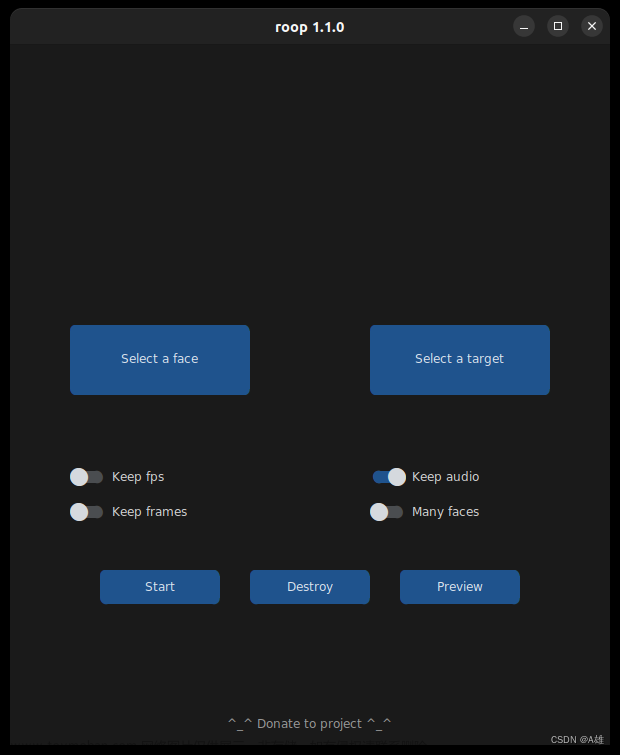
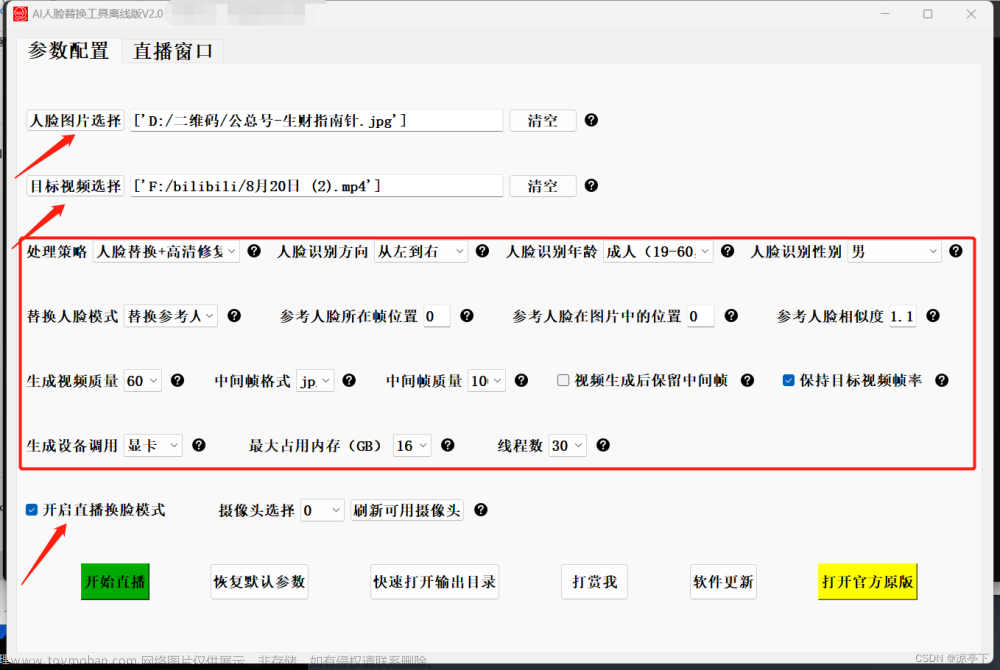
(十五)视频处理、不用事先训练
本文的代码的功能是:可以对人物视频进行操作,不用预先耗时训练模型,效率极高;
可进行视频处理,使用了人工智能的算法。
注:请移步最新博文(十八)…
一、主要功能:
以下的Python代码的功能:选择视频、主要包括:
1、对视频进行操作,并输出变换后的文件;
2、可以处理,在选择文件的对话框里可以选择多个文件,进行操作;
3、如果电脑有GPU,则会自动选择GPU处理,加快处理速度;
4、信息统计里面可以实时显示处理的各种统计信息;
5、视频处理完毕后自动进行音频的处理与合成。文章来源:https://www.toymoban.com/news/detail-417077.html
二、主要代码:
…文章来源地址https://www.toymoban.com/news/detail-417077.html
到了这里,关于(十五)视频换脸、无训练高速换脸、一张图片即可完成、批量处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!