一,分布式系统概述
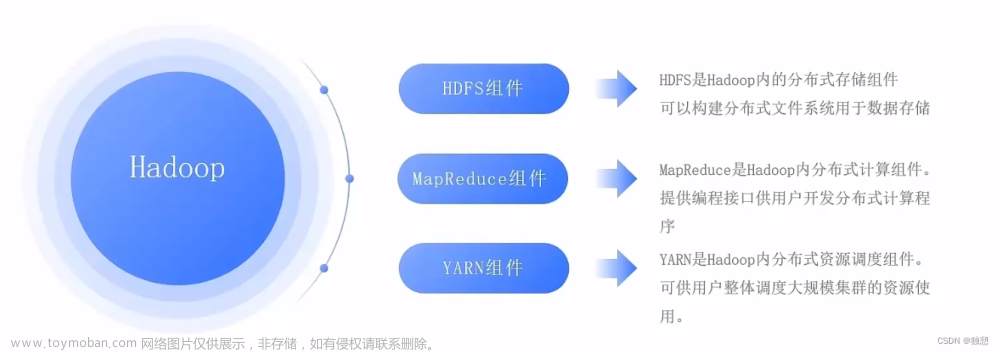
Hadoop的两大核心组件

HDFS(Hadoop Distributed Filesystem):是一个易于扩展的分布式文件系统,运行在成百上千台低成本的机器上。HDFS具有高度容错能力,旨在部署在低成本机器上。HDFS主要用于对海量文件信息进行存储和管理,也就是解决大数据文件(如TB乃至PB级)的存储问题,是目前应用最广泛的分布式文件系统。
分布式系统的演变:
传统文件系统遇到的问题 :
传统文件系统的问题:
•当数据量越来越大时,会遇到存储瓶颈,需要扩容;
•由于文件过大,上传下载都非常耗时
分布式文件系统的雏形:
•横向扩容,即增加服务器数量,构成计算机集群
•将大文件切割成多个数据块,将数据块以并行的方式,分布地在多个计算机节点上进行存储、读取
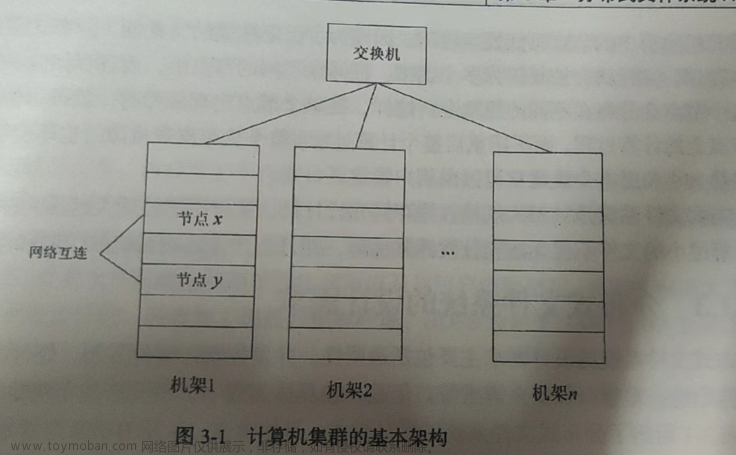
DHFS集群架构:

- 普通Hadoop集群结构由一个两阶网络构成。
- 机架内的节点之间、机架之间,通过光纤高速交换机完成彼此的连接与交互。
- 每个机架(Rack)有30-40个服务器,配置一个1GB的交换机,并向上连接到一个核心交换机或者路由器(1GB或以上)。
HDFS的集群中的节点分为两类:

| 支持超大文件 | 流式数据读写 | 高数据吞吐量 | 硬件设备要求低 | 高容错性 | …… |
一次写入、多次读取的流式数据访问模式:
| •一次写入: | 从数据源收集或生成的数据集,向HDFS中的文件一次性写入,关闭之后不可修改,只能在文件末尾追加。 |
| •多次读取: | 在该数据集上进行各种分析,每次分析都需要读取该数据集的大部分甚至全部数据 |
| •流式数据访问: | 读取数据文件就像流水一样,不是一次性过来而是 “流”过来,来一部分、处理一部分。例如,下载电影,用迅雷边下边播。 |
DHFS的缺点:
| 不适合低延迟数据访问 | 无法高效存储大量小文件 | 不支持多用户写入和修改 | …… |
无法高效存储大量小文件:
由于名称节点将HDFS文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于名称节点的内存容量。一般每个文件、目录和数据块的元数据存储信息大约占150字节(B)。因此,如果有一百万个文件,且每个文件占一个数据块,那至少需要300MB的内存。尽管存储上百万个文件是可行的,但是存储数十亿个文件就超出了当前硬件的能力。
二,相关的概念
1,(block)数据块的概念:

2,元数据

3,(NameNode)名称结点(我的理解是代理服务器)
主要作用:
4,(DtaNode)数据节点
数据节点是HDFS集群中的从服务器,称为数据节点,它与NameNode保持不断的通信,其主要作用:文章来源:https://www.toymoban.com/news/detail-416451.html

以上仅仅是我的理解,仅供参考。文章来源地址https://www.toymoban.com/news/detail-416451.html
到了这里,关于大数据——HDFS(分布式文件系统)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!