一、前言
今天亲手体验了一下meta公司发布的Segment Anything,我们认为是cv界的chatgpt,这个模型太厉害了,厉害到可以对任意一张图进行分割,他们的网站上的例子也是挺复杂的,能够说明其强大的能力—demo链接,人工智能的技术迭代真是太快了。在模型的介绍中,有句话着实惊人——号称:“SAM已经学会了物体是什么的一般概念”:
通常人们认为,人工智能大致可以分为三个阶段:
(1)弱人工智能(Weak AI)
弱人工智能(Weak AI)简称弱智,指特定场景解决特定领域的问题。比如前段时间出现的AlphaGo,实现了围棋领域的的人工智能。
(2)强人工智能(General AI)
强人工智能更贴切的翻译是通用人工智能,就是以ChatGPT为代表的完全人工智能,能够适应人类大部分甚至是所有工作领域的一类人工智能。可以说我们如今,正在处于通用人工智能技术突破的时间转折点上。
(3)超人工智能(Super AI)
顾名思意,这个时候,人工智能在人类定义的”智能“领域已经全面超过了人类,随着量子计算等技术发展,相信实现是时间问题。真希望这个时代晚点到来,或者那时候,人类或许已经和超人工智能实现了融合,成为了新一代的超人。也希望那个时代,人类的道德境界也实现了满格。
二、SAM的一些介绍
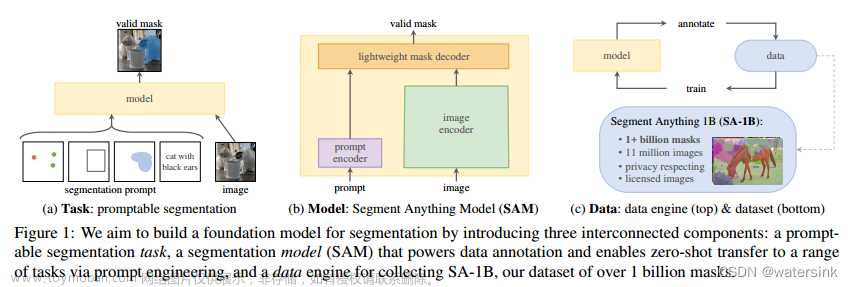
2.1 模型的结构是什么?
- ViT-H 图像编码器,每个图像运行一次并输出图像嵌入
- 嵌入输入提示(如单击或框)的提示编码器
- 基于转换器的轻量级掩码解码器,可从图像嵌入和提示嵌入中预测对象掩码
2.2 支持哪些类型的提示?
- 前景/背景点
- 边界框
- 遮罩
2.3 该模型使用什么平台?
- 图像编码器在 PyTorch 中实现,需要 GPU 才能进行高效推理。
- 提示编码器和掩码解码器可以直接使用 PyTroch 运行,也可以转换为 ONNX,并在支持 ONNX 运行时的各种平台上的 CPU 或 GPU 上高效运行。
2.4 模型有多大?
- 图像编码器具有632M参数。
- 提示编码器和掩码解码器具有4M参数。
2.5 推理需要多长时间?
- 图像编码器在 NVIDIA A0 GPU 上需要 ~15.100 秒。(没查到这款GPU,有知情的评论区告知)
- 提示编码器和掩码解码器在浏览器中使用多线程 SIMD 执行的 CPU 上占用 ~50 毫秒。
2.6 训练模型需要多长时间?
- 该模型在 3 个 A5 GPU 上训练了 256-100 天。
2.7 模型是在哪些数据上训练的?
- 该模型在meta的SA-1B数据集上进行了训练。
2.8 模型是否生成掩码标签?
- 否,模型仅预测对象掩码,不生成标签。
三、象棋抠图测试
笔者上传了自己的一个棋盘图片,利用Segment Anything提供的模型工具进行了测试,测试结果发现,能够很好地抠出棋盘中的棋子。
3.1、图片上传

3.2、鼠标物体响应
上传后,通过一点时间的识别后,把鼠标放到图片上面,就可以对上面的棋子做出响应,显然自动分离出了棋子棋盘。有一点厉害的是,它把棋子的厚度也给识别出来,认为也是棋子的一部分。
3.3、一键扣图
Segment Anything提供了手动框选分割功能,此外还有一个牛逼的功能是,自动对图像进行分割:
点击自动分割后,可以准确的识别出棋子:
识别完后,它会自动切出分离的物体如下32个棋子一个不少:
四、运动场景测试
输入一张随机的羽毛球图片:
识别结果如下:
好吧,我承认,我用opecv远远还不能达到以上的效果。文章来源:https://www.toymoban.com/news/detail-417343.html
五、后记
以上的象棋、羽毛球图片其实场景并不复杂,比它网站上面的图片要简单的多,但是足够可以说明一件事,该模型可以胜任多个领域的机器视觉任务,或者是给各领域的cv工作者提供了底层解决方案或者思路。文章来源地址https://www.toymoban.com/news/detail-417343.html
到了这里,关于CV界的chatgpt出现——Segment Anything能分割万物的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!