group by的基本语法
基本语法
select 列名1,... , 列名n from 表
group by 列名1,... , 列名n
什么是分组查询(一个字段)
分组,顾名思义,分成小组。简而言之就是就是把相同的数据分到一个组。
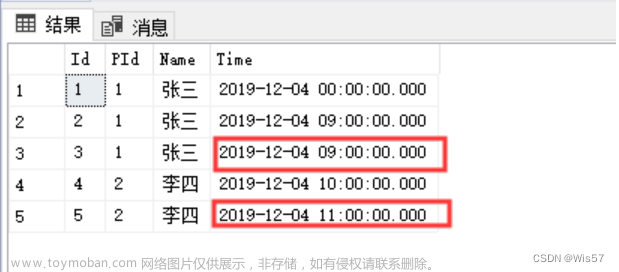
如下表(表名gb),里面有16条数据,前8条是狗狗,后8条是猫猫.
现在对name这个列进行分组查询
select name from gb group by name;
得到结果如下:
我们发现他把原始表分为了两个小组,狗狗小组和猫猫小组。从这可以看出分组查询就是把相同的数据分到一个组。
那么问题来了,我一直在说分组这个词,可是看见上面的结果明明是两行数据,哪里是组了,还不如说你这是去重得了(把重复的行筛选掉),虽然看似是两行数据(只有狗狗和猫猫两行),可实际上它是隐藏了,因为每个组里面都是相同的数据,所以它只显示一条数据,我们可以通过count()函数来统计每个组(也就是你看见的行)里面的个数,看一看每个组(行)里面到底包含了多少条数据。测试代码如下:
select name, count(name) as '每个组里的数量' from gb
group by name;
测试结果如下图:
通过结果我们发现狗狗组里面有8条数据,猫猫组里面也有8条数据。所以我才说它是组而不是行。因为这个组里面有很多一样的数据,它只显示一条,所以我们很容易就误认为他是普通的行了。(关于这个结果我们可以认为他是一个嵌套表,就像我们编程语言中的嵌套数组一样)(大的套小的,小的里面还套着小的,有点俄罗斯套娃的梗了)。
多个字段的分组查询
1.两个字段的分组查询
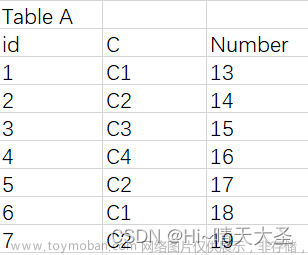
首先准备如下表(表名gb):其中有name字段(动物的名称),colour字段 (动物的颜色)
然后对该表的name和colour这两个字段进行分组聚合,代码如下:
select colour, name, count(*) as '数量' from gb
group by name, colour;
结果如下:
通过结果我们发现 两个字段进行分组和一个字段进行分组并无多大区别,两个字段分组就是要同时考虑两个列,两个列中都是一模一样的数据则分在同一个组中,就比如 黑色的狗狗是一个组、白色狗狗是一个组。 满足同一个动物名称的情况下还要满足动物的颜色,名称颜色都一样就是一个组的 。
2.三个字段及N个字段进行分组查询
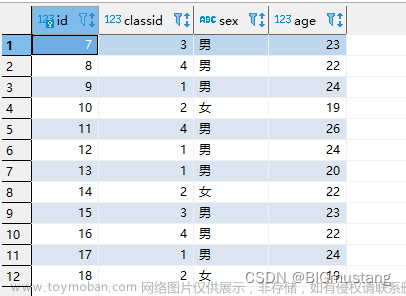
如下表(表名gb):其中有name字段(动物的名称),colour字段 (动物的颜色), type字段(动物的类型或者叫动物的品种)
对name,colour,type这三个字段进行分组聚合,代码如下:
select type, colour, name, count(*) as '数量' from gb
group by name, colour, type;
结果如下:
通过结果的发现,三个字段进行分组,那么就要同时考虑三个字段,首先考虑动物的名称name字段,它分为狗狗和猫猫两种组(注意: 这就是前面name分组的结果)。然后在考虑动物的颜色colour字段,狗狗有黑色和白色,猫猫有蓝色和黑色 , 他就分为了四种组(注意: 这就是前面name,colour分组的结果)。最后在考虑动物的类型type字段,黑色狗狗有a,b两个类型、白色狗狗有a,b两个类型、蓝色猫猫有a,b两个类型、黑色猫猫有a,b两个类型、它就分为了8种组(就是如上图的结果)。
总结 对N个字段进行分组聚合,那么同时要满足这N个字段,一层一层的往下分。
having子句的使用
基本语法
select 列名1,... , 列名n from 表
group by 列名1,... , 列名n
having 筛选规则
having是干什么的
其实having很好理解 他的功能与where是一样的,都是为了写条件语句进行筛选数据。但是SQL语法规定,对于group by之后的组结果,想要对其结果进行筛选,必须使用having关键字,不能使用where。所以我们可以把having看成group by的搭档就行了,见了group by 想要对其结果筛选,后面就使用having关键字。就像我们吃饭要用筷子,喝汤要用勺子,筷子和勺子都是吃饭的工具。having与where都是筛选的关键词,只是应用的场景不同而已。
演示
准备下表(表名gb):有动物名称name字段和动物颜色colour字段
先看看同一个动物中同种颜色的各有多少个
select name, colour, count(*) as '数量' from gb
group by name, colour;
结果
从结果中可以看出 黑色狗狗与白色狗狗各有4只,蓝色的猫猫有6只,黑色猫猫有2只。
然而现在我们只想看猫猫的数据,不想看狗狗的数据,所以现在我们就要对上图的结果进行筛选。
select name, colour, count(*) as '数量' from gb
group by name, colour
having name = '猫猫';
结果
所以通过having关键词我们就进行了对group by分组结果的筛选了,选出了我们想要的结果。
然而对此结果我们还是不太满意,我想要选出猫猫中数量 >=6 的组,测试代码如下:
select name, colour, count(*) as '数量' from gb
group by name, colour
having name = '猫猫' and count(*) >= 6;
结果如下:
通过上面sql语句发现,我们只是在筛选条件上增加了一个筛选条件 使用and 连接可以得出结果。但是这也引发一个新的问题。那就是在where后面我们写筛选条件好像没有用过聚合函数(如count函数等)当条件吧,然而having后面我们却使用了聚合函数(如count函数等)当条件,所以这里也有一个语法规定如下:
1.where后面的筛选规则是对整个表中的行进行筛选,所以不会直接使用聚合函数进行充当条件。
2.having后面是对group by分出的组的结果进行筛选,看似是对每一行进行筛选其实是对每一个组进行筛选,所以我们就可以 直接使用聚合函数充当条件。
分组查询select关键字后面列名书写的注意事项
SQL语法中规定, select关键字后面的列名 要么在group by 后面出现过,要么在selelct后面使用的聚合函数中出行过。没有出现过就不能使用。
如下表(表名gb):其中有动物的名称name字段。 文章来源:https://www.toymoban.com/news/detail-416841.html
文章来源:https://www.toymoban.com/news/detail-416841.html

如上如的sql语句 红色框书写的列名(select关键字后面的列名), 必须要在两个绿色框中出现过(聚合函数中 或 group by后 出现过),才能书写,没出现过就不能书写。文章来源地址https://www.toymoban.com/news/detail-416841.html
到了这里,关于玩转SQL语句之group by 多字段分组查询与having子句,一篇解决你的疑惑!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!