩展卡尔曼滤波来实现车辆状态的估计和预测。
个人理解概述:
问题:在多传感器融合中,如何设置激光雷达和毫米波的观测噪声模型
解答:
在多传感器融合中,激光雷达和毫米波雷达通常用于感知车辆周围的环境信息。为了实现精确的多传感器融合,需要对不同传感器的观测噪声进行建模。以下是在车辆自动驾驶应用场景中,如何设置激光雷达和毫米波雷达的观测噪声模型的一些常见方法:
激光雷达:激光雷达通常用于获取车辆周围的点云数据。对于激光雷达数据,通常采用高斯分布来建模其观测噪声,其均值为0,方差可以根据激光雷达的具体性能指标进行估计。例如,如果激光雷达的精度比较高,则可以将方差设置得比较小。
毫米波雷达:毫米波雷达通常用于感知车辆周围的物体的运动状态和位置信息。对于毫米波雷达数据,通常采用卡方分布来建模其观测噪声。卡方分布的自由度可以根据毫米波雷达的具体性能指标进行估计。例如,如果毫米波雷达的精度比较高,则可以将自由度设置得比较小。
总之,在实际应用中,需要根据不同传感器的具体性能指标进行观测噪声模型的建模。同时,为了更精确地估计传感器的观测噪声,还可以使用在线参数学习等方法来对观测噪声进行动态调整。
个人理解概述:
问题:什么是卡方分布
解答:
卡方分布是一种概率分布,通常用于统计学中的假设检验和置信区间。它是由皮尔逊在其研究 χ 2 χ^2 χ2检验时引入的,因此称为卡方分布。卡方分布的形状取决于自由度参数,表示数据集中独立变量的数量。在实践中,卡方分布经常用于比较观察到的数据与期望的理论值之间的差异,以评估是否存在显著性。

个人理解概述:
问题:什么是非线性优化
解答:
非线性优化是数学中的一个分支,它涉及到在满足一定约束条件下,寻找函数最小值或最大值的问题。与线性优化不同的是,非线性优化中的目标函数和约束条件不再是线性的,而是可以是任意的非线性函数。
这种技术广泛应用于工程、经济学、物理学、金融学以及其他领域里的许多实际问题中。例如,在工程学中,非线性优化通常用于优化设计参数,以便最小化成本或最大化性能。在金融学中,它可以用于资产组合优化或风险管理等方面。
个人理解概述:
满足一定约束条件下,查找函数极值问题
问题:在自动驾驶的感知跟踪中,什么场景下需要用到非线性滤波来解决问题
解答:
在自动驾驶的感知跟踪中,如果被跟踪的物体的运动状态存在非线性关系或者传感器的噪声具有非线性特性,那么就需要使用非线性滤波算法来解决问题。
一些场景下可能需要用到非线性滤波算法,例如:
- 目标物体存在非线性运动模型:如果被跟踪的物体运动状态变化较为复杂,不能简单地用线性模型来描述其运动规律,这时可以考虑使用扩展卡尔曼滤波(EKF)或无迹卡尔曼滤波(UKF)等非线性滤波方法。
- 传感器输出存在非线性影响:如果使用的传感器本身存在非线性因素,例如相机畸变、雷达射线角度偏差等,这会导致测量数据出现非线性误差,这时也需要使用非线性滤波算法对数据进行处理。
总之,在自动驾驶的感知跟踪中,选择合适的滤波算法取决于具体的应用场景和要求。在实际应用中,需要根据系统的实际情况进行评估和选择。
个人理解概述:
问题:在自动驾驶中,为什么说车辆的运动和环境变化都是非线性的
解答:
在自动驾驶中,车辆的运动和环境变化都是非线性的。这主要是因为:
车辆运动具有非线性特性:车辆在实际行驶过程中,其运动状态会受到多种因素的影响,例如地面摩擦力、重心偏移、轮胎滑动等,这些因素都会导致车辆的运动状态出现非线性变化。
环境变化也具有非线性特性:在自动驾驶的场景下,车辆所处的环境可能会发生各种复杂的变化,例如天气变化、路况变化、其他车辆行驶状态的变化等,这些变化都会对车辆的感知和决策产生影响,同时也会对车辆的运动状态产生非线性影响。
基于以上原因,为了使自动驾驶系统准确地感知和预测车辆的运动状态和周围环境的变化,需要使用一些能够处理非线性问题的数学模型和算法。例如,可以使用扩展卡尔曼滤波(EKF)或无迹卡尔曼滤波(UKF)等非线性滤波算法来估计车辆的运动状态和环境变化,以便更好地实现自动驾驶。
个人理解概述:
问题:卡尔曼滤波中Ht * P *H的物理意义是什么
解答:
在卡尔曼滤波中,Ht * P * H表示卡尔曼滤波器中的一项矩阵运算,其物理意义是对当前估计状态的不确定性进行评估。下面对其进行详细解释。
在卡尔曼滤波中,P是状态估计误差的协方差矩阵,表示当前对状态的估计与真实状态之间的误差。H是观测矩阵,表示状态向量和观测向量之间的关系。Ht表示H的转置矩阵。
Ht * P * H的运算结果为一个矩阵,其行数和列数分别为观测向量的维度。这个矩阵表示当前状态估计的不确定性。具体来说,Ht * P * H的对角线上的元素表示每个观测量的方差,越大表示估计的不确定性越大,反之则越小。
因此,Ht * P * H的物理意义是对当前估计状态的不确定性进行评估。在卡尔曼滤波中,可以利用这个矩阵来进行状态估计和预测,从而提高状态估计的精度和可靠性。
个人理解概述:
- Ht * P * H的物理意义是对当前估计状态的不确定性进行评估
问题:匈牙利算法中的增广路是开始从二分图的出发组开始,到二分图的另一个图的节点结束吗
解答:
是的,匈牙利算法中的增广路是从二分图的一个部分开始(通常是左侧部分),经过一条未匹配的边,然后到达另一个部分(通常是右侧部分)。增广路的目的是通过将路径上的未匹配边和已匹配边交替连接来形成新的匹配。这个过程可以重复进行,直到无法找到增广路为止,此时已经得到了最大匹配。
个人理解概述:
问题:增广路径是从左边部分开始,到右边部分结束,交替路包含增广路
解答:
在匈牙利算法中,增广路径是从左侧部分开始,经过一系列交替路(包括从左侧部分到右侧部分和从右侧部分到左侧部分)后到达右侧部分。换句话说,增广路径可以被看作是一条特殊的交替路,因为它始终从左侧部分开始,最终到达右侧部分。
个人理解概述:
问题:交替路是从左边开始,但是不一定在哪边结束
解答:
在匈牙利算法中,交替路的起点是左侧部分中的未匹配顶点,但是它可以通过右侧部分的未匹配边(或者已匹配边)来到达右侧部分中的顶点。接着,我们可以从右侧部分中的顶点开始,沿着与左侧部分中的顶点相连的未匹配边(或已匹配边)返回左侧部分。因此,一条交替路可以在左侧部分或右侧部分结束,具体取决于它能否找到一条增广路径。
需要注意的是,如果一条交替路以未匹配的右侧部分中的顶点结束,则说明这个顶点是一个可扩展的顶点。这个顶点可以被添加到当前的匹配中,进而使其匹配数增加1。
个人理解概述:
问题:匈牙利算法 交替路是最大匹配路吗
解答:
在匈牙利算法中,交替路是指从一个未匹配的顶点开始,经过一系列交替选择匹配边和未匹配边,最终到达另一个未匹配的顶点的路径。
在匈牙利算法的实现中,每次寻找交替路时,我们都会按照增广路径的方式来选择未匹配的顶点。如果我们能够找到一条交替路,那么这条路上必定存在一些未匹配的顶点和已匹配的顶点,而且这些已匹配的顶点构成了当前的最大匹配。因此,交替路并不一定是最大匹配路,但它其中包含的最大匹配是当前算法已经求得的最大匹配的一部分。
当然,在匈牙利算法中,我们会一直寻找交替路,并将其中包含的未匹配顶点与已匹配顶点进行交换,直到无法找到新的交替路为止。这意味着最终找到的所有交替路所包含的未匹配顶点和已匹配顶点构成的路径就是当前图的最大匹配。因此,我们可以说,在匈牙利算法中,交替路所包含的最大匹配是整个算法求得的最大匹配的一部分,而最终找到的所有交替路所包含的未匹配顶点和已匹配顶点构成的路径就是整个图的最大匹配。
个人理解概述:交替路包含最大匹配,最大匹配就是增广路径找不到未匹配点之后的路径
问题:增广路径是最大匹配吗
解答:
在匈牙利算法中,增广路径是指从一个未匹配的顶点开始,经过一系列交替选择匹配边和未匹配边,最终到达另一个未匹配的顶点的路径。因此,如果我们找到了一条增广路径,它包含一些未匹配的顶点和已匹配的顶点,并且这些已匹配的顶点与未匹配的顶点构成了当前图的最大匹配。
所以,可以说增广路径不仅仅是最大匹配,而且还是在当前最大匹配基础上新增加的匹配。具体来说,在寻找增广路径的过程中,我们会根据当前的匹配情况来选择匹配边和未匹配边,以便让路径上的未匹配顶点变成已匹配顶点,从而使得当前的匹配数目增加1。因此,虽然增广路径本身并不是整个图的最大匹配,但它可以作为一种求解最大匹配的方法,通过不断寻找增广路径来逐步增加匹配数目,直到找不到新的增广路径为止,此时得到的就是整个图的最大匹配。
个人理解概述:增广路径本身找不到可以匹配点增加匹配数据的增广路径,就是最大匹配,但还能找到的时候不是最大匹配
问题:std::bind(&HungarianOptimizer::StarZeroes, this);这个函数在匈牙利匹配算法中什么作用
解答:
在匈牙利算法中,函数
HungarianOptimizer::StarZeroes()用于在矩阵中寻找未被覆盖的0,并将它们标记为“星号”。这是算法中的一个重要步骤,因为它为后续步骤提供了信息。在这个函数中,std::bind()被用于将类成员函数绑定到当前实例对象中,以便在算法的执行过程中调用该函数。
在C++中,类成员函数需要通过对象或指向对象的指针来调用,因为它们依赖于类的状态。在匈牙利算法中,
HungarianOptimizer::StarZeroes()函数是一个类成员函数,因此需要通过类实例来调用。使用std::bind()可以将类成员函数绑定到当前实例对象中,以便在算法的执行过程中调用该函数。这种方式可以确保函数能够正确地访问类的成员变量和函数,并且可以在算法的不同阶段多次调用该函数。
在类成员函数内部调用另一个类成员函数时,不需要使用
std::bind()进行绑定,因为此时已经在类的成员函数范围内,可以直接使用成员函数指针或者通过this指针来调用另一个成员函数。
例如,在匈牙利算法中,可能会在
HungarianOptimizer::StarZeroes()函数中调用另一个类成员函数HungarianOptimizer::FindStarInCol()来查找列中的星号。此时可以直接使用成员函数指针或者通过this指针来调用FindStarInCol(),而不需要使用std::bind()进行绑定。关键在于需要保证调用的成员函数在同一个对象中。
个人理解概述:
-
关键在于需要保证调用的成员函数在同一个对象中。
问题:
解答:
个人理解概述:
问题:
解答:
个人理解概述:
问题:
解答:
个人理解概述:
问题:
解答:
个人理解概述:
问题:
解答:
个人理解概述:
问题:
解答:
个人理解概述:
问题:
解答:
个人理解概述:
到了这里,关于用ChatGPT学习多传感器融合中的基础知识的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!