目录
1.算法原理:
2.程序流程:
3.程序代码:
4.运行结果(部分结果展示):
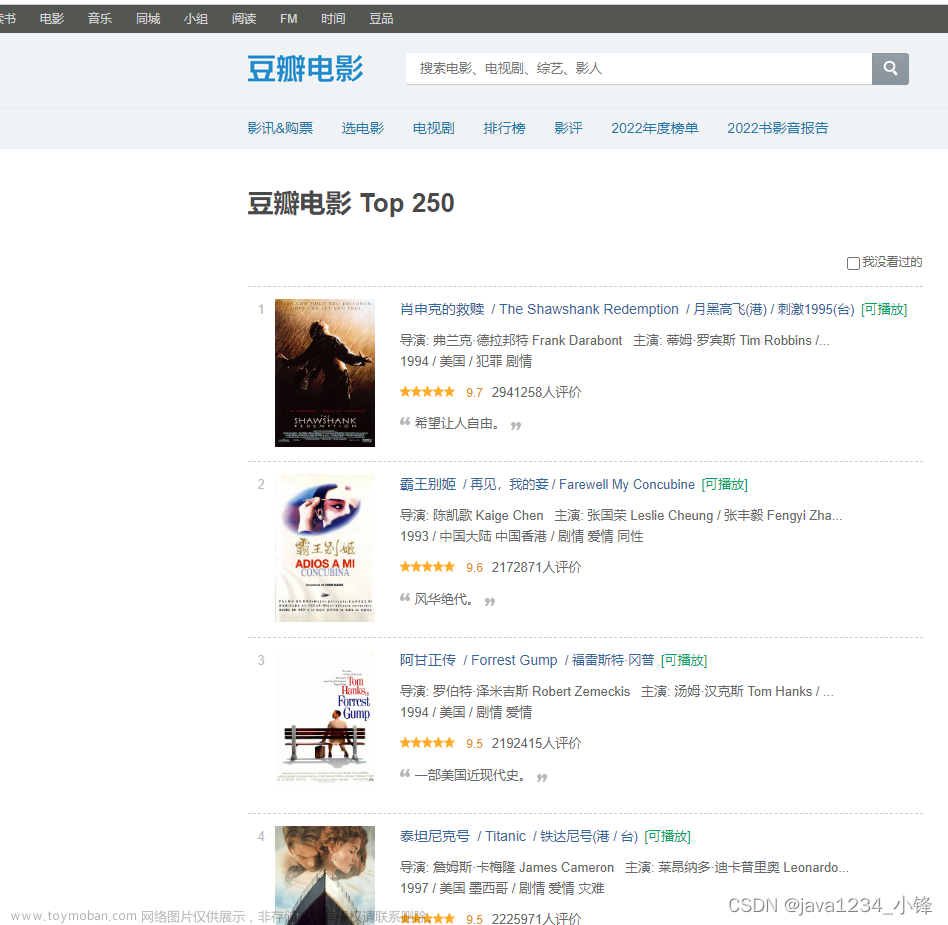
5.结果分析:
1.算法原理:
(1)利用import命令导入模块或者导入模块中的对象;
①利用requests库获取数据;
②用BeautifulSoup库将网页源代码转换成BeautifulSoup类型,以便于数据的解析和处理;
③用time库进行时间延时,避免访问速度过快被封禁(封禁后会一段时间内无法进行对网址的访问);
(2)利用resquests.get()获取的数据,其中第一个参数为网页链接,第二个参数为请求头Headers,返回的数据类型为字符串类型网页源代码;
(3)利用BeautifuSoup()命令将获取的网页源代码转化为BeautifuSoup对象,第一个参数为要解析的HTML文本,即网页源代码,第二个参数为解析HTML的解析器;
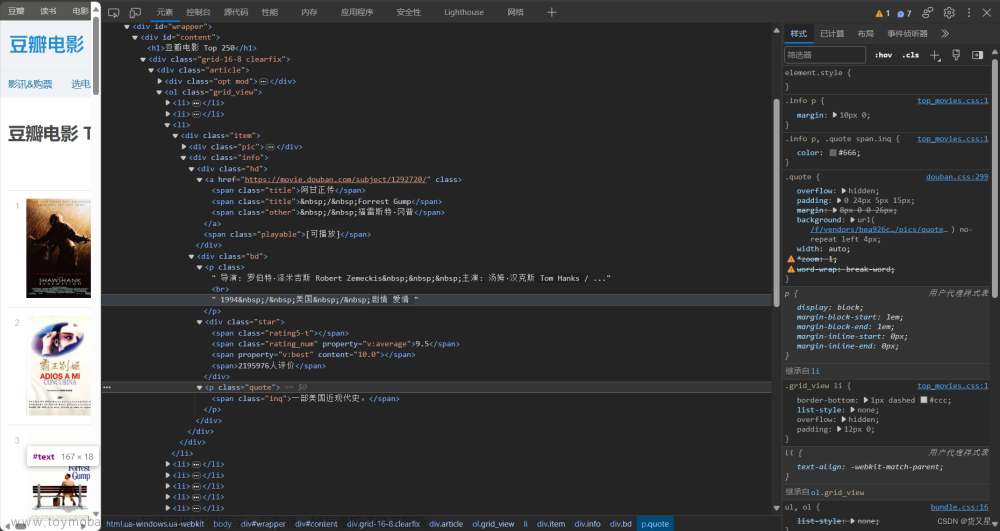
(4)利用CSS选择器,找到我们所需要的数据,在CSS选择器中,“#”表示id,“.”表示class;
(5)tag(标签)对象的常用属性/方法
| 属性/方法 | 作用 |
| tag.find() | 返回符合条件的首个数据 |
| tag.find_all() | 返回符合条件的所有数据 |
| tag.text | 获取标签的文本内容 |
| tag['属性名'] | 获取标签HTML属性的值 |
例如:
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2023/04/415693-1.png)
(6)字符串的format格式:<模板字符串>.format(<以逗号分隔的参数>),format()中参数和前面的{}顺序一 一对应例如:
print('我是{},来自{}。'.format('小浪','中国'))也可以在{}中加入序号,format()括号中类似列表进行读取,序号对应列表的下标,例如:
print('我是{1},来自{0}。'.format('中国','小浪'))也可以给占位符{}命名,例如:
print('我是{name},来自{country}。'.format(country='中国',name='小浪'))以上三种都输出:我是小浪,来自中国。
2.程序流程:
(1)利用import导入第三方库requests,time和bs4库中的BeautifulSoup;
(2)创建get_film函数,形参为变量link(用于传入网址,因为每页只有25部电影,爬取250部,每个网页链接末尾的查询字符串会有所不同)
(3)为了应对反爬虫机制,这里修改请求头,将网页中User-Agent字段定义为字典,传入requests.get()命令中,赋值给变量res(当然,也有其他的方法,比如通过别的IP访问网站,具体请自己查看requests的官方文档:https://cn.python-requests.org/zh_CN/latest/);
①: 打开豆瓣电影top250排行版,右击(以搜狗浏览器为例)--->审查元素,点击方块内图标![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2023/04/415693-2.png)
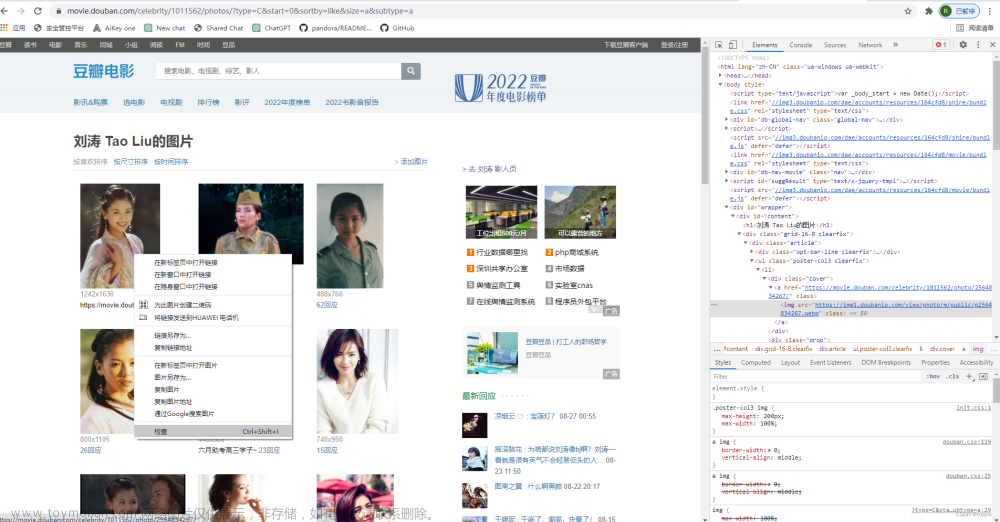
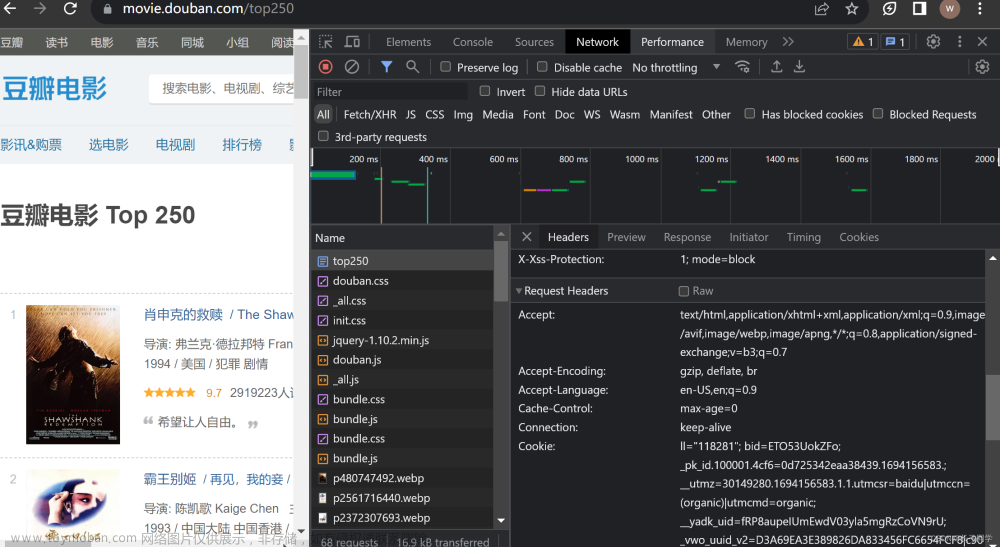
②:随便点击一个电影名,以《肖申克的救赎》为例,网页加载完毕点击Network标签,里面可能为空的,刷新一下网页就好了。点击Network——>name中第一个标签——>找到Requests Headers标签——>找到User-Agent字段。
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2023/04/415693-3.png)
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2023/04/415693-4.png)
(4)将res.text(源代码的字符串格式)传给BeautifulSoup命令,并且用Python内置的解析器html.parser,赋值给变量soup;
(5)利用CSS选择器找到标签为div,class="hd"的所有元素(随便点击一部电影名称,以《肖申克的救赎》为例,观察到的规律为电影链接、电影名分布在标签为:div,class="hd"的标签“a”中),传入soup.select()命令中,赋值给item;
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2023/04/415693-5.png)
(6)遍历item中的所有元素,观察发现链接在标签a中的href属性中,电影名在标签a中第一个标签span的文本中,此时用find命令可以找到第一个符合条件的元素,找到第一个标签其中的文本内容,并输出电影名和电影链接;
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2023/04/415693-6.png)
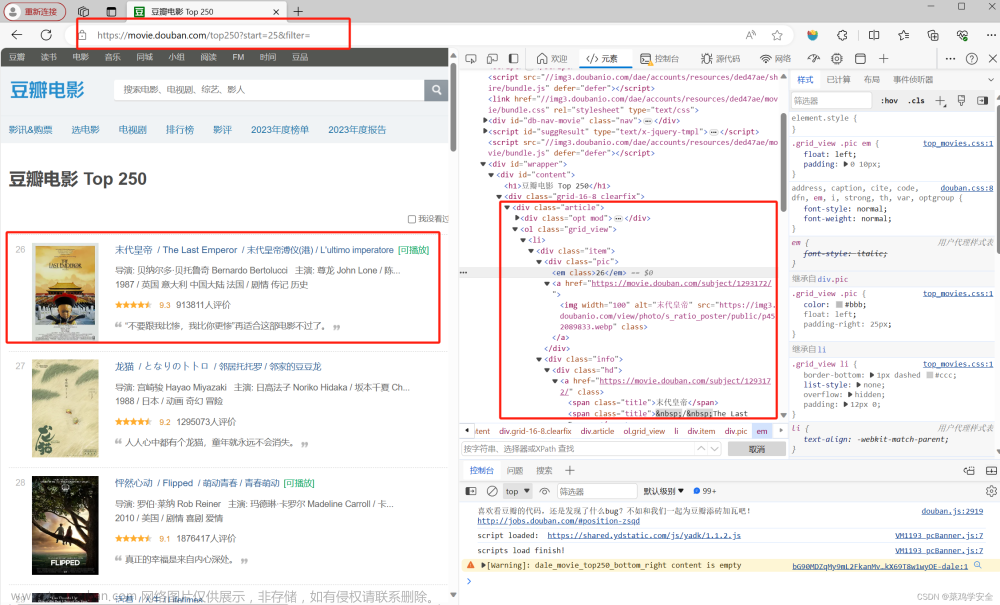
(7)观察豆瓣10页的网页链接(每页25个电影,其实就观察几页就可以发现规律):
https://movie.douban.com/top250?start=0&filter=(第一页,从一开始网页打开没有问号后的查询字符串,从其他页跳到第一页就有了,第一页带查询字符串和不带查询字符串打开内容相同)
https://movie.douban.com/top250?start=25&filter=(第二页)
https://movie.douban.com/top250?start=50&filter=(第三页)
通过以上三个网页链接的对比发现,只有start后面的发生了改变,那么就可以利用字符串的format格式,进行创建字符串列表link_all
(8)遍历10页网页,传入之前建立的函数get_film,利用time.sleep()进行延时爬取,防止访问速度过快被对方服务器封禁。
3.程序代码:
import requests
import time
from bs4 import BeautifulSoup
def get_film(link):
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0'}
res=requests.get(link,headers=headers)
soup=BeautifulSoup(res.text,'html.parser')
items=soup.select('div.hd a')
for i in items:
name=i.find('span').text
link_film=i['href']
print('电影名:',name,'网址:',link_film)
l='https://movie.douban.com/top250?start={}&filter='
link_all=[l.format(i*25) for i in range(10)]
for i in range(10):
get_film(link_all[i])
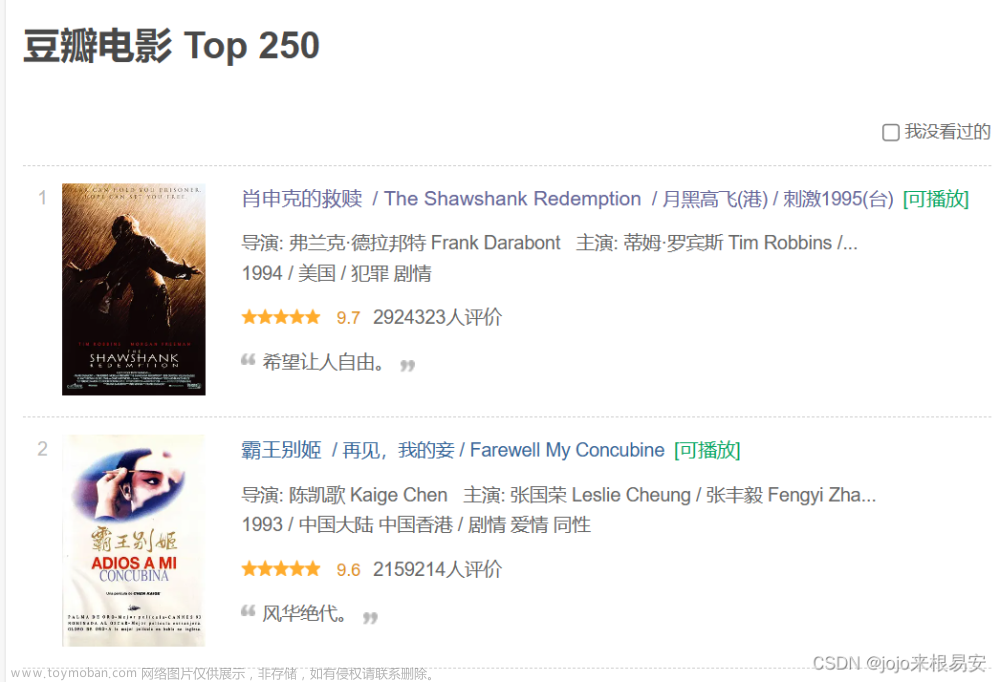
time.sleep(1)4.运行结果(部分结果展示):
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2023/04/415693-7.png) 文章来源:https://www.toymoban.com/news/detail-415693.html
文章来源:https://www.toymoban.com/news/detail-415693.html
5.结果分析:
程序获取的结果与预期结果相同,在找到电影名的过程中可以使用find和find_all命令,可以不使用CSS选择器,也可以将电影名存到txt文档,或者excel文档中,便于储存。此程序仅演示豆瓣电影名、电影网络链接,其他静态网页也可通过此方法进行爬取。文章来源地址https://www.toymoban.com/news/detail-415693.html
到了这里,关于python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码](https://imgs.yssmx.com/Uploads/2024/02/797225-1.png)