👀 前言:本篇是个人配置环境的总结,基于指导书,补充了许多在配置过程中出现的问题的解决细节。希望能帮到你😄。
📚前期准备
🐇 实验环境
- Vmware workstation pro 16
- Ubuntu 20.04
- JDK 1.8
- Hadoop 3.2.2
🐇相关文件下载
下边资源是本篇博客会用到的相关文件(建议直接下载,相关代码直接对应的下述文件,下载完先不要动,放在桌面上就行)

⭐️前期准备① ⭐️前期准备②
📚正确安装Hadoop伪分布式系统
🐇安装VMware
- 点开exe文件,按照提示往下next安装就行
🐇安装Ubuntu
-
打开 VMware,创建新虚拟机

-
选择典型配置,然后下一步

-
选择下载完成的 Ubuntu iso 文件,下一步

-
输入系统名,用户名密码等,下一步。全名随意,把用户名设置为 hadoop。

-
选择安装虚拟机位置(根据自己的习惯设置),下一步

-
设置磁盘大小(40G)然后下一步

-
完成安装,在这里可以根据自己电脑配置自定义内存、处理器个数等(不过基本是不用动的),点击完成。

-
等待十分钟左右,完成安装,出现如下登录页面,输入密码登录即可。

🐇安装JDK
-
打开终端,创建 java 目录
mkdir /usr/lib/jvm #创建jvm文件夹 #如果显示“permission denied”,就用下边这句(之后都同理,就是在前边加sudo) sudo mkdir /usr/lib/jvm #如果需要在前边补充sudo,那会需要输密码,输密码时,按键盘在终端不会有显示,这时候不用管,把密码输完,回车就好 -
解压到目录下


⚠️先进行以上操作,然后把jdk压缩文件(别改命名)从桌面拖动到虚拟机文件夹里,压缩包位置可在其属性里查看

sudo tar zxvf /home/hadoop/jdk-8u321-linux-x64.tar.gz -C /usr/lib/jvm #解压到/usr/lib/jvm目录下 cd /usr/lib/jvm #进入该目录 sudo mv jdk1.8.0_321 java #重命名为java文件名规范 -
配置 java 环境变量
vim ~/.bashrc⚠️如果出现这个

输入sudo apt install vim后,再次输入vim ~/.bashrc⚠️在~/.bashrc 最后添加下列代码并保存(按Insert键开始修改,最后按esc键,并输入
:wq!保存并退出,别误删了原来代码fi😢)#Java Environment export JAVA_HOME=/usr/lib/jvm/java export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH -
更新配置,并测试是否安装成功
source ~/.bashrc #使新配置的环境变量生效 java -version #检测是否安装成功,查看 java 版本成功如下图👇

🐇安装 ssh
-
安装 ssh
sudo apt-get install openssh-server #安装 SSH server -
登录本机测试
ssh localhost #登陆 SSH,第一次登陆输入 yes⚠️如下显示则成功

-
退出登录
exit #退出登录的 ssh localhost
-
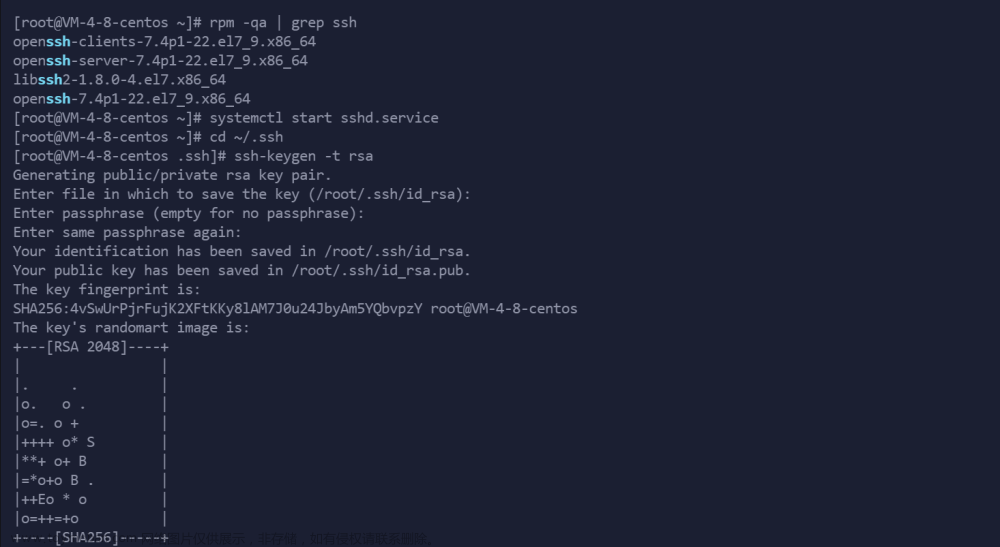
设置免密登录
cd ~/.ssh/ #如果没法进入该目录,执行一次 ssh localhost ssh-keygen -t rsa在输入完
ssh-keygen -t rsa命令时,需要连续敲击回车三次
cat ./id_rsa.pub >> ./authorized_keys #加入授权 -
免密登录测试,再次输入
ssh localhost
🐇安装单机 Hadoop
-
解压安装Hadoop
sudo tar -zxvf /home/hadoop/hadoop-3.2.2.tar.gz -C /usr/local #解压到/usr/local 目录下 cd /usr/local sudo mv hadoop-3.2.2 hadoop #重命名为 hadoop,可改可不改,如果修改下边的名字也要对应 sudo chown -R hadoop ./hadoop #修改文件权限 -
配置环境变量
vim ~/.bashrc在~/.bashrc 中添加如下代码并保存(方法同上)
#Hadoop Environment export HADOOP_HOME=/usr/local/hadoop export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
测试安装成功
source ~/.bashrc #使新配置的环境变量生效 hadoop version #测试是否安装成功
🐇伪分布式 Hadoop
-
在/usr/local/hadoop/etc/hadoop 目录 hadoop-env.sh 添加 Java 路径
cd /usr/local/hadoop/etc/hadoop vim hadoop-env.sh⚠️添加Java路径
export JAVA_HOME=/usr/lib/jvm/java -
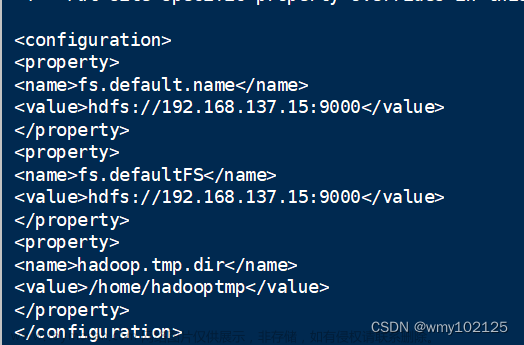
修改配置文件 core-site.xml
cd /usr/local/hadoop/etc/hadoop vim core-site.xml⚠️添加以下内容(添加前删除原先有的
<configuration>和</configuration>)<configuration> <property> <name>hadoop.tmp.dir</name> <value> file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> -
修改配置文件 hdfs-site.xml
cd /usr/local/hadoop/etc/hadoop vim hdfs-site.xml⚠️添加以下内容(添加前删除原先有的
<configuration>和</configuration>)<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> <property> <name>dfs.http.address</name> <value>0.0.0.0:50070</value> </property> </configuration> -
格式化集群节点
hdfs namenode -format最后如下图即成功

-
启动 hadoop
start-dfs.sh
⚠️使用 jps 查看进程,出现DataNode,NameNode,SecondaryNameNode 即启动成功 -
在浏览器输入
localhost:50070查看 hadoop 状态
-
关闭Hadoop
stop-dfs.sh
🐇Eclipse 环境配置
-
配置时需要开启 Hadoop
start-dfs.sh -
解压到指定文件夹
sudo tar -zxvf /home/hadoop/eclipse-java-2020-03-R-linux-gtk-x86_64.tar.gz -C /usr/local/ -
创建eclipse桌面快捷图标
cd /usr/share/applications sudo nano eclipse.desktop写入以下文件
[Desktop Entry] Encoding=UTF-8 Name=Eclipse Comment=Eclipse Exec=/usr/local/eclipse/eclipse Icon=/usr/local/eclipse-installer/icon.xpm Terminal=false StartupNotify=true Type=Application Categories=Application;Development;添加完后,先按
ctrl x,再按Y(会有一个yes询问),最后按回车,即保存且退出 -
把Eclipse添加到主页侧栏——在左下角九个点那点开,找到Eclipse(我这边是透明的😢,但是不影响使用),
Add to Favorites
-
这时候在桌面点开还是打不开的,会有如下报错,需要配置环境
A Java Runtime Environment (JRE) or Java Development Kit (JDK) must be available in order to run Eclipse. No Java virtual machine was found after searching the following locations: /usr/local/eclipse/jre/bin/java java in your current PATH
sudo gedit /etc/profile添加环境
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/:$PATH -
检查jdk是否安装成功
source /etc/profile java -version -
然后添加软连接
sudo ln -s /usr/lib/jvm/java/bin /usr/local/eclipse/jre -
安装eclipse对Hadoop的插件,把hadoop-eclipse-kepler-plugin-2.6.0.jar 复制到/usr/local/eclipse/plugins 目录下,重启 eclipse
终端建立的文件夹,在文件夹
Other Locations里的Computer里找

如果能直接拖入就直接拖入,不行就先把hadoop-eclipse-kepler-plugin-2.6.0.jar拖入home(就之前拖入压缩包的地方),然后终端输入
sudo mv /home/hadoop/hadoop-eclipse-kepler-plugin-2.6.0.jar /usr/local/eclipse/plugins -
重启后从 eclipse 的 Windows 菜单栏中找到 preference,看到左边有 Hadoop map/reduce 选项,然后找到 hadoop 的目录(/usr/local/hadoop),点击应用。

-
从 windows 菜单栏中选择 perspective->open perspective->other,会看到map/reduce 选项,点击确定切换

-
点击 Eclipse软件右下角的 Map/ReduceLocations 面板,在面板中单击右键,选择 New Hadoop Location。

-
在 general 面板中,配置与本机 hadoop 相关配置相同
 文章来源:https://www.toymoban.com/news/detail-416383.html
文章来源:https://www.toymoban.com/news/detail-416383.html -
配置成功后 eclipse 左上角会出现 Hadoop 可视化目录
 文章来源地址https://www.toymoban.com/news/detail-416383.html
文章来源地址https://www.toymoban.com/news/detail-416383.html
🐇建立项目
- 在 eclipse 中新建 mapreduce 项目:file->new->project->mapreduce project,其他新建包和新建类与 java 项目相同

- 在运行 mapreduce 程序之前,需要将/usr/local/hadoop/etc/hadoop 中将有修改过的配置文件(如伪分布式需要 core-site.xml 和 hdfs-site.xml),以及log4j.properties 复制到新建项目下的 src 文件夹中,在 eclipse 中刷新。

到了这里,关于大数据 | 实验零:安装 Hadoop 伪分布式系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!