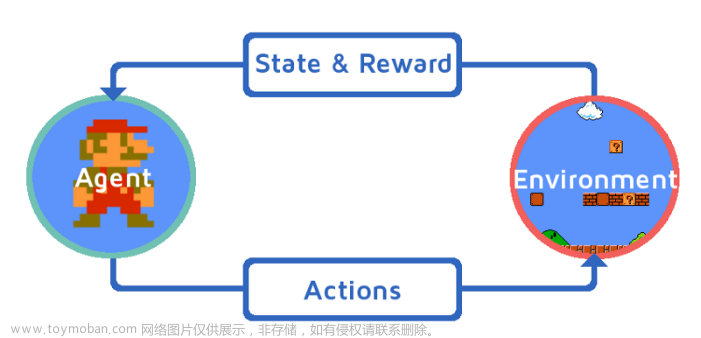
文献 [1] 采用deep reinforcement learning和potential game研究vehicular edge computing场景下的任务卸载和资源优化分配策略
文献[2] 采用potential game设计车载边缘计算信道分配方法。
Exact potential game介绍
Exact potential game(简称EPG)是一个多人博弈理论中的概念。在EPG中,每个玩家的策略选择会影响到博弈的全局效用函数值,而且博弈的全局效用函数值可以表示为各个玩家效用函数的加和。此外,对于任意一位玩家而言,其任意两个策略选择下的效用差值可以表示为另外一位玩家某个特定策略选择下的效用差值的加和。这个特殊的性质被称为精确潜势作用(exact potential function),因此这种博弈被称为精确潜势博弈。
EPG在博弈理论和应用中有广泛的应用,例如交通流量、能源市场和通信网络中的资源分配问题等。因为它具有特殊的性质,即每个玩家的策略选择可以通过求解一个单独的优化问题来实现全局最优解。因此,EPG具有很好的可解性和收敛性。
Exact potential game证明
要证明一个精确潜势博弈存在纳什均衡点,可以通过以下步骤进行:
- 定义博弈的玩家集合和每个玩家的策略集合。
- 定义博弈的全局效用函数,使其能够表示为各个玩家效用函数的加和。
- 针对任意一位玩家,证明其效用函数满足精确潜势作用的性质,即任意两个策略选择下的效用差值可以表示为另外一位玩家某个特定策略选择下的效用差值的加和。
- 利用精确潜势作用的性质,构造一个最小化全局效用函数的优化问题,该问题的解即为精确潜势博弈的纳什均衡点。
- 证明该优化问题满足凸性和紧致性条件,从而保证优化问题有解。
以下是一个简单的例子来证明精确潜势博弈的存在性和可解性:
考虑一个由两个玩家A和B组成的博弈,每个玩家都有两个策略可以选择:策略1和策略2。其效用函数如下所示:
- 玩家A的效用函数:如果A选择策略1,则其效用为0;如果A选择策略2,则其效用为1,除非B也选择了策略2,则A的效用为2。
- 玩家B的效用函数:如果B选择策略1,则其效用为0;如果B选择策略2,则其效用为1,除非A也选择了策略2,则B的效用为2。
博弈的全局效用函数为各个玩家效用函数的加和。
接下来,我们验证该博弈是否是一个精确潜势博弈。对于玩家A而言,考虑其两个策略选择下的效用差值:若A选择策略1,则其效用差为0;若A选择策略2,则其效用差为1或2,取决于B的策略选择。如果B选择了策略1,则A的效用差为1;如果B选择了策略2,则A的效用差为2。因此,我们可以将A的效用差表示为B选择策略1时的效用差加上B选择策略2时的效用差,即A的效用差值满足精确潜势作用的性质。
同样地,对于玩家B而言,也可以验证其效用差值满足精确潜。
考虑一个具有三个玩家的EPG,其中每个玩家的策略集合为{a,b,c}。每个玩家的效用函数如下所示:
- 玩家1:u1(a,b,c) = (a-b)^2 + (a-c)^2
- 玩家2:u2(a,b,c) = (b-a)^2 + (b-c)^2
- 玩家3:u3(a,b,c) = (c-a)^2 + (c-b)^2
可以验证,此EPG具有精确潜势作用的性质。为了找到纳什均衡点,需要构造一个优化问题,使得每个玩家的策略选择都是其效用函数的最小值。由于该EPG具有精确潜势作用的性质,这个优化问题可以表示为:
min (a-b)^2 + (a-c)^2 + (b-a)^2 + (b-c)^2 + (c-a)^2 + (c-b)^2
对于此问题,其最小值可以通过求解每个变量的一阶导数为0的方程组得到。解得a=b=c,即所有玩家选择同一策略的情况为纳什均衡点。因此,此EPG存在纳什均衡点,并且其纳什均衡点是全局最优解。
参考文献:
[1] Xu X, Liu K, Dai P, et al. Joint task offloading and resource optimization in NOMA-based vehicular edge computing: A game-theoretic DRL approach[J]. Journal of Systems Architecture, 2023, 134: 102780.(附有代码:https://github.com/neardws/Game-Theoretic-Deep-Reinforcement-Learning)文章来源:https://www.toymoban.com/news/detail-416164.html
[2] 许新操, 刘凯, 刘春晖, 等. 基于势博弈的车载边缘计算信道分配方法[J]. 电子学报, 2021, 49(5): 851.(附有代码:GitHub - neardws/Incentive-based-Probability-Update-and-Strategy-Selection: Code of Paper "Potential Game Based Channel Allocation for Vehicular Edge Computing (基于势博弈的车载边缘计算信道分配方法)", 电子学报2021.)文章来源地址https://www.toymoban.com/news/detail-416164.html
到了这里,关于Deep Reinforcement Learning + Potential Game + Vehicular Edge Computing的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!