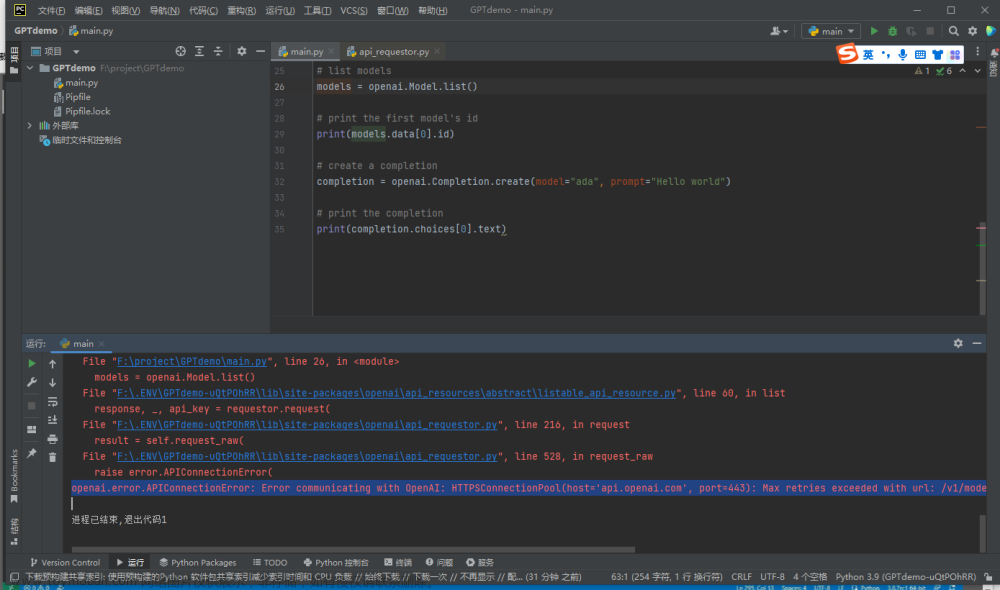
获取chatgpt的models列表
curl https://api.openai.com/v1/models \
-H "Authorization: Bearer $OPENAI_API_KEY"
{
"data": [
{
"id": "model-id-0",
"object": "model",
"owned_by": "organization-owner",
"permission": [...]
},
{
"id": "model-id-1",
"object": "model",
"owned_by": "organization-owner",
"permission": [...]
},
{
"id": "model-id-2",
"object": "model",
"owned_by": "openai",
"permission": [...]
},
],
"object": "list"
}
检索模型
检索模型实例,提供有关模型的基本信息,如所有者和权限。
curl https://api.openai.com/v1/models/text-davinci-003 \
-H "Authorization: Bearer $OPENAI_API_KEY"
{
"id": "text-davinci-003",
"object": "model",
"created": 1669599635,
"owned_by": "openai-internal",
"permission": [
{
"id": "modelperm-eX6Zax2krvLf9WtfO3NN9YJh",
"object": "model_permission",
"created": 1680551675,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
],
"root": "text-davinci-003",
"parent": null
}
对答(Completions)
curl https://api.openai.com/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0
}'
{
"id": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7",
"object": "text_completion",
"created": 1589478378,
"model": "text-davinci-003",
"choices": [
{
"text": "\n\nThis is indeed a test",
"index": 0,
"logprobs": null,
"finish_reason": "length"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 7,
"total_tokens": 12
}
}
Request body
- model:要使用的模型的ID。您可以使用List models API查看所有可用的模型,或者查看我们的模型概述以了解它们的描述。
- prompt:生成完成的提示,编码为字符串、字符串数组、标记数组或标记数组数组。 请注意,<|endoftext|> 是模型在训练期间看到的文档分隔符,因此如果未指定提示,模型将生成新文档的开头。
- suffix:插入文本完成后出现的后缀。
- max_tokens:完成时生成的最大令牌数。 您的提示的令牌计数加上 max_tokens 不能超过模型的上下文长度。大多数模型的上下文长度为 2048 个标记(最新模型除外,它支持 4096)。
- temperature:使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。 我们通常建议改变这个或 top_p 但不是两者都改变。
- top_p:一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只考虑构成前 10% 概率质量的标记。我们通常建议更改此值或温度,但不要同时更改两者。
- n:为每个提示生成多少完成。 注意:因为这个参数会产生很多完成,它会很快消耗你的令牌配额。请谨慎使用并确保您对 max_tokens 和停止进行了合理的设置。
- stream:是否回流部分进度。如果设置,令牌将在可用时作为纯数据服务器发送事件发送,流由数据终止:[DONE] 消息。
- logprobs:在 logprobs 上包括对数概率最有可能的标记,以及所选标记。例如,如果 logprobs 为 5,则 API 将返回 5 个最有可能的标记的列表。 API 将始终返回采样令牌的 logprob,因此响应中最多可能有 logprobs+1 个元素。logprobs 的最大值为 5。如果您需要更多,请通过我们的帮助中心联系我们并描述您的用例。
- echo:除了完成之外回显提示
- stop:API 将停止生成更多token的最多 4 个序列。返回的文本将不包含停止序列。
- presence_penalty:-2.0 和 2.0 之间的数字。正值会根据到目前为止是否出现在文本中来惩罚新标记,从而增加模型谈论新主题的可能性。
- frequency_penalty:-2.0 和 2.0 之间的数字。正值会根据新标记在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性。
- best_of:在服务器端生成 best_of 完成并返回“最佳”(每个标记具有最高对数概率的那个)。无法流式传输结果。 当与 n 一起使用时,best_of 控制候选完成的数量,n 指定返回多少 - best_of 必须大于 n。 注意:因为这个参数会产生很多完成,它会很快消耗你的令牌配额。请谨慎使用并确保您对 max_tokens 和停止进行了合理的设置。
- logit_bias:修改指定标记出现在完成中的可能性。 接受一个 json 对象,该对象将标记(由 GPT 标记器中的标记 ID 指定)映射到从 -100 到 100 的相关偏差值。您可以使用此标记器工具(适用于 GPT-2 和 GPT-3)来转换文本到令牌 ID。从数学上讲,偏差会在采样之前添加到模型生成的对数中。确切的效果因模型而异,但 -1 和 1 之间的值应该会减少或增加选择的可能性;像 -100 或 100 这样的值应该导致相关令牌的禁止或独占选择。 例如,您可以传递 {“50256”: -100} 以防止生成 <|endoftext|> 标记。
- user:代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
聊天(Chat)
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
Request body
-
model:要使用的模型的ID。您可以使用List models API查看所有可用的模型,或者查看我们的模型概述以了解它们的描述。
-
messages:以聊天格式生成聊天完成的消息。
-
max_tokens: 聊天完成时生成的最大令牌数。 输入标记和生成标记的总长度受模型上下文长度的限制。
-
temperature:使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。 我们通常建议改变这个或 top_p 但不是两者都改变。
-
top_p:一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只考虑构成前 10% 概率质量的标记。我们通常建议更改此值或温度,但不要同时更改两者。
-
n:为每个提示生成多少完成。 注意:因为这个参数会产生很多完成,它会很快消耗你的令牌配额。请谨慎使用并确保您对 max_tokens 和停止进行了合理的设置。
-
stream:是否回流部分进度。如果设置,令牌将在可用时作为纯数据服务器发送事件发送,流由数据终止:[DONE] 消息。
-
stop:API 将停止生成更多token的最多 4 个序列。返回的文本将不包含停止序列。
-
presence_penalty:-2.0 和 2.0 之间的数字。正值会根据到目前为止是否出现在文本中来惩罚新标记,从而增加模型谈论新主题的可能性。
-
frequency_penalty:-2.0 和 2.0 之间的数字。正值会根据新标记在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性。
-
logit_bias:修改指定标记出现在完成中的可能性。 接受一个 json 对象,该对象将标记(由标记器中的标记 ID 指定)映射到从 -100 到 100 的关联偏差值。从数学上讲,偏差会在采样之前添加到模型生成的 logits 中。确切的效果因模型而异,但 -1 和 1 之间的值应该会减少或增加选择的可能性;像 -100 或 100 这样的值应该导致相关令牌的禁止或独占选择。
-
user:代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
message详细说明
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
主要输入是消息参数。消息必须是一个消息对象数组,其中每个对象都有一个角色(“系统”、“用户”或“助手”)和内容(消息的内容)。对话可以短至 1 条消息或填满许多页面。
通常,对话首先使用系统消息进行格式化,然后是交替的用户和助理消息。
系统消息有助于设置助手的行为。在上面的例子中,助手被指示“你是一个有用的助手”。
用户消息有助于指导助手。它们可以由应用程序的最终用户生成,或由开发人员设置为指令。
助手消息帮助存储先前的响应。它们也可以由开发人员编写,以帮助提供所需行为的示例。
当用户指令引用先前的消息时,包括对话历史记录会有所帮助。在上面的示例中,用户的最后一个问题是“它在哪里播放?” 仅在有关 2020 年世界大赛的先前消息的上下文中才有意义。由于模型对过去的请求没有记忆,因此必须通过对话提供所有相关信息。如果对话不适合模型的令牌限制,则需要以某种方式缩短它。
响应格式
{
'id': 'chatcmpl-6p9XYPYSTTRi0xEviKjjilqrWU2Ve',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-3.5-turbo',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': 'The 2020 World Series was played in Arlington, Texas at the Globe Life Field, which was the new home stadium for the Texas Rangers.'},
'finish_reason': 'stop',
'index': 0
}
]
}
在 Python 中,可以使用 提取助手的回复response['choices'][0]['message']['content']。
每个回复都将包含一个finish_reason. 的可能值为finish_reason:
-
stop:API 返回完整的模型输出 -
length:由于max_tokens参数或令牌限制,模型输出不完整 -
content_filter:由于我们的内容过滤器中的标记而省略了内容 -
null: API 响应仍在进行中或不完整
指导聊天模型
指导模型的最佳实践可能因模型版本而异。以下建议适用于 gpt-3.5-turbo-0301,可能不适用于未来的模型。
许多对话以系统消息开始,以温和地指示助手。例如,这是用于 ChatGPT 的系统消息之一:
You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible. Knowledge cutoff: {knowledge_cutoff} Current date: {current_date}
一般来说,gpt-3.5-turbo-0301对系统消息的关注度不高,因此重要的说明往往放在用户消息中比较好。
如果模型没有生成您想要的输出,请随意迭代并尝试潜在的改进。您可以尝试以下方法:
- 让你的指示更明确
- 指定您想要答案的格式
- 在确定答案之前让模型逐步思考或讨论利弊
除了系统消息之外,温度和最大令牌是开发人员必须影响聊天模型输出的众多选项中的两个。对于温度,较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。在 max tokens 的情况下,如果要将响应限制为特定长度,可以将 max tokens 设置为任意数字。这可能会导致问题,例如,如果您将最大标记值设置为 5,因为输出将被切断并且结果对用户没有意义。
**文章来源地址https://www.toymoban.com/news/detail-417443.html文章来源:https://www.toymoban.com/news/detail-417443.html
让chatgpt成为心理咨询师,测试:
**
{
"chatGPT": {
"max_tokens": 500,
"messages": [
{
"content": "假如你是一个专业的cbt心理咨询师,那么我们可以试着沟通下么",
"role": "system"
},
{
"content": "我很伤心",
"role": "user"
},
{
"role": "assistant",
"content": "我很抱歉听到这个消息,可能这种情况会让你感到很难过和不安。但是,我很高兴你愿意通过和我聊天来解决问题。你可以告诉我闹矛盾的原因吗?我们可以一起找到解决问题的方法。"
},
{
"content": "我和朋友闹矛盾了",
"role": "user"
},
{
"role": "assistant",
"content": "抱歉听到你和朋友间的矛盾。首先,请告诉我发生了什么导致你们产生矛盾?你可以告诉我你的感受和想法,我会听到你说话并试着理解你的处境。"
},
{
"content": "我的朋友抢了我的饼干,我没有饼干吃了,我很伤心",
"role": "user"
},
{
"role": "assistant",
"content": "感谢你与我分享了你的矛盾。听起来你很生气和伤心,你可以说出更多关于你的感受和情绪吗?很明显,你的朋友的行为让你感到不愉快。在这种情况下,如果你觉得不愉快,最好的解决方案是直接与他们交流。在谈话中,可以试着用“I”语言描述你的感受,并告诉你的朋友你的看法和要求他道歉。这可能有助于你们在未来更好地沟通和解决矛盾。"
},
{
"content": "我今天抢了他的饼干,并且喊了一群人打了他一顿,我现在心情好多了",
"role": "user"
},
{
"role": "assistant",
"content": "抱歉,我必须指出,这样的行为是完全不可取的,它不仅不能解决问题,反而会使事情恶化。在任何情况下,使用暴力都不是一个好的解决方案。这些行为可能会使情况更加恶化,并破坏你与你的朋友关系,导致更多的矛盾和困难。我建议你尽快与你的朋友联系,并对你的行为做出诚恳的道歉。此外,作为一个cbt心理咨询师,我建议你探索新的方法来处理冲突,并学习更加健康和有效的沟通技巧以及解决问题的方法。"
},
{
"content": "我知道我错了,但是我就是很恨他,你就不能安慰安慰我嘛?",
"role": "user"
},
{
"role": "assistant",
"content": "我了解这种情况可能让你感到非常不安,而且你的情绪也非常激动。我可以理解你对你的朋友感到愤怒和受到伤害。但是,如何处理这种情绪很重要。我们不能让情绪控制我们的行为。作为一个cbt心理咨询师,我可以给你一些建议来帮助你控制你的情绪和应对这种矛盾。\n\n首先,你可以试着深呼吸,冷静下来,花一些时间思考自己的想法和感受。同时,也可以试着快速审视你自己的想法,问问自己这些想法是否基于真实的事件和事实。在这个过程中,你也可以试着寻找一些积极的想法,例如“我有朋友的支持”,或“我可以试着寻求解决方案”。\n\n最后,我想再强调一次,使用暴力不是一个有效的解决方案,它甚至会使情况更加恶化。如果你需要更多的帮助和支持,我建议你寻求专业心理咨询师的帮助,他们会帮助你更好地处理你的情绪和问题。"
},
{
"content": "好吧,我已经对我的朋友道歉了,我们又和好了,谢谢你!",
"role": "user"
},
{
"role": "assistant",
"content": "我很高兴听到你已经与你的朋友和好了。道歉是一个良好的开始,它表明你愿意采取行动来解决问题和修复你们的友谊。记得,沟通和理解是解决问题和改善关系的关键。如果你在未来遇到类似的问题,请记得采取积极的措施,试着去理解彼此和寻求合适的解决方案。如果你需要更多的帮助和支持,随时都可以找我聊天。谢谢你与我分享你的情况!"
}
],
"model": "gpt-3.5-turbo",
"temperature": 1.0,
"user": "user123"
}
}
到了这里,关于chatgpt的api介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!