前言
性能优化,是前端绕过不去的一道门槛,甚是重要。最近一年,也很少有机会在项目中进行前端性能优化,一直在忙于业务开发。
最近终于是来了机会,遇到了这样的场景,心里也甚是激动,写个随笔记录下性能优化的过程及逻辑,有需要的可以参考下。
场景
后端接口一下子返回了 9000 多条数据,而且不带分页参数,全部返回了。
说实话,刚联调接口的时候我也有点懵,也是第一次遇到这样的情况,于是询问后端同学为什么要这样。他回复我说是因为特殊需要,后端调的是大数据的接口,拿的是大数据团队的数据,技术方案评审时,要求数据不落表(我也不太懂后端这是什么意思)
毫无疑问,将近一万条数据在前端渲染,百分之百的会造成卡顿。而且接口调用时间也会很长。

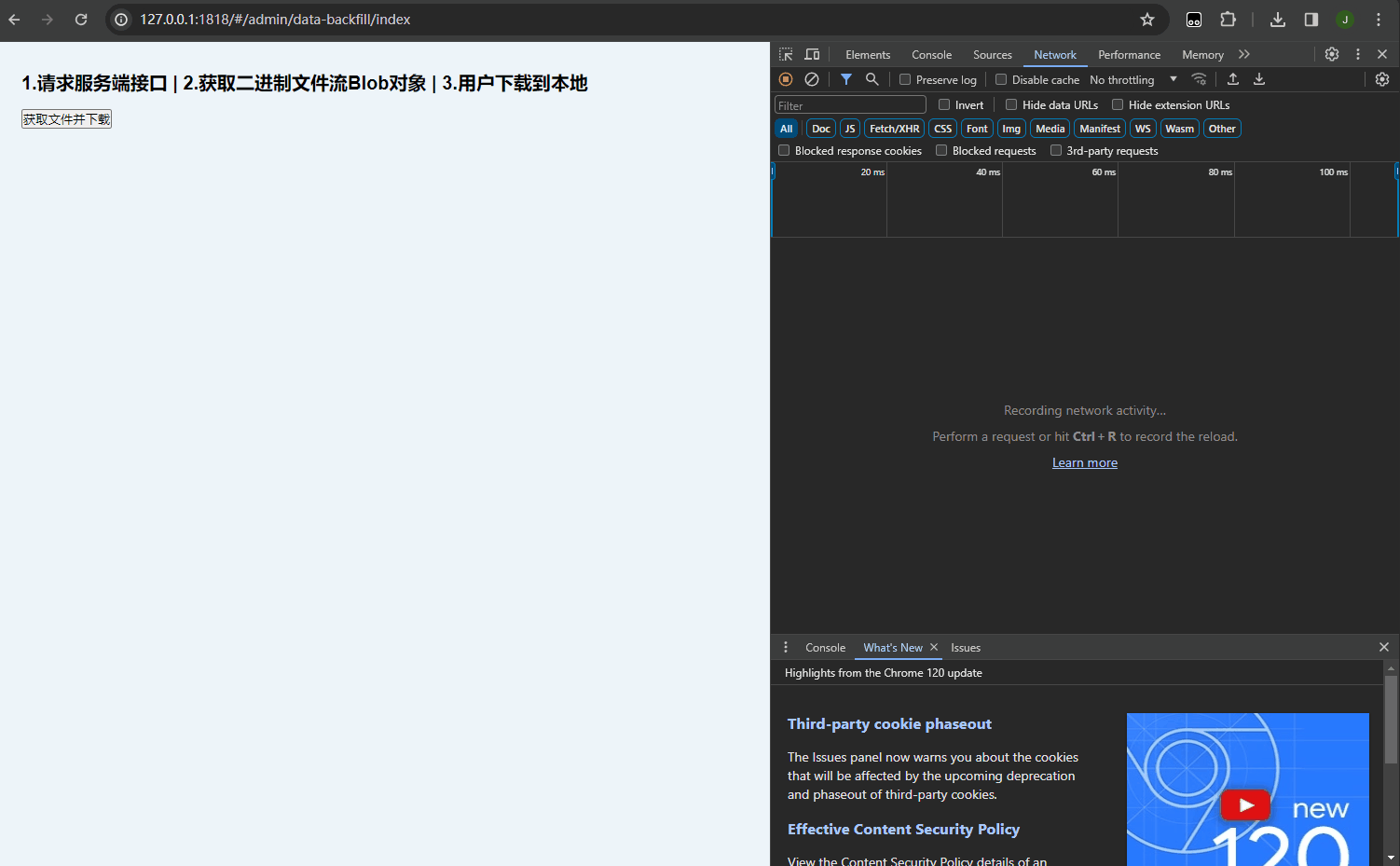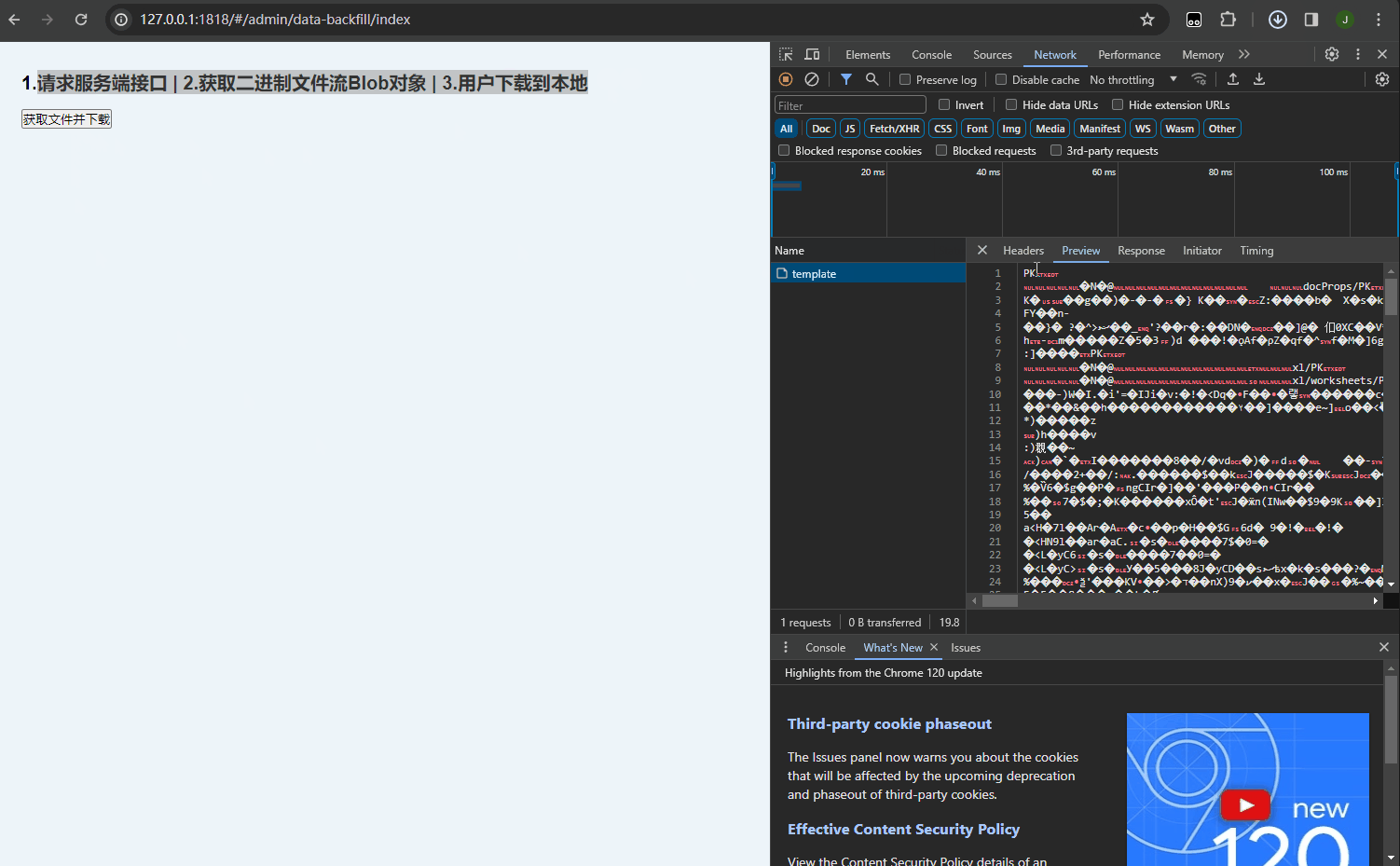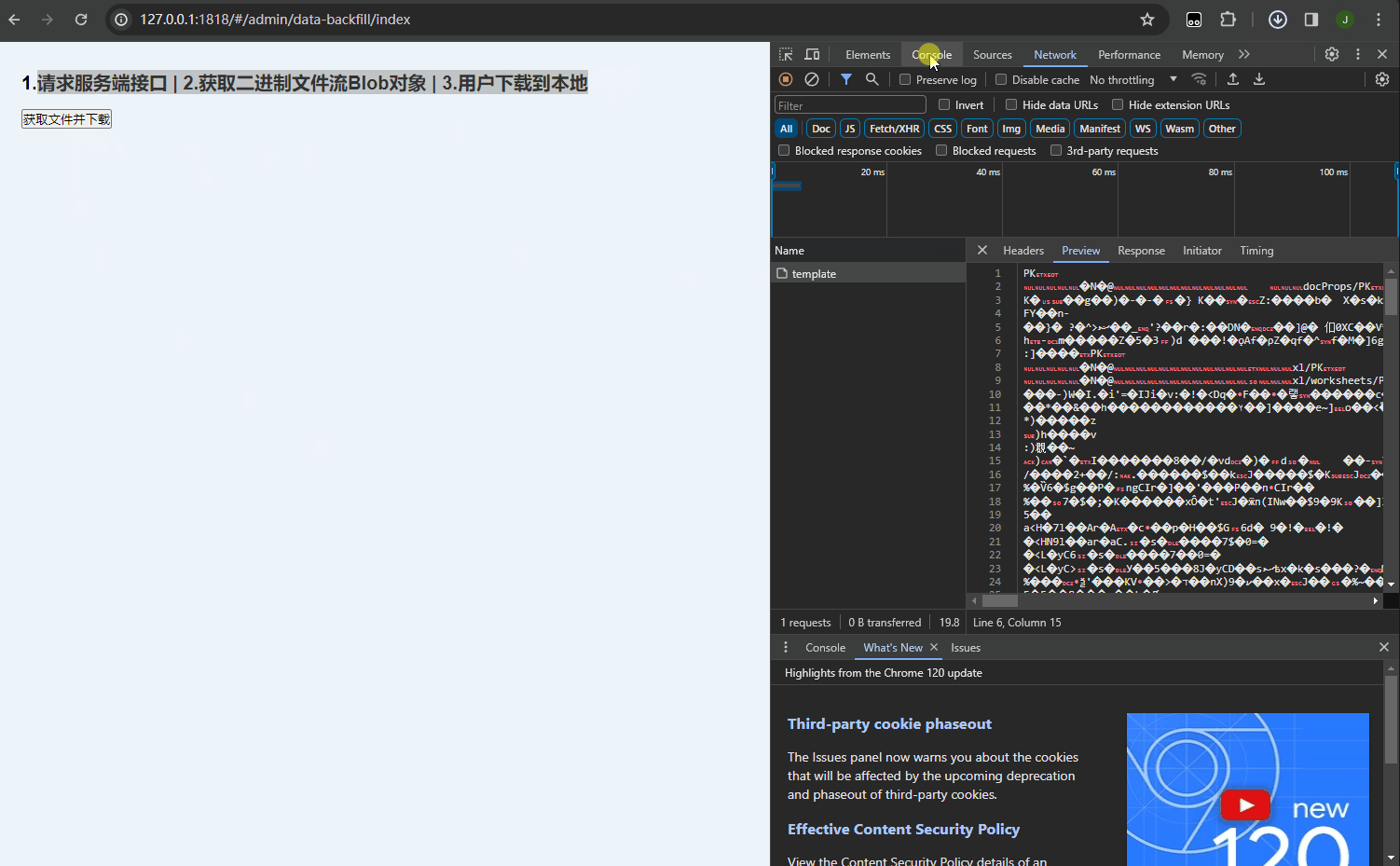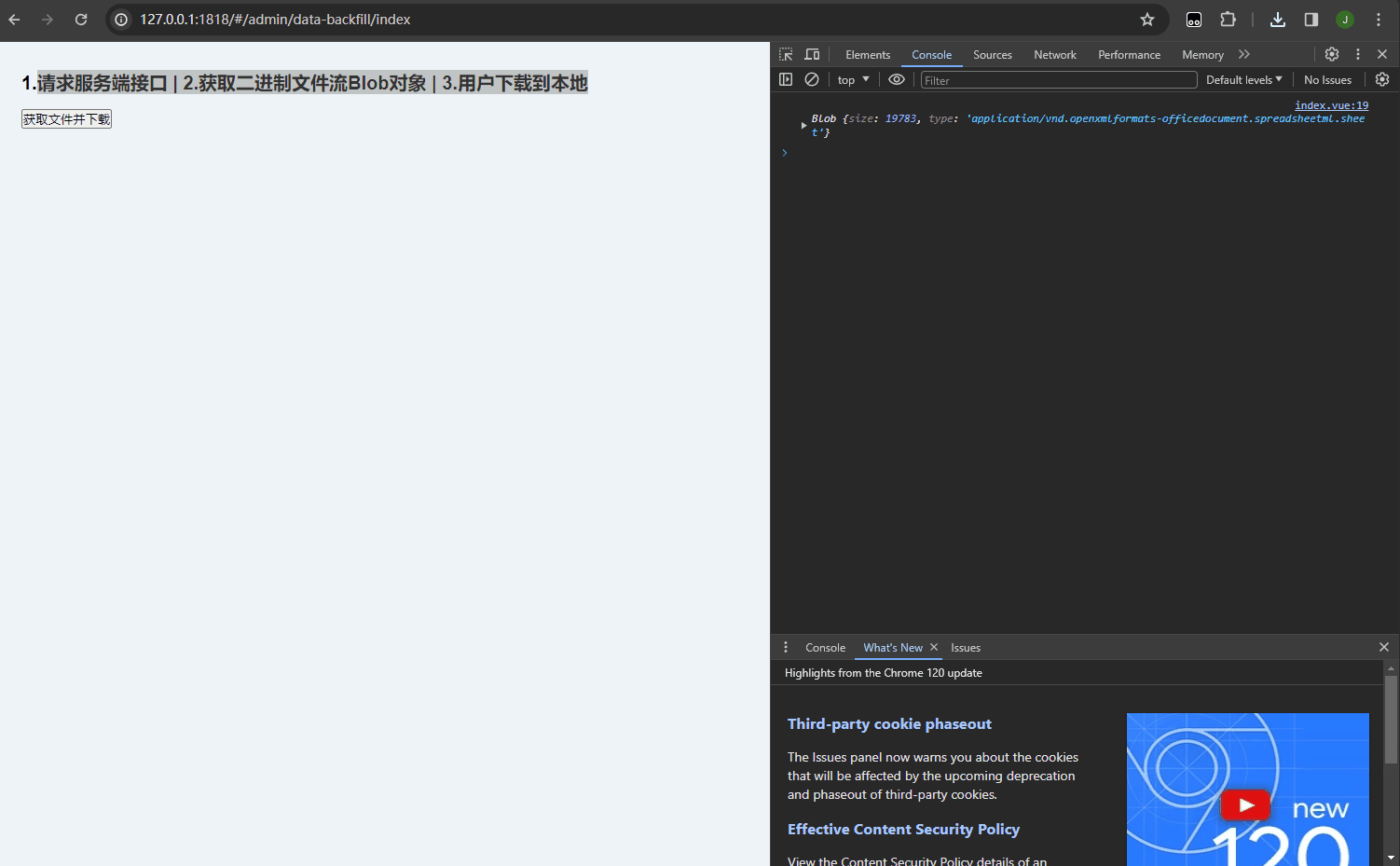
从上图我们可以看到,光下载 http 接口的响应数据就需要 3.14s(此时是8000条数据),而正常接口的下载时间一般是以毫秒为单位。所以需要优化。
解决思路
1. 首先是前端分页
首先,需要思考下这将近一万条数据如何在前端渲染的问题。肯定是不能一下子进行全部展示的。既然后端没有进行分页,那就前端来进行分页。
前端分页逻辑其实很简单:有分页的组件,拿来用就行。使用 数组的 slice 方法,对总数据进行分割,跳转到不同页时,根据 pageSize 和 limit 两个参数分割数组。
比较简单,就直接上代码了
// 前端分页逻辑
/**
* 该方法用于前端分页
* @param limit 每页条数
* @param currentPage 当前页
* @param tableData 总数据
*/
queryByPage(limit, currentPage, tableData) {
return tableData.slice((currentPage - 1) * limit, currentPage * limit)
}
进行前端分页后,只有第一次调用接口时会非常慢,之后进行跳转其他页码时,是不调用接口的,页面效果会很快。
不过这终究不是最终的解决方案,接口还是比较耗时,如果在进行其他操作后在调用该接口,仍然会非常慢,仍需继续优化。
2. 优化返回字段
从上图我们可以看到,造成接口时间长的主要原因是:ttfb 与 content download 的时间太长了,正常情况下,这哥俩的耗时应该是以毫秒为单位的。
不过,和后端同学沟通,目前的 TTFB 时间已经是优化过后的,本来是 十几秒 的时间,现在优化到 3秒左右,他那边目前没有好的再优化 TTFB 时间的方案。
那下一步就是优化 content download 的时间。
content download :收到响应的第一个字节,到接收完最后一个字节的时间,就是下载时间。即 下载 HTTP 响应的时间(包含头部和响应体)
通过看接口返回详情,我们可以很清晰的了解到:这个接口响应的资源很大,大概有7M(估算的,因为优化字段后资源大小仍然有 4M 左右,当时忘了看之前的资源大小)
看到这里,我们就能意识到:原来是接口返回的数据资源太大,导致下载时间长。 那么,我们该如何优化数据资源呢?
网上出现的比较多的是这两种方案:
- 1、移除重复脚本,精简和压缩代码,比如借助自动化构建工具 grunt、gulp 等。(不太熟悉,加上时间紧迫,就没了解)
- 2、压缩响应内容,服务器端启动 gzip 压缩,可以减少下载时间。
当时我向后端同学推荐了第二种方案:后端使用 gzip 压缩,前端处理数据,但不知为何,后端同学没采用这种方法。
不过,后端精简了返回的字段,把无用的字段统统删除,将返回的数据资源大小控制在了 4M 左右。
3. 最终优化(前端分页 + 后端分页)
我和后端同学又讨论了几种方案,但细细想过后又都一一否决了,最终定下来方案如下:
前端将分页参数传给后端,后端根据前端传的分页参数,返回 pageSize * limit 条数据。前端将数据缓存起来,调用当前页之前的数据就不用调用接口了。而且第一次加载的时候,返回的数据较少,content download 下载时间就会大大降低。
说实话,我有些不太理解,既然后端都要分页了,那为什么不按照正常的分页逻辑来呢?点击第几页就返回第几页的数据。对此,后端同学给我的解释是:这些数据没有落表,而且要大量计算。我不是特别理解,但后端坚持不用正常的分页逻辑,我也无可奈何,只能按照这个思路写前端逻辑。
PS:如果不是特殊需求,后端不进行分页的话,建议直接打一顿
前端分页逻辑已经写好了,代码在上面,主要问题是如何判断点击当前页后,前面的页码点击不调用接口,以及修改每页条数后,如何判断哪个页面之前不需要调用接口。
思路:
定义一个变量 clickedMaxPage,默认值为 1,用于储存当前页的页码点击的最大值。
考虑 页码变化事件、每页条数变化事件 对于 clickedMaxPage 的变化
// 当前页发生变化
// page: 当前页码
currentPageChange(page) {
// 如果 page > this.clickedMaxPage 调用接口,否则不需要
if (page > this.clickedMaxPage) {
this.clickedMaxPage = page
// 调用接口
return
}
// page <= this.clickedMaxPage
// 调用前端分页方法
}
// 每页条数发生变化
// size: 当前每页条数
sizeChangeHandle(size) {
/**
* 需要判断当前总条数是否大于分页条数,
* 如果大于,正常取余判断, 余数不为0,clickedMaxPage = 商 + 1,否则 clickedMaxPage = 商
* 如果小于等于 clickedMaxPage = 1
*/
if (this.data.length > size) {
// 获取余数
const remainder = this.data.length % size
// 获取商数
const result = parseInt((this.data.length / size) + '')
if (remainder === 0) {
this.clickedMaxPage = result
} else {
this.clickedMaxPage = result + 1
}
} else {
this.clickedMaxPage = 1
}
// 前端分页逻辑
}
总结
按照上面的方法,页面初始化的时候确实比之前快了很多,大概有一倍左右。不过直接跳转到最后一页,接口还是会有些缓慢。不过,对于上万条数据,也很少有人会直接跳转到最后一页进行搜索,毕竟上面也是有筛选条件可以进行筛选的。总而言之,也算是完成了性能优化。
前端性能方案有很多种,比如 SSR,只是目前暂时还未了解,以后慢慢掌握。
本篇文章介绍的方法只是其中比较特殊的一种,正常来说,我内心还是比较偏向于 gzip 压缩处理的。文章来源:https://www.toymoban.com/news/detail-416769.html
如果上面有不对的地方,欢迎评论留言,感谢支持。文章来源地址https://www.toymoban.com/news/detail-416769.html
到了这里,关于后端接口返回近万条数据,前端渲染缓慢,content Download 时间长的优化方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!