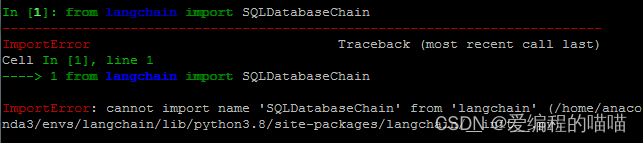
昨天试着安装一下信息收集特别好用的工具oneforall,没想到却遇到了一个特别大的问题
cannot import name 'sre_parse' from 're'(C:\Python311\Lib\re\_init_.py)
上网查找,却没想到竟然你没有一个答案,要么没有正确答案,要么众说纷纭,索性自己排查错误
根据报错提示,说的是不能从re中导入sre_parse,而且还和re文件夹下的_init_.py有关
下面是我python目前安装re中_init_.py的源码
#
# Secret Labs' Regular Expression Engine
#
# re-compatible interface for the sre matching engine
#
# Copyright (c) 1998-2001 by Secret Labs AB. All rights reserved.
#
# This version of the SRE library can be redistributed under CNRI's
# Python 1.6 license. For any other use, please contact Secret Labs
# AB (info@pythonware.com).
#
# Portions of this engine have been developed in cooperation with
# CNRI. Hewlett-Packard provided funding for 1.6 integration and
# other compatibility work.
#
r"""Support for regular expressions (RE).
This module provides regular expression matching operations similar to
those found in Perl. It supports both 8-bit and Unicode strings; both
the pattern and the strings being processed can contain null bytes and
characters outside the US ASCII range.
Regular expressions can contain both special and ordinary characters.
Most ordinary characters, like "A", "a", or "0", are the simplest
regular expressions; they simply match themselves. You can
concatenate ordinary characters, so last matches the string 'last'.
The special characters are:
"." Matches any character except a newline.
"^" Matches the start of the string.
"$" Matches the end of the string or just before the newline at
the end of the string.
"*" Matches 0 or more (greedy) repetitions of the preceding RE.
Greedy means that it will match as many repetitions as possible.
"+" Matches 1 or more (greedy) repetitions of the preceding RE.
"?" Matches 0 or 1 (greedy) of the preceding RE.
*?,+?,?? Non-greedy versions of the previous three special characters.
{m,n} Matches from m to n repetitions of the preceding RE.
{m,n}? Non-greedy version of the above.
"\\" Either escapes special characters or signals a special sequence.
[] Indicates a set of characters.
A "^" as the first character indicates a complementing set.
"|" A|B, creates an RE that will match either A or B.
(...) Matches the RE inside the parentheses.
The contents can be retrieved or matched later in the string.
(?aiLmsux) The letters set the corresponding flags defined below.
(?:...) Non-grouping version of regular parentheses.
(?P<name>...) The substring matched by the group is accessible by name.
(?P=name) Matches the text matched earlier by the group named name.
(?#...) A comment; ignored.
(?=...) Matches if ... matches next, but doesn't consume the string.
(?!...) Matches if ... doesn't match next.
(?<=...) Matches if preceded by ... (must be fixed length).
(?<!...) Matches if not preceded by ... (must be fixed length).
(?(id/name)yes|no) Matches yes pattern if the group with id/name matched,
the (optional) no pattern otherwise.
The special sequences consist of "\\" and a character from the list
below. If the ordinary character is not on the list, then the
resulting RE will match the second character.
\number Matches the contents of the group of the same number.
\A Matches only at the start of the string.
\Z Matches only at the end of the string.
\b Matches the empty string, but only at the start or end of a word.
\B Matches the empty string, but not at the start or end of a word.
\d Matches any decimal digit; equivalent to the set [0-9] in
bytes patterns or string patterns with the ASCII flag.
In string patterns without the ASCII flag, it will match the whole
range of Unicode digits.
\D Matches any non-digit character; equivalent to [^\d].
\s Matches any whitespace character; equivalent to [ \t\n\r\f\v] in
bytes patterns or string patterns with the ASCII flag.
In string patterns without the ASCII flag, it will match the whole
range of Unicode whitespace characters.
\S Matches any non-whitespace character; equivalent to [^\s].
\w Matches any alphanumeric character; equivalent to [a-zA-Z0-9_]
in bytes patterns or string patterns with the ASCII flag.
In string patterns without the ASCII flag, it will match the
range of Unicode alphanumeric characters (letters plus digits
plus underscore).
With LOCALE, it will match the set [0-9_] plus characters defined
as letters for the current locale.
\W Matches the complement of \w.
\\ Matches a literal backslash.
This module exports the following functions:
match Match a regular expression pattern to the beginning of a string.
fullmatch Match a regular expression pattern to all of a string.
search Search a string for the presence of a pattern.
sub Substitute occurrences of a pattern found in a string.
subn Same as sub, but also return the number of substitutions made.
split Split a string by the occurrences of a pattern.
findall Find all occurrences of a pattern in a string.
finditer Return an iterator yielding a Match object for each match.
compile Compile a pattern into a Pattern object.
purge Clear the regular expression cache.
escape Backslash all non-alphanumerics in a string.
Each function other than purge and escape can take an optional 'flags' argument
consisting of one or more of the following module constants, joined by "|".
A, L, and U are mutually exclusive.
A ASCII For string patterns, make \w, \W, \b, \B, \d, \D
match the corresponding ASCII character categories
(rather than the whole Unicode categories, which is the
default).
For bytes patterns, this flag is the only available
behaviour and needn't be specified.
I IGNORECASE Perform case-insensitive matching.
L LOCALE Make \w, \W, \b, \B, dependent on the current locale.
M MULTILINE "^" matches the beginning of lines (after a newline)
as well as the string.
"$" matches the end of lines (before a newline) as well
as the end of the string.
S DOTALL "." matches any character at all, including the newline.
X VERBOSE Ignore whitespace and comments for nicer looking RE's.
U UNICODE For compatibility only. Ignored for string patterns (it
is the default), and forbidden for bytes patterns.
This module also defines an exception 'error'.
"""
import enum
from . import _compiler, _parser
import functools
# public symbols
__all__ = [
"match", "fullmatch", "search", "sub", "subn", "split",
"findall", "finditer", "compile", "purge", "template", "escape",
"error", "Pattern", "Match", "A", "I", "L", "M", "S", "X", "U",
"ASCII", "IGNORECASE", "LOCALE", "MULTILINE", "DOTALL", "VERBOSE",
"UNICODE", "NOFLAG", "RegexFlag",
]
__version__ = "2.2.1"
@enum.global_enum
@enum._simple_enum(enum.IntFlag, boundary=enum.KEEP)
class RegexFlag:
NOFLAG = 0
ASCII = A = _compiler.SRE_FLAG_ASCII # assume ascii "locale"
IGNORECASE = I = _compiler.SRE_FLAG_IGNORECASE # ignore case
LOCALE = L = _compiler.SRE_FLAG_LOCALE # assume current 8-bit locale
UNICODE = U = _compiler.SRE_FLAG_UNICODE # assume unicode "locale"
MULTILINE = M = _compiler.SRE_FLAG_MULTILINE # make anchors look for newline
DOTALL = S = _compiler.SRE_FLAG_DOTALL # make dot match newline
VERBOSE = X = _compiler.SRE_FLAG_VERBOSE # ignore whitespace and comments
# sre extensions (experimental, don't rely on these)
TEMPLATE = T = _compiler.SRE_FLAG_TEMPLATE # unknown purpose, deprecated
DEBUG = _compiler.SRE_FLAG_DEBUG # dump pattern after compilation
__str__ = object.__str__
_numeric_repr_ = hex
# sre exception
error = _compiler.error
# --------------------------------------------------------------------
# public interface
def match(pattern, string, flags=0):
"""Try to apply the pattern at the start of the string, returning
a Match object, or None if no match was found."""
return _compile(pattern, flags).match(string)
def fullmatch(pattern, string, flags=0):
"""Try to apply the pattern to all of the string, returning
a Match object, or None if no match was found."""
return _compile(pattern, flags).fullmatch(string)
def search(pattern, string, flags=0):
"""Scan through string looking for a match to the pattern, returning
a Match object, or None if no match was found."""
return _compile(pattern, flags).search(string)
def sub(pattern, repl, string, count=0, flags=0):
"""Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the Match object and must return
a replacement string to be used."""
return _compile(pattern, flags).sub(repl, string, count)
def subn(pattern, repl, string, count=0, flags=0):
"""Return a 2-tuple containing (new_string, number).
new_string is the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in the source
string by the replacement repl. number is the number of
substitutions that were made. repl can be either a string or a
callable; if a string, backslash escapes in it are processed.
If it is a callable, it's passed the Match object and must
return a replacement string to be used."""
return _compile(pattern, flags).subn(repl, string, count)
def split(pattern, string, maxsplit=0, flags=0):
"""Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings. If
capturing parentheses are used in pattern, then the text of all
groups in the pattern are also returned as part of the resulting
list. If maxsplit is nonzero, at most maxsplit splits occur,
and the remainder of the string is returned as the final element
of the list."""
return _compile(pattern, flags).split(string, maxsplit)
def findall(pattern, string, flags=0):
"""Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result."""
return _compile(pattern, flags).findall(string)
def finditer(pattern, string, flags=0):
"""Return an iterator over all non-overlapping matches in the
string. For each match, the iterator returns a Match object.
Empty matches are included in the result."""
return _compile(pattern, flags).finditer(string)
def compile(pattern, flags=0):
"Compile a regular expression pattern, returning a Pattern object."
return _compile(pattern, flags)
def purge():
"Clear the regular expression caches"
_cache.clear()
_compile_repl.cache_clear()
def template(pattern, flags=0):
"Compile a template pattern, returning a Pattern object, deprecated"
import warnings
warnings.warn("The re.template() function is deprecated "
"as it is an undocumented function "
"without an obvious purpose. "
"Use re.compile() instead.",
DeprecationWarning)
with warnings.catch_warnings():
warnings.simplefilter("ignore", DeprecationWarning) # warn just once
return _compile(pattern, flags|T)
# SPECIAL_CHARS
# closing ')', '}' and ']'
# '-' (a range in character set)
# '&', '~', (extended character set operations)
# '#' (comment) and WHITESPACE (ignored) in verbose mode
_special_chars_map = {i: '\\' + chr(i) for i in b'()[]{}?*+-|^$\\.&~# \t\n\r\v\f'}
def escape(pattern):
"""
Escape special characters in a string.
"""
if isinstance(pattern, str):
return pattern.translate(_special_chars_map)
else:
pattern = str(pattern, 'latin1')
return pattern.translate(_special_chars_map).encode('latin1')
Pattern = type(_compiler.compile('', 0))
Match = type(_compiler.compile('', 0).match(''))
# --------------------------------------------------------------------
# internals
_cache = {} # ordered!
_MAXCACHE = 512
def _compile(pattern, flags):
# internal: compile pattern
if isinstance(flags, RegexFlag):
flags = flags.value
try:
return _cache[type(pattern), pattern, flags]
except KeyError:
pass
if isinstance(pattern, Pattern):
if flags:
raise ValueError(
"cannot process flags argument with a compiled pattern")
return pattern
if not _compiler.isstring(pattern):
raise TypeError("first argument must be string or compiled pattern")
if flags & T:
import warnings
warnings.warn("The re.TEMPLATE/re.T flag is deprecated "
"as it is an undocumented flag "
"without an obvious purpose. "
"Don't use it.",
DeprecationWarning)
p = _compiler.compile(pattern, flags)
if not (flags & DEBUG):
if len(_cache) >= _MAXCACHE:
# Drop the oldest item
try:
del _cache[next(iter(_cache))]
except (StopIteration, RuntimeError, KeyError):
pass
_cache[type(pattern), pattern, flags] = p
return p
@functools.lru_cache(_MAXCACHE)
def _compile_repl(repl, pattern):
# internal: compile replacement pattern
return _parser.parse_template(repl, pattern)
def _expand(pattern, match, template):
# internal: Match.expand implementation hook
template = _parser.parse_template(template, pattern)
return _parser.expand_template(template, match)
def _subx(pattern, template):
# internal: Pattern.sub/subn implementation helper
template = _compile_repl(template, pattern)
if not template[0] and len(template[1]) == 1:
# literal replacement
return template[1][0]
def filter(match, template=template):
return _parser.expand_template(template, match)
return filter
# register myself for pickling
import copyreg
def _pickle(p):
return _compile, (p.pattern, p.flags)
copyreg.pickle(Pattern, _pickle, _compile)
# --------------------------------------------------------------------
# experimental stuff (see python-dev discussions for details)
class Scanner:
def __init__(self, lexicon, flags=0):
from ._constants import BRANCH, SUBPATTERN
if isinstance(flags, RegexFlag):
flags = flags.value
self.lexicon = lexicon
# combine phrases into a compound pattern
p = []
s = _parser.State()
s.flags = flags
for phrase, action in lexicon:
gid = s.opengroup()
p.append(_parser.SubPattern(s, [
(SUBPATTERN, (gid, 0, 0, _parser.parse(phrase, flags))),
]))
s.closegroup(gid, p[-1])
p = _parser.SubPattern(s, [(BRANCH, (None, p))])
self.scanner = _compiler.compile(p)
def scan(self, string):
result = []
append = result.append
match = self.scanner.scanner(string).match
i = 0
while True:
m = match()
if not m:
break
j = m.end()
if i == j:
break
action = self.lexicon[m.lastindex-1][1]
if callable(action):
self.match = m
action = action(self, m.group())
if action is not None:
append(action)
i = j
return result, string[i:]
这里放出关键信息


同时根据报错提示我也在我的C:\Python311\Lib\site-packages\exrex.py查看
经过对比,我的C:\Python311\Lib\re_init_.py中根本没有sre_parse,只有_parser!!!
随后我在网上查找别人的re源码文章来源:https://www.toymoban.com/news/detail-416571.html
#
# Secret Labs' Regular Expression Engine
#
# re-compatible interface for the sre matching engine
#
# Copyright (c) 1998-2001 by Secret Labs AB. All rights reserved.
#
# This version of the SRE library can be redistributed under CNRI's
# Python 1.6 license. For any other use, please contact Secret Labs
# AB (info@pythonware.com).
#
# Portions of this engine have been developed in cooperation with
# CNRI. Hewlett-Packard provided funding for 1.6 integration and
# other compatibility work.
#
r"""Support for regular expressions (RE).
This module provides regular expression matching operations similar to
those found in Perl. It supports both 8-bit and Unicode strings; both
the pattern and the strings being processed can contain null bytes and
characters outside the US ASCII range.
Regular expressions can contain both special and ordinary characters.
Most ordinary characters, like "A", "a", or "0", are the simplest
regular expressions; they simply match themselves. You can
concatenate ordinary characters, so last matches the string 'last'.
The special characters are:
"." Matches any character except a newline.
"^" Matches the start of the string.
"$" Matches the end of the string or just before the newline at
the end of the string.
"*" Matches 0 or more (greedy) repetitions of the preceding RE.
Greedy means that it will match as many repetitions as possible.
"+" Matches 1 or more (greedy) repetitions of the preceding RE.
"?" Matches 0 or 1 (greedy) of the preceding RE.
*?,+?,?? Non-greedy versions of the previous three special characters.
{m,n} Matches from m to n repetitions of the preceding RE.
{m,n}? Non-greedy version of the above.
"\\" Either escapes special characters or signals a special sequence.
[] Indicates a set of characters.
A "^" as the first character indicates a complementing set.
"|" A|B, creates an RE that will match either A or B.
(...) Matches the RE inside the parentheses.
The contents can be retrieved or matched later in the string.
(?iLmsux) Set the I, L, M, S, U, or X flag for the RE (see below).
(?:...) Non-grouping version of regular parentheses.
(?P<name>...) The substring matched by the group is accessible by name.
(?P=name) Matches the text matched earlier by the group named name.
(?#...) A comment; ignored.
(?=...) Matches if ... matches next, but doesn't consume the string.
(?!...) Matches if ... doesn't match next.
(?<=...) Matches if preceded by ... (must be fixed length).
(?<!...) Matches if not preceded by ... (must be fixed length).
(?(id/name)yes|no) Matches yes pattern if the group with id/name matched,
the (optional) no pattern otherwise.
The special sequences consist of "\\" and a character from the list
below. If the ordinary character is not on the list, then the
resulting RE will match the second character.
\number Matches the contents of the group of the same number.
\A Matches only at the start of the string.
\Z Matches only at the end of the string.
\b Matches the empty string, but only at the start or end of a word.
\B Matches the empty string, but not at the start or end of a word.
\d Matches any decimal digit; equivalent to the set [0-9].
\D Matches any non-digit character; equivalent to the set [^0-9].
\s Matches any whitespace character; equivalent to [ \t\n\r\f\v].
\S Matches any non-whitespace character; equiv. to [^ \t\n\r\f\v].
\w Matches any alphanumeric character; equivalent to [a-zA-Z0-9_].
With LOCALE, it will match the set [0-9_] plus characters defined
as letters for the current locale.
\W Matches the complement of \w.
\\ Matches a literal backslash.
This module exports the following functions:
match Match a regular expression pattern to the beginning of a string.
search Search a string for the presence of a pattern.
sub Substitute occurrences of a pattern found in a string.
subn Same as sub, but also return the number of substitutions made.
split Split a string by the occurrences of a pattern.
findall Find all occurrences of a pattern in a string.
finditer Return an iterator yielding a match object for each match.
compile Compile a pattern into a RegexObject.
purge Clear the regular expression cache.
escape Backslash all non-alphanumerics in a string.
Some of the functions in this module takes flags as optional parameters:
I IGNORECASE Perform case-insensitive matching.
L LOCALE Make \w, \W, \b, \B, dependent on the current locale.
M MULTILINE "^" matches the beginning of lines (after a newline)
as well as the string.
"$" matches the end of lines (before a newline) as well
as the end of the string.
S DOTALL "." matches any character at all, including the newline.
X VERBOSE Ignore whitespace and comments for nicer looking RE's.
U UNICODE Make \w, \W, \b, \B, dependent on the Unicode locale.
This module also defines an exception 'error'.
"""
import sys
import sre_compile
import sre_parse
# public symbols
__all__ = [ "match", "search", "sub", "subn", "split", "findall",
"compile", "purge", "template", "escape", "I", "L", "M", "S", "X",
"U", "IGNORECASE", "LOCALE", "MULTILINE", "DOTALL", "VERBOSE",
"UNICODE", "error" ]
__version__ = "2.2.1"
# flags
I = IGNORECASE = sre_compile.SRE_FLAG_IGNORECASE # ignore case
L = LOCALE = sre_compile.SRE_FLAG_LOCALE # assume current 8-bit locale
U = UNICODE = sre_compile.SRE_FLAG_UNICODE # assume unicode locale
M = MULTILINE = sre_compile.SRE_FLAG_MULTILINE # make anchors look for newline
S = DOTALL = sre_compile.SRE_FLAG_DOTALL # make dot match newline
X = VERBOSE = sre_compile.SRE_FLAG_VERBOSE # ignore whitespace and comments
# sre extensions (experimental, don't rely on these)
T = TEMPLATE = sre_compile.SRE_FLAG_TEMPLATE # disable backtracking
DEBUG = sre_compile.SRE_FLAG_DEBUG # dump pattern after compilation
# sre exception
error = sre_compile.error
# --------------------------------------------------------------------
# public interface
def match(pattern, string, flags=0):
"""Try to apply the pattern at the start of the string, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).match(string)
def search(pattern, string, flags=0):
"""Scan through string looking for a match to the pattern, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).search(string)
def sub(pattern, repl, string, count=0, flags=0):
"""Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used."""
return _compile(pattern, flags).sub(repl, string, count)
def subn(pattern, repl, string, count=0, flags=0):
"""Return a 2-tuple containing (new_string, number).
new_string is the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in the source
string by the replacement repl. number is the number of
substitutions that were made. repl can be either a string or a
callable; if a string, backslash escapes in it are processed.
If it is a callable, it's passed the match object and must
return a replacement string to be used."""
return _compile(pattern, flags).subn(repl, string, count)
def split(pattern, string, maxsplit=0, flags=0):
"""Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings."""
return _compile(pattern, flags).split(string, maxsplit)
def findall(pattern, string, flags=0):
"""Return a list of all non-overlapping matches in the string.
If one or more groups are present in the pattern, return a
list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result."""
return _compile(pattern, flags).findall(string)
if sys.hexversion >= 0x02020000:
__all__.append("finditer")
def finditer(pattern, string, flags=0):
"""Return an iterator over all non-overlapping matches in the
string. For each match, the iterator returns a match object.
Empty matches are included in the result."""
return _compile(pattern, flags).finditer(string)
def compile(pattern, flags=0):
"Compile a regular expression pattern, returning a pattern object."
return _compile(pattern, flags)
def purge():
"Clear the regular expression cache"
_cache.clear()
_cache_repl.clear()
def template(pattern, flags=0):
"Compile a template pattern, returning a pattern object"
return _compile(pattern, flags|T)
_alphanum = frozenset(
"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789")
def escape(pattern):
"Escape all non-alphanumeric characters in pattern."
s = list(pattern)
alphanum = _alphanum
for i, c in enumerate(pattern):
if c not in alphanum:
if c == "\000":
s[i] = "\\000"
else:
s[i] = "\\" + c
return pattern[:0].join(s)
# --------------------------------------------------------------------
# internals
_cache = {}
_cache_repl = {}
_pattern_type = type(sre_compile.compile("", 0))
_MAXCACHE = 100
def _compile(*key):
# internal: compile pattern
pattern, flags = key
bypass_cache = flags & DEBUG
if not bypass_cache:
cachekey = (type(key[0]),) + key
p = _cache.get(cachekey)
if p is not None:
return p
if isinstance(pattern, _pattern_type):
if flags:
raise ValueError('Cannot process flags argument with a compiled pattern')
return pattern
if not sre_compile.isstring(pattern):
raise TypeError, "first argument must be string or compiled pattern"
try:
p = sre_compile.compile(pattern, flags)
except error, v:
raise error, v # invalid expression
if not bypass_cache:
if len(_cache) >= _MAXCACHE:
_cache.clear()
_cache[cachekey] = p
return p
def _compile_repl(*key):
# internal: compile replacement pattern
p = _cache_repl.get(key)
if p is not None:
return p
repl, pattern = key
try:
p = sre_parse.parse_template(repl, pattern)
except error, v:
raise error, v # invalid expression
if len(_cache_repl) >= _MAXCACHE:
_cache_repl.clear()
_cache_repl[key] = p
return p
def _expand(pattern, match, template):
# internal: match.expand implementation hook
template = sre_parse.parse_template(template, pattern)
return sre_parse.expand_template(template, match)
def _subx(pattern, template):
# internal: pattern.sub/subn implementation helper
template = _compile_repl(template, pattern)
if not template[0] and len(template[1]) == 1:
# literal replacement
return template[1][0]
def filter(match, template=template):
return sre_parse.expand_template(template, match)
return filter
# register myself for pickling
import copy_reg
def _pickle(p):
return _compile, (p.pattern, p.flags)
copy_reg.pickle(_pattern_type, _pickle, _compile)
# --------------------------------------------------------------------
# experimental stuff (see python-dev discussions for details)
class Scanner:
def __init__(self, lexicon, flags=0):
from sre_constants import BRANCH, SUBPATTERN
self.lexicon = lexicon
# combine phrases into a compound pattern
p = []
s = sre_parse.Pattern()
s.flags = flags
for phrase, action in lexicon:
p.append(sre_parse.SubPattern(s, [
(SUBPATTERN, (len(p)+1, sre_parse.parse(phrase, flags))),
]))
s.groups = len(p)+1
p = sre_parse.SubPattern(s, [(BRANCH, (None, p))])
self.scanner = sre_compile.compile(p)
def scan(self, string):
result = []
append = result.append
match = self.scanner.scanner(string).match
i = 0
while 1:
m = match()
if not m:
break
j = m.end()
if i == j:
break
action = self.lexicon[m.lastindex-1][1]
if hasattr(action, '__call__'):
self.match = m
action = action(self, m.group())
if action is not None:
append(action)
i = j
return result, string[i:]


进行对比,我发现他们的re源码中竟然有sre_parse而不是_parser,那问题肯定就出在我自己身上了
我猜测应该是我在配置python解释器的时候所有的项目都只用一个python3.11的解释器,而且我都是在GitHub上直接拿人家的项目,缺少哪个安装包直接就在pycharm上安装且没有使用虚拟环境从而导致版本冲突
所以我在这里建议大家使用Python项目的时候一定要养成使用虚拟环境的好习惯,否则你真的可能连自己错在哪里都不知道(当然如果你按步骤下来都没有问题那肯定更好了,毕竟报错的只是少部分人)
最后怎样避免版本冲突使用虚拟环境的方法,大家自行在网上查找吧,说实话我自己除了编写poc/exp以外对pycharm也不是很了解文章来源地址https://www.toymoban.com/news/detail-416571.html
到了这里,关于安装oneforall遇到的问题ImportError: cannot import name ‘sre_parse‘ from ‘re‘(C:\Python311\Lib\re\_init_.py)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!