一、索引简介
1.概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
相当于是给数据库中的数据建立了一个目录,通过目录可以知道数据所在位置,然后到指定位置取出数据即可。
2.作用
大大提高数据的查询效率。
3.原理
索引其实就是针对指定字段创建的一个便于查询的数据结构,但是不同的存储引擎有不同的数据结构,本文中后续的示例采用的是MySQL数据库的innodb存储引擎。
innodb存储引擎:采用的索引结构为B+树。
简介B树与B+树的区别:
B树每个节点都存储了数据,通过索引找到了节点,就直接找到了数据。
B+树针对索引字段建立数据结构,每个节点中并不存储数据,而是保存数据在磁盘中的地址,数据在磁盘中是连续存储的。
为什么B+树中索引和数据分离存储,索引中存储的是数据的地址?
在一次磁盘IO中,可以读取更多的索引数据,在检索索引时可以减少IO次数。
二、聚簇索引和非聚簇索引
1. 聚簇索引
(1)通常是针对主键建立主键索引,且一张表中只能有一个主键索引,其他索引都是普通(辅助)索引。
(2)主键索引和数据在磁盘中都是顺序存储的,且索引顺序与数据的实际存储顺序保持一致。
(3)辅助索引是针对主键值做的索引。即辅助索引节点存储的是主键索引字段的值,相当于是先通过辅助索引,找到主键索引值,再通过主键索引值,在主键索引中查找数据存储位置。
2.非聚簇索引
(1)主键索引和普通(辅助)索引没有太大区别,节点中都是保存数据的存储地址。
(2)索引和数据的实际存储顺序不一定保持一致,即数据在磁盘中不一定是按序存储的。
3.区别与联系
联系:聚簇与非聚簇索引都是采用B+树来构建索引。
区别:在构建索引时的思想不同。
4.适用场景
4.1聚簇索引
(1)优点
索引和数据都是按序存储,因此在范围查询上效率更高,因为查找到一个数据后可以连续取出。
例如:查询某个字段大于5的数据,找到第一个大于5的数据后,就可以直接往后连续取出即可。
(2)缺陷
①在中间插入数据时,为了保持顺序存储,需要重新调整索引和数据的存储顺序。
②普通索引查询时,需要通过主键索引值在主键索引中进行二次查询。
(3)避免中间插入方法
因此聚簇索引通常都是针对具有自增属性的主键id创建,这样就可以尽可能的避免中间插入。
4.2非聚簇索引
(1)优点
①普通索引查询效果也很好,不需要二次检索索引。
②在中间插入和删除数据影响不大,不需要调整数据的存储位置,只需要调整索引即可。
(2)缺陷
范围查找效率不如聚簇索引:因为数据不一定按序存储,每次都需要通过索引去重新获取下一条数据的存储位置。
5.MySQL数据索引类型
(1)Innodb存储引擎:聚簇索引。
(2)MyISAM存储引擎:非聚簇索引。
三、索引操作
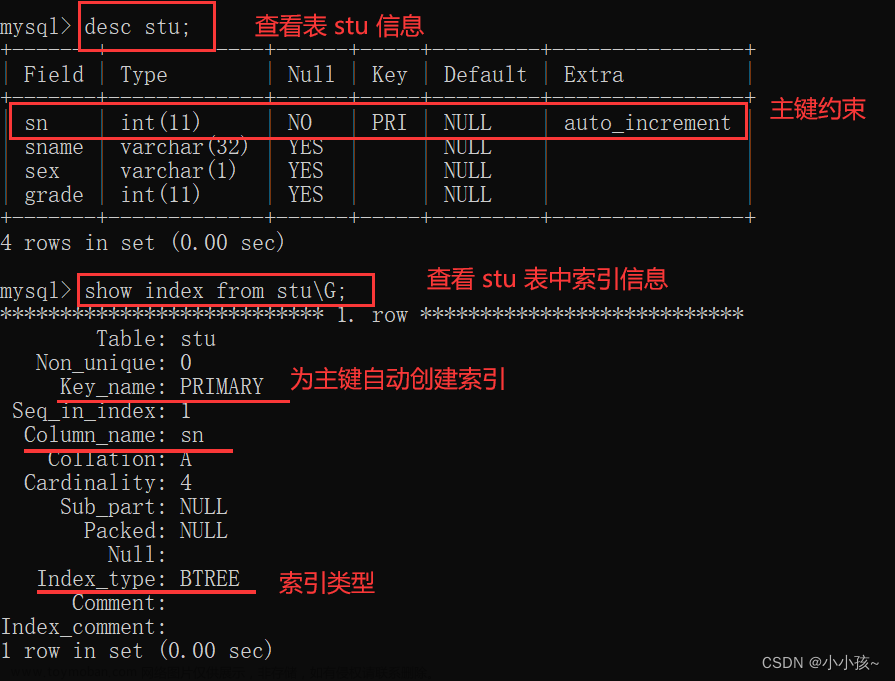
1.查看索引
(1)show keys from 表名;
(2)show index from 表名;

(3)desc 表名

2.创建索引
2.1自动创建
MySQL数据库会自动对主键、唯一键、外键字段创建索引。
2.2普通索引创建
(1)在表的定义最后指定某列为索引
create table user(id int primary key, name varchar(10), sex varchar(2), index(name));

(2) 创建完表后,指定某列为普通索引
alter table user add index(sex);

(3)为某张表的某个字段创建索引
create index 索引名 on 表名(字段名);

3. 删除索引
(1)删除主键索引
alter table 表名 drop primary key;
(2)删除其他索引
alter table 表名 drop index 索引名;
索引名:show keys from 表名;结果中的Key_name字段。

(3)drop index 索引名 on 表名;

四、索引创建原则
1.创建原则
(1)经常作为查询条件的字段适合创建索引。
(2)唯一性差的字段不适合单独创建索引,即使频繁作为查询条件。
(3)更新比较频繁的字段,不适合创建索引。
2.索引不是越多越好
(1)索引会单独建立一张表,占据额外的磁盘空间。文章来源:https://www.toymoban.com/news/detail-415927.html
(2)索引可以提高查询效率,但是会增加增删改的时间成本。文章来源地址https://www.toymoban.com/news/detail-415927.html
到了这里,关于MySQL数据库:索引的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!