前言
GDB全称GNU symbolic debugger,它是诞生于GNU开源组织的(同时诞生的还有 GCC、Emacs 等)UNIX及UNIX-like下的调试工具,是Linux下最常用的程序调试器,GDB 支持调试多种编程语言编写的程序,包括C、C++、Go、Objective-C、OpenCL、Ada 等。但是在实际应用中,GDB 更常用来调试C和C++程序。虽然说在Linux系统下我们可以借助诸多集成开发工具来完成程序的编写和调试,但实际上,调试C/C++程序一定是直接或者间接使用GDB完成的。所以说GDB调试几乎可以说是Linux程序员必备的基本技能。本文将手把手教你使用GDB调试程序,并带你深入了解什么是GDB调试器。
一、什么是GDB
1. 为什么要有GDB
我们在开发程序的过程中,应该很少会有一次就编译通过的吧,有时候即便是写了短短几十行的代码,都难免会有一些小的疏忽,更何况是几千上万甚至更大的代码,反正我在开发中几乎每次写完程序都会经过反复的调试,键盘的F11键经常会坏掉。在程序中,出现的错误主要分为 2大 类,即语法错误和逻辑错误:
- 语法错误,顾名思义就是不符合编程语言语法的错误,这类错误一般都可以由编译器诊断出来,GCC编译器的编译阶段会进行语法检查(这方面内容我在GCC编译器那篇文章中已经详细介绍过了);
- 逻辑错误,这部分错误是指我们在程序设计的逻辑上的错误,程序编译通过,但是执行结果并不符合我们的预期,这类错误就没有办法依靠GCC编译器去检查了,需要我们自己调试分析;
程序出现语法错误,可以依靠GCC检查出来,而逻辑错误就要我们今天的主角GDB登场解决了。所谓调试(Debug),就是单步执行代码,或通过断点让程序执行到某个位置,以此来逐步锁定程序出现问题的范围。在单步调试的过程中,我们可以监控程序执行的每一个行为,包括变量值的变化、函数的调用、内存中数据的变化、线程的调度等等,以此来修复BUG或者优化代码。
我们在Windows下开发最常用的Visual Studio,它自带的调试器是Remote Debugger,调试器与整个IDE无缝衔接,使用非常方便。在Linux下C/C++必备的调试器就是GDB了,下面讲解如何查看GDB版本及安装GDB。
2. 下载安装GDB
(1)查看GDB版本
gdb -v
gdb --version
如果你的执行结果如下,说明已经安装好了gdb,版本号如下,一般我们装好Linux后可以通过这个命令来测试是否已经安装gdb调试器。
如果你的运行结果显示 not found ,说明未安装gdb调试器,安装gdb的方法主要有两个,下面一节介绍安装方法。
bash: gdb: command not found
(2)安装GDB调试器
安装gdb主要有两种方法:
① 直接安装。通常我们安装好Linux之后,操作系统内会附带有gdb的安装包,我们可以直接使用操作系统内已有的gdb安装包,使用包管理器进行安装。这种方法简单有效,只需要一条命令就可以安装成功(以CentOS为例)
yum -y install gdb
安装好后,可以通过 gdb -v 查看版本,一般来说通过这种方式安装的gdb都不是最新版本,并且无法自己选择版本。
② 通过源码安装。源码安装是指首先去网上下载源码压缩包,然后在本地解压安装,我们可以选择自己需要的版本进行安装,可以直接点击源码包的链接gdb源码去下载。
里面有很多版本和格式,我们可以选择一个自己需要的版本 .tar.gz 格式下载,下载后进行下面的操作,比如说我下载最新的版本gdb-11.2.tar.gz。(通过源码安装文件以及 tar 压缩包管理命令可以查看我的文章《【Linux王者之路基础篇:基本命令与基础知识】Linux常用shell命令(及相关知识)详解与用法演示》第六章节《六、压缩文件管理相关命令》有详细介绍)
- 解压文件
找到下载好的压缩包并解压
tar -zxvf gdb-11.2.tar.gz
如果你是在Windows下下载好的压缩包,要传到Linux下,可以借助SecureCRT的rz命令,教程请见《【Linux开发环境搭建:工具篇】SecureCRT工具连接虚拟机、rz/sz传输、中文乱码问题解决》。
我下载的太慢了,半小时才下载三分之一,所以后面就只说命令了。
- 解压后进入解压出来的目录
- 运行 configure 文件配置环境,这时候会创建一个Makefile文件
- make 编译源码文件
- 安装 make install
- gdb -v 查看
tar -zxvf gdb-11.2.tar.gz
cd gdb-11.2
./configure
make
make install
gdb -v
(3)卸载GDB
gdb调试器的卸载命令
yum remove gdb
二、GDB的启动与调试程序的上下文设置
1. 准备知识
(1)测试程序中的main函数参数解析argc与argv[]
首先我们创建一个C文件gdb_test.c,以用于后面举例使用,程序如下
#include <stdio.h>
#include <stdlib.h>
struct st
{
int a;
int b;
};
void print_array(char* array, int len)
{
int i = 0;
for(i = 0; i < len; i++)
{
printf("array[%d]: %c\n", i, array[i]);
}
}
int main(int argc, char* argv[])
{
struct st st_temp;
int i = 0;
char array[5];
st_temp.a = 10;
st_temp.b = 11;
for(i = 0; i < 5; i++)
{
array[i] = i + '0';
}
print_array(array, 5);
for(i = 0; i < argc; i++)
{
printf("hello...argv[%d]: %s\n", i, argv[i]);
}
return 0;
}
在这个测试程序中,main函数貌似有点不同寻常啊
int main(int argc, char* argv[])
多了两个东西,argc和argv,其实在main函数中本就应该有这两个参数,只不过在我们平常的大部分学习中,都弱化了这两个参数的作用,估计大部分人在学习编程时都从来没有写过这两个参数。第一个参数argc用来统计程序运行时传递给main函数的命令行参数的个数,这个不需要我们设置;argv是一个字符串数组,用来存放我们传入的参数,其中argv[0]默认就是程序运行的路径名。说起来不好理解,我们举个例子,就用上面给出的gdb_test.c文件,我们编译好运行一下,并传递参数
gcc gdb_test.c -o g3
./g3 111111

首先可以看到argc的值是2,argv的第一个参数是 ./g3 表示当前目录,第二个参数是我们传入的111111。如果我们不传任何参数,argc就是1,argv只有一个字符串就是当前路径。
(2)gcc编译时 -g 选项帮我们做了什么?
gdb主要的作用是跟踪程序的执行过程,所以要想用gdb调试程序,首先要把源程序编译为可执行文件。但是,我们正常使用gcc命令编译出来的可执行文件是无法通过gdb调试的,因为这样编译出来的可执行文件缺少gdb调试所需要的调试信息(比如每一行代码的行号、包含程序中所有符号的符号表等信息)。要想生成带有gdb调试信息的可执行文件,就要在gcc编译的时候添加==-g== 选项。
你可能通过尝试后会说,不加gcc的 -g 选项也能进入gdb调试,确实是这样,但是进入gdb并不代表就可以调试,比如下面
我们不加 -g 编译一个源文件,并启动gdb
进入gdb后我们发现,使用 r 命令执行可以,但是通过 list 查看源代码却不行。这是因为,我们不加 -g 编译出来的可执行文件不包含行号和符号表等调试所需要的信息,所以你想查看源码、添加断点都是无法实现的。而这就是 -g 选项的作用,我们可以对比一下加与不加 -g 选项生成的可执行文件大小
能够看得出,加了 -g 选项后编译出来的可执行文件占据了更多个空间,这是因为,它包含了调试信息。
有时候,我们在编译时会组合 -g 和 -O 来使用,通常用 -Og 来实现在保证快速编译和更好的调试前提下,进行一定的优化。
(3)启动GDB与指定目标调试程序的方式
启动gdb调试器分为四种情况:
① 调试非运行状态且编译通过可运行的可执行文件
gdb exe(可执行文件名)
gdb ./exe(可执行文件名)
② 调试正在运行的可执行文件
gdb -p pid(进程号)
③ 调试core
gdb exe(可执行文件名) core.19761(core文件名)
gdb ./exe(可执行文件名) core.19761(core文件名)
上面这三种情况会在后面对应的章节详细介绍。
④ 假如直接使用 gdb 命令进入gdb调试器,gdb自己是无法确定要调试哪个可执行文件的,即使当前目录只有一个可执行文件也无法自动识别,这时我们可以手动指定目标调试文件。
提示信息中已经告诉我们使用哪个命令来指定待调试程序了,那就是 file 命令,使用方法是 file 直接加可执行文件所在目录以及可执行文件名,如果可执行文件就在gdb当前工作目录下,可以不加目录,这样我们就可以使用gdb调试 file 命令指定的可执行文件了
不管哪种情况,我们进入gdb时,总会打印一堆声明
要想去掉这些声明,可以在gdb后面加 –silent 或 -q 或 –quiet 选项。
只要最下面有一个 (gdb) 就说明进入成功。
2. 程序上下文
(1)gdb工作目录
默认情况下,GDB调试器会把启动时所在的目录作为工作目录,但有时候我们可能需要根据情况去改变gdb的工作目录,查看gdb当前工作目录和改变工作目录的命令和 shell 下一样。
① 查看当前gdb工作目录
pwd 命令可以查看当前gdb工作目录
② 改变gdb工作目录
使用shell下的 cd 命令,可以改变gdb工作目录,用法与shell下一样
另外提示一下,gdb调试时,也可以使用 tab 键命令补全、上下键查看历史命令等。
(2)程序运行参数
传递运行参数的方式有三种:
① 启动gdb时指定(exe表示可执行文件名,paras表示参数)
gdb --args exe paras
我们用前面的gdb_test.c编译为g3,并传入参数111111111
② set命令
gdb调试器启动后,在运行过程中,可以借助 set 命令指定目标调试程序启动所需要的运行参数
set paras
我们在函数print_array()处设置一个断点,并执行到断点处,然后把函数参数len设置为2,也就是只打印两个数据(array总共5个数据,可以看前面的图中打印结果)
可以看到 set 在运行的过程中改变了参数len的值。
③ 运行时指定
gdb调试器启动后,在运行时可以通过run 和 start 来指定参数
run paras
start paras

(3)查看及修改运行环境
① 查看程序的运行路径
show paths
② 设置程序的运行路径
path /xxx/xxx/
③ 查看环境变量
show environment
④ 设置环境变量
set environment PARA=para
(4)输入输出重定向
① 输入输出重定向
默认情况下,程序中的输出都是打印在终端上的,通过重定向可以把结果打印到指定位置。比如,我们可以把程序中的打印结果都打印到某个文件中
可以看到,运行程序后,屏幕上没有任何输出,我们退出gdb查看1.txt文件
程序运行结果都被打印到了该文件中。
② 选择终端
使用终端tty1,命令如下
tty /dev/tty1
三、GDB实战讲解
1. GDB命令详解
在下面所有的命令标题中,括号内为命令全写,括号外为命令缩写,使用效果一样,例如运行命令 r(run),下面两种用法效果一致
(gdb)r
(gdb)run
下面的例子都是用前面编译好的文件 gdb_test.c 及可执行文件 g3。
(1)r(run)运行与start运行程序
run 运行程序,如果有断点则停在断点处,如果没有断点会一直执行到程序结束。start 会执行到main函数的起始位置,相当于在main()加一个断点,然后使用 run 执行。如果在程序调试或者执行中使用 run 或 start 都代表从头开始重新执行程序。
在 r 或 start 命令后面加参数可以把参数传入并执行(前面已经介绍过了)
(gdb)r para
传入参数para并执行。
start 会执行到 mian 处。
(2)q(quit)退出调试
退出 gdb 调试,回到 shell。
(3)help
查看帮助手册,按 q 退出帮助手册。
(4)l(lsit)查看代码
① 一次显示10行
② 指定一个行号n,查看 n-5 到 n+4 行(共10行)
③ 查看第 n1 到 n2 行代码 list n1,n2
④ 查看其他文件代码,用于包含多个源文件的情况,比如可执行文件 test 由 test1.c 和 test2.c 编译而成,可以通过指定文件名来查看 test1.c 或 test2.c 的源代码。
查看 test1.c 的代码1到10行
(gdb)list test1.c:1,10
(5)set 传入参数
① set 可以传入参数或者修改变量的值
② 变量名与gdb命令名冲突
比如你在源代码中有一个变量名叫 width ,如果你要用 set 设置这个变量的值会产生冲突,因为 set width 是gdb的命令,这时可以通过 set var 告诉gdb该变量是用户变量。建议自己写代码时要避免和系统函数、编译调试等命令重名的函数或变量,以避免不必要的麻烦。
(gdb)set var width=10
③ 设置命令
比如说我们在打印结构体的时候,使用 p 命令默认就是普通的打印,可能不是很美观,我们可以通过命令使打印出来的结构体更符合我们观看的习惯
(gdb)set print pretty

(6)n(next)执行下一条语句,不进入函数内部
单步执行代码,一条语句一条语句的执行,如果遇到函数不会进入函数内部,可以理解为VS的 F10 调试键。也可以在后面加数字表示执行多少行
(gdb)n num

(7)s(step)执行下一条语句,且进入函数内部
用法基本与 next 相同,区别在于 step 在遇到函数的时候会进入函数内部(像 printf 等这种库函数不会进入),可以理解为VS的 F11 调试键。
可以看到,当执行到我们自己的函数 print_array() 的时候,按 step 会进入这个函数的内部,停在这个函数内部语句的第一行。同样,step 也可以在后面加数字表示一次执行多少行。
(8)u(until)
① 跳出循环体
在遇到循环体时,如果在循环体尾部(最后一行代码)按 until 调试键,会直接执行完整个循环体,并停在循环体外。
② 跳转至某一行
(gdb)until num
直接跳至第 num 行执行并停在这一行。
③ 在其他时候,功能和 next 一样,都是单步执行。
(9)b(break)设置断点以及打断点的六种方式
断点(BreakPoint),可以让程序执行到断点处并停在这里,加断点应该是调试的时候最常用的一种方法,就像VS中的 F9 键。加断点的方式有很多种,下面将逐一介绍:
① b function (直接加函数名)在某个函数 function 处添加断点
在函数 print_array() 处加断点并执行,会停在该函数内部的第一行
② b num (直接加行号)在第num行添加断点
这里有一点要注意,因为程序已经启动了,如果我们要想执行到断点处,应该使用命令 c ,如果使用 run 或 start 会重新运行程序。
③ b file.c:num 在 file.c 文件的第 num 行加断点,如果不加文件名 file.c 则默认是在含main函数的那个文件第 num 行加断点。
④ b file.c:function 在 file.c 文件中名为 function 的函数处加断点。
⑤ b ±num 通过偏移地址设置断点,+ 表示从当前程序运行行开始,往下数 num 行并设置断点;- 表示当前程序运行行开始,往上数 num 行并设置断点。
举例,当前程序在第34行,通过 b +12可以把程序打在 34+12=16 行处。
⑥ b (上面五种方式指定断点位置) if expression 当满足表达式 expression 的时候打断点,也就是说只有当这个表达式为真的时候,这个断点才会生效。
使用举例:
(gdb)b 12 if i==2 当i==2的时候在第12行加断点
(gdb)b func if i>3 当i>3的时候在函数func处加断点
(10)tbreak
命令的格式与用法与 break 相同,但是设置的断点只生效一次,该断点使用一次后自动去除。
(11)rbreak
该命令用于给函数加断点, rbreak regex 给所有满足表达式 REGEX 的函数加断点,设置的断点和 break 设置的断点一样。这个命令在C++调试的时候,用于给所有重载函数加断点非常方便。也可以加文件名来限制为哪个文件中的所有满足表达式的函数加断点 rbreak file.c:regex 。
(12)disable 与 enable
用于禁用和激活断点(普通断点、捕捉点、观察点、display的变量),通过断点号来指定要禁用或激活的断点(通过 info 查看断点号),可以通过 help 手册查看用法,被 disable 禁用的断点将会暂时失效,使用 enable 激活后会再度恢复正常使用。
enable 可以激活多个断点,并且可以指点被激活的断点起作用的次数。
举个小例子
可以看到,Enb 那一栏从 yes 变成了 no。
(13)watch
设置观察点,如果在执行过程中变量发生变化,就把他打印出来,并停止运行。
这里要注意,如果你用指针(或地址)来设置观察点,一定要解引用,* 指针才是对指针所指向的变量进行观察如果不解引用,那就是对指针变量本身(地址)进行观察。另外,如果你观察一个临时变量或表达式,当它的生命周期结束的时候,对应的观察点也就失效了。
观察点有软件观察点和硬件观察点,这里不再详细介绍。
(14)rwatch
只要程序中出现读取目标变量或表达式的值的操作,程序就会停止运行。(读)
(15)awatch
只要程序中出现读取目标变量或表达式的值或者改变值的操作,程序就会停止运行。(读写)
(16)catch
(gdb)catch enevt 监控某一事件 event 的发生,当事件发生时,程序停止
这个 event 可以是下面的情况:
① C++中 throw 抛出的异常或 catch 捕捉到的异常;
② load 命令或 unload 命令,在动态库加载或卸载时程序停止执行;
③ fork、vfork、exec 系统调用时,程序停止运行;
举个例子测试一下,先准备一个C++源文件,并编译生成带调试信息的可执行文件 test。
进入调试,设置捕捉点,捕捉 string 类型的异常
(17)c(continue)执行到下一个断点处
继续执行程序,一直执行到下一个断点处。
(18)info 查看
① info breakpoints 查看所有断点的信息
- Num:断点编号
- Type:断点类型
- Enb:激活状态,y表示已激活,n表示未激活
② info breakpoints num 查询 num 号断点的信息
③ info variables 查询当前全局变量信息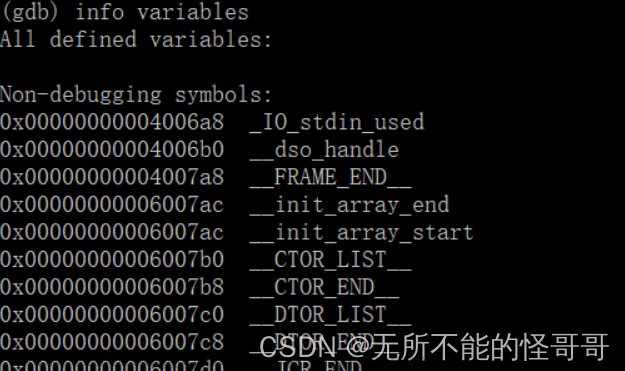
④ info watchpoints 查看观察点信息
⑤ 查看寄存器 ⑥ 查看当前函数内部临时变量的值
⑥ 查看当前函数内部临时变量的值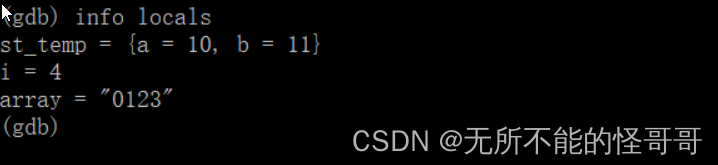
⑦ 查看当前函数参数的值
⑧ 更多用法,请查看帮助手册

(19)del(delete)删除
如果我们使用 quit 退出调试,然后再次启动 gdb 的话,之前设置的所有类型的断点(包括观察点、捕捉点)都会消失。通过 delete 可以在当前调试中删除断点。在使用 delete 删除断点的时候,要先用 info 命令查看断点信息,在显示信息的第一列会有断点的编号,然后再根据编号删除断点即可。(删除观察点、捕捉点方法与删除断点一致)
如果直接使用 delete 命令,不加断点号的话,会删除当前所有断点。
(20)clear
删除断点,后面加行号或函数名,(delete是按照断点号删除)
(gdb)clear func 删除函数 func 处的断点
(gdb)clear num 删除第 num 行的断点
(21)ignore
忽视断点
(gdb)ignore num count 忽视编号为 num 的断点 count 次
(22)p (print)
① 打印变量的值
(gdb)p val 打印变量 val 的值
(gdb)p &val 打印变量 val 的地址

array 类型为 char ,地址每次+1增长1个字节。
② 指定打印变量值的进制,比如 /x 表示按16进制打印
进制表如下:
| 命令 | 进制 |
|---|---|
| /t | 二进制 |
| /d | 十进制有符号 |
| /u | 十进制无符号数 |
| /x | 十六进制 |
| /o | 八进制 |
| /f | 浮点型 |
| /c | 字符型 |
其实和我们在C语言中的语法是一样的。
③ 打印表达式结果
④ 修改变量的值
(23)ptype 查看类型
查看一个变量的数据类型
(24)display 跟踪变化
查看某个变量或表达式的值,和 p 命令类似,但是 display 会一直跟踪这个变量或表达式值得变化,每执行一条语句都会打印一次变量或表达式的值。
display 也可以按格式打印,语法和 print 一样,请参照上表(print)。
display 跟踪得变量或表达式也会放入一张表中,使用 info 命令可以查看信息
同样,Num表示编号,Enb表示是否激活,Expression表示被跟踪的表达式。
(25)undisplay 取消跟踪
后面加 Num 编号,删除取消跟踪。其实也可以使用 del 删除。
(26)bt (backtrace)查看栈信息
在一个程序的执行过程中,如果遇到函数调用,会产生一系列一些与函数上下文相关的信息:比如函数调用的位置、函数参数、函数内部的临时变量等。这些信息会被存放在一块称为栈帧的内存空间中,并且每一个函数调用都对应一个栈帧(main 函数也有自己的栈帧,称为初始帧)。这些所有的栈帧都存放在内存中的栈区。通过命令 info frame 可以查看当前使用的栈帧所存储的信息,这里面包含了栈帧编号、栈帧地址、调用者、源码编程语言等信息。通过命令 frame num 、up 、down 可以选的改变栈帧。
查看当前所有栈帧 bt
(27)x 查看内存

同样可以指定按什么格式查看。
(28)disas 反汇编
查看函数 print_array() 的反汇编代码,使用命令 q 退出。
(29)finish
跳出当前所在的函数。
(30)return
忽略后面的语句,立即返回,可以指定返回值 return -1 。
(31)call
调用某个函数,call func() 调用 func() 函数。
(32)edit
进入编辑模式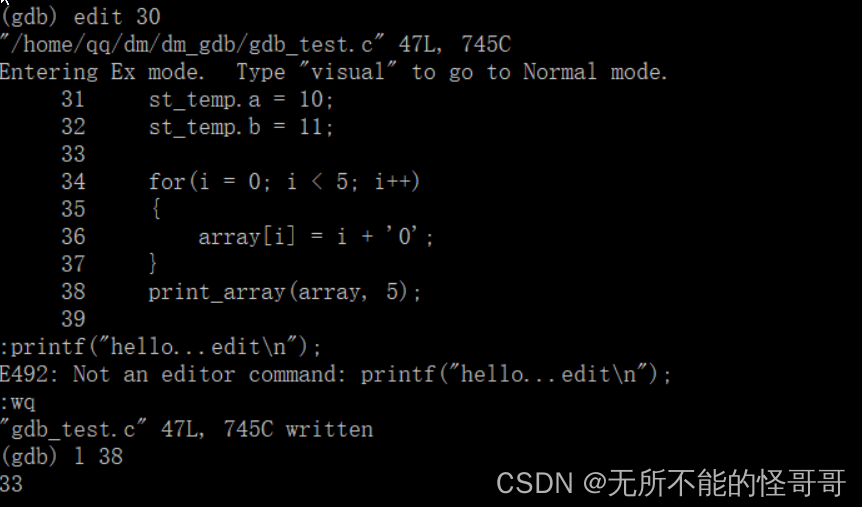
(33)search
search 搜索,reverse-search 反向搜索。
2. GDB跟踪可以正常编译运行的源文件
(1)调试非运行状态的可执行程序
这个很简单,我们前面介绍命令时,所举的例子,都是在这种情况下进行的。也就是对编译好的可执行文件进行调试。
进入gdb调试,然后用上面介绍的命令进行调试即可。
(2)调试一个正在运行的程序
有时候我们运行一个一直执行的程序时,希望能够调试这个程序。比如某个带有无限循环打印某些信息的程序。
我们可以这么做,首先编译生成可执行文件,然后在运行时加 & 让进程转为后台执行,或者通过 SecureCRT 克隆会话来新打开一个会话进行调试。
① 首先通过 ps 命令查看进程号,找到 loop 进程的进程信息
② 通过gdb的 -p 参数,指定进程进入调试
③ 正在运行的程序会暂停,可以正常调试了
3. GDB跟踪core(调试挂掉的程序)
(1)什么是 core dump 核心转储
core是指core memory,dump即堆放。core dump就是核心转储的意思。在Unix系统中,经常会将主内存 main memory 称为核心 core,而核心映像 core image 是指进程执行时的内存状态。当程序发生错误或者异常或者收到某些信号而终止执行的时候,操作系统会把核心映像写入一个文件(core 文件)来作为调试依据,这就是核心转储 core dump。
换句话说,当我们写的程序在运行时发生异常而退出的时候,由操作系统把程序当前的内存状况存储在一个core文件中,这就叫core dump。也就是说,所谓core dump核心转储,就是当我们写的程序当掉(异常退出)时,把程序当前的内存状况存储起来,以作为调试的参考的这么一种技术。
(2)产生 core dump 的原因
主要原因可以分为三大类:
① 访问越界
包括数组下标越界,C语言字符串无结束符引起的越界,使用非法指针(空指针NULL、野指针、未初始化的指针、越界指针)等。
② 多线程
多线程访问全局变量未加同步机制(锁机制等),或使用了线程不安全的函数。
③ 堆栈溢出
使用了太大的局部变量或无限嵌套、递归调用函数,可能会造成栈溢出。
(3)core 文件的相关配置与 shell 资源限制
我们先准备一个有问题的程序
编译并运行这个程序,程序发生 core dump,但是我们并没有找到 core 文件
这是因为,默认情况下 core 文件被 shell 限制大小为0了,所以我们看不到 core 文件,可以通过 ulimit 命令查看限制
实际上,ulimit 是 shell 的一个命令,通过这个命令可以查看 shell 对各种资源的限制,比如 -a 选项可以查看所有限制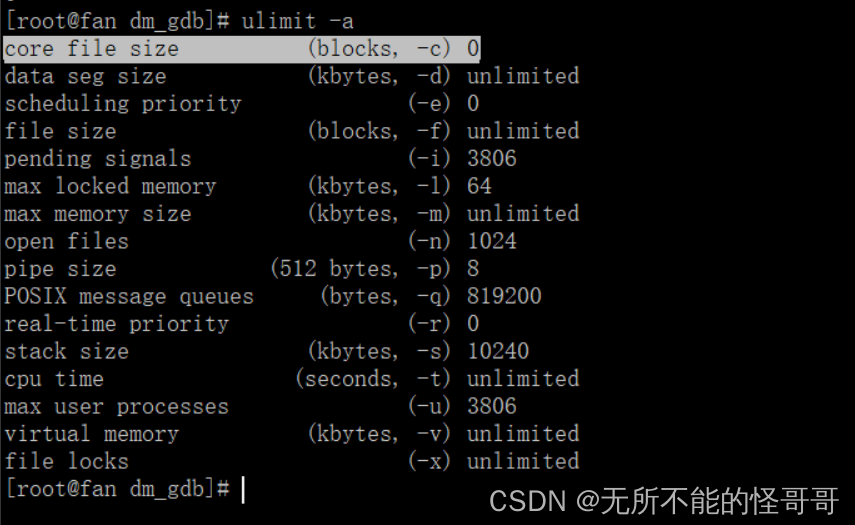
第一条就是 core 文件的限制,大小被限制为0。我们可以去改变它的大小限制,最简单的方法就是改为无限制,无限制就相当于可以是任意大小。
ulimit -c unlimited
再次查看 shell 的限制就能看到,现在 core 的限制变为 unlimited 了
我们现在再一次运行刚才的 err 可执行文件,就可以看到生成了一个 core 文件
作为一个优秀的程序员,我们可能决定还不够好,这名字是啥呀 core.9546,怪怪的,我们希望他有一个符合我们心意的名字,这也可以实现,我们可以修改 core 的配置文件 /proc/sys/kernel/core_pattern ,那你改吧,你发现改完保存不了。
因为这个文件是不能写入的,我们可以借助重定向来修改这个文件
echo "core-%e-%t" > /proc/sys/kernel/core_pattern

关于里面的参数,列表如下
| 参数 | 含义 |
|---|---|
| %p | 添加 pid |
| %u | 添加 uid |
| %g | 添加 gid |
| %s | 添加导致 core dump 的信号 |
| %t | 添加 core 生成的时间 |
| %h | 添加主机名 |
| %e | 添加命令名 |
注意,core 文件是执行可执行文件时,产生 core dump 后才会产生的一种文件,所以要先执行可执行文件,产生 core dump,这样才能得到 core 文件。
(4)通过core文件调试当掉的程序
使用 gdb 可执行文件名 core文件名 进入gdb调试
where 命令查看出错的位置
4. GDB调试多线程
(1)创建一个多线程测试文件
创建一个测试文件,代码如下,本人 Linux 专题系列有线程专题与进程专题,本文只做一个简单的线程创建。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#include <stdlib.h>
void* thread1()
{
printf("this is thread1...\n");
for(;;)
{
sleep(1);
}
}
void* thread2()
{
printf("this is thread2...\n");
for(;;)
{
sleep(1);
}
}
int main(int argc, char* argv[])
{
pthread_t tid1;
pthread_t tid2;
printf("this is main...");
pthread_create(&tid1, NULL, thread1, NULL); /*创建线程1*/
pthread_create(&tid2, NULL, thread2, NULL); /*创建线程2*/
/*等待线程结束*/
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
return 0;
}
(2)undefined reference to `pthread_create’ 错误
上面的文件创建好之后,如果直接编译,会报错undefined reference to `pthread_create’
这是因为,<pthread.h> 并非 Linux 系统的默认库,而是POSIX线程库。在Linux中将 <pthread.h> 作为一个库来使用的话,要加上 -l pthread 来显式链接该库。
这样编译就通过了。
(3)多线程调试
① 首先,运行 ttt 可执行文件,这里也会显示主进程 ID
② 然后用 SecureCRT 克隆会话或在 Linux 下直接打开一个新的终端,在另一个会话中查看进程 ID
查看主线程的线程树 pstree ,可以看到两个子线程的线程 ID
③ 查看线程栈信息,pstack
④ 进入 gdb 调试
查看线程
切换线程,根据 info 查看到的编号来切换,我们可以通过线程 ID 来判断是否切换
⑤ 打断点等等指令与之前讲的无异,这里讲一些用于线程的命令文章来源:https://www.toymoban.com/news/detail-416235.html
(gdb)thread apply num n 让线程 num 继续执行,num 是线程的编号,用info查看
(gdb)set scheduler-locking on 只执行当前线程,输入 n 继续执行
(gdb)set scheduler-locking off 所有线程并发执行
总结
熟练掌握 gdb 调试是一个高水平程序员的基本技能,其实我们用习惯了 IDE 中的调试器之后,反而越来越忽视 gdb 这种命令行的调试。但是实际上,熟练掌握 gdb 会对调试程序本身产生更深刻的理解,可以大大提高程序调试水平。如果这篇文章大家觉得有帮助,可以关注我的 Linux 专栏,里面有更多 Linux 相关的优质文章。“纸上得来终觉浅,绝知此事要躬行”,学习 Linux 知识的同时,一定要动手练习,亲自去调试一些程序,只能理解这只指令是怎么执行的。文章来源地址https://www.toymoban.com/news/detail-416235.html
到了这里,关于【五、深入浅出GDB调试器】如何修复程序bug或优化代码:gdb调试器的来龙去脉与debug全方位实战详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[Linux] Linux代码调试器 -- gdb](https://imgs.yssmx.com/Uploads/2024/02/742596-1.png)




