1、ChatGLM-6B内容简单介绍
该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。
注:结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B可以实现的能力这是一个对话机器人,所以基本的问答,系统都支持。
官方提供的使用实例:
自我认知
提纲写作
文案写作
邮件助手
信息抽取
角色扮演
评论比较
旅游向导
运行界面

2、ChatGLM-6B模型实战
GLM模型GitHub代码地址
部署步骤如下:(注意使用的是Linux系统,本人数次尝试用Windows以失败告终)
# 新建chatglm环境
conda create -n chatglm python==3.8
# 激活chatglm环境
conda activate chatglm
# 安装PyTorch环境(根据自己的cuda版本选择合适的torch版本)
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
# 安装gradio用于启动图形化web界面
pip install gradio
# 安装运行依赖
pip install -r requirement.txt
#基于 Gradio 的网页版 Demo
python web_demo.py
#命令行 Demo
python cli_demo.py
网页版 Demo运行结果

命令行 Demo运行结果

值得注意的是: 显存够用下面这些不用管,当显存不够时(即GPU 显存有限低于13GB),尝试以量化方式加载模型的,需要添加代码.quantize(8) .quantize(4) :
int8精度加载,需要10G显存;
int4精度加载,需要6G显存;文章来源:https://www.toymoban.com/news/detail-417312.html
#将句子对列表传给tokenizer,就可以对整个数据集进行分词处理
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) #将文本转换为模型能理解的数字# 自动加载该模型训练时所用的分词器
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(6).cuda()#从checkpoint实例化任何模型,下载预训练模型
3、ChatGLM-6B Ptuning-可基于模型利用自己数据集实现模型微调
微调GitHub代码地址文章来源地址https://www.toymoban.com/news/detail-417312.html
- 运行微调除 ChatGLM-6B 的依赖之外,还需跟加安装以下依赖:
pip install transformers==4.27.1
pip install rouge_chinese nltk jieba datasets
- 下载数据集(当然也可以是自己需要待训练的数据集)
从 Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN 数据集,将解压后的 AdvertiseGen 目录放到本目录下,如下图所示。

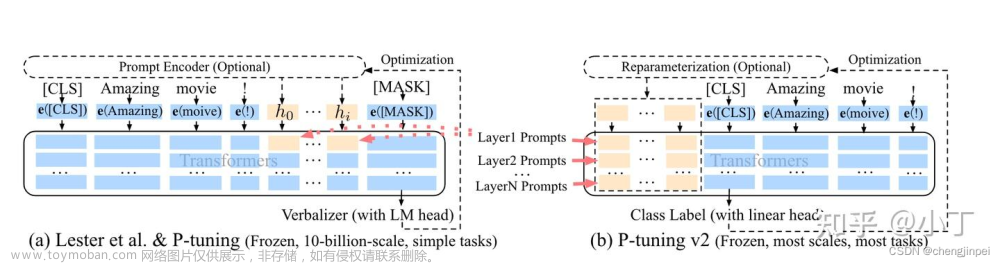
- train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
官方给出的实验设置如下:

简单修改后执行bash train.sh运行程序即可
到了这里,关于学习实践ChatGLM-6B(部署+运行+微调)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!