完整代码位置https://gitee.com/chuge325/base_machinelearning.git
这里还参考了tensorflow的官方文档
但是由于是pytorch训练的差别还是比较大的,经过多次尝试完成了训练
硬件是两张v100
1超参数训练代码
这个代码可以查看每次训练的loss曲线和超参数的对比信息

import pandas as pd
import torch
from utils.DataLoader import MNIST_data
from torchvision import transforms
from utils.DataLoader import RandomRotation,RandomShift
from model.AlexNet import Net
# from model.Net import Net
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.autograd import Variable
from torch.utils.tensorboard import SummaryWriter
from tensorboard.plugins.hparams import api as hp
from sklearn.model_selection import ParameterSampler
train_df = pd.read_csv('../datasets/digit-recognizer/train.csv')
n_train = len(train_df)
n_pixels = len(train_df.columns) - 1
n_class = len(set(train_df['label']))
# 定义超参数搜索空间
HP_LEARNING_RATE = hp.HParam('learning_rate', hp.RealInterval(1e-4, 1e-2))
HP_BATCH_SIZE = hp.HParam('batch_size', hp.Discrete([64, 128]))
HP_EPOCH = hp.HParam('epoch', hp.Discrete([50,100]))
METRIC_ACCURACY = hp.Metric('accuracy')
# 定义超参数搜索空间
param_dist = {
'lr': [0.001, 0.003,0.01 ,0.1],
'batch_size': [64,128],
'num_epochs': [50,100]
}
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1)% 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader),
loss.item()))
exp_lr_scheduler.step()
writer.add_scalar('Loss/train', loss/len(train_loader), epoch)
writer.flush()
def evaluate(data_loader):
model.eval()
loss = 0
correct = 0
for data, target in data_loader:
data, target = Variable(data, volatile=True), Variable(target)
if torch.cuda.is_available():
data = data.cuda()
target = target.cuda()
output = model(data)
loss += F.cross_entropy(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
loss /= len(data_loader.dataset)
writer.add_scalar('accuracy/train', correct / len(data_loader.dataset), epoch)
writer.flush()
print('\nAverage loss: {:.4f}, Accuracy: {}/{} ({:.3f}%)\n'.format(
loss, correct, len(data_loader.dataset),
100. * correct / len(data_loader.dataset)))
return correct / len(data_loader.dataset)
hparams_dir='logs/hparam_tuning'
hparams_writer = SummaryWriter(hparams_dir)
# 进行随机超参数搜索
param_list = list(ParameterSampler(param_dist, n_iter=20))
model = Net()
criterion = nn.CrossEntropyLoss()
for params in param_list:
hparams_dict ={
HP_LEARNING_RATE.name :params["lr"],
HP_BATCH_SIZE.name :params['batch_size'],
HP_EPOCH.name :params['num_epochs']
}
batch_size = params['batch_size']
train_dataset = MNIST_data('../datasets/digit-recognizer/train.csv', n_pixels =n_pixels,transform= transforms.Compose(
[transforms.ToPILImage(), RandomRotation(degrees=20), RandomShift(3),
transforms.ToTensor(), transforms.Normalize(mean=(0.5,), std=(0.5,))]))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True)
logdir = "logs/" + 'epoch{0}_lr{1}_batch_size{2}.pth'.format(params['lr'],params['num_epochs'],params['batch_size'])
writer = SummaryWriter(logdir)
optimizer = optim.Adam(model.parameters(), lr=params['lr'])
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
n_epochs = params['num_epochs']
for epoch in range(n_epochs):
train(epoch)
accuracy=evaluate(train_loader)
if epoch==n_epochs-1:
hparams_writer.add_hparams(hparams_dict,{'Accuracy':accuracy})
torch.save(model.state_dict(), 'epoch{0}_lr{1}_batch_size{2}.pth'.format(params['num_epochs'],params['lr'],params['batch_size']))
writer.close()
hparams_writer.close()
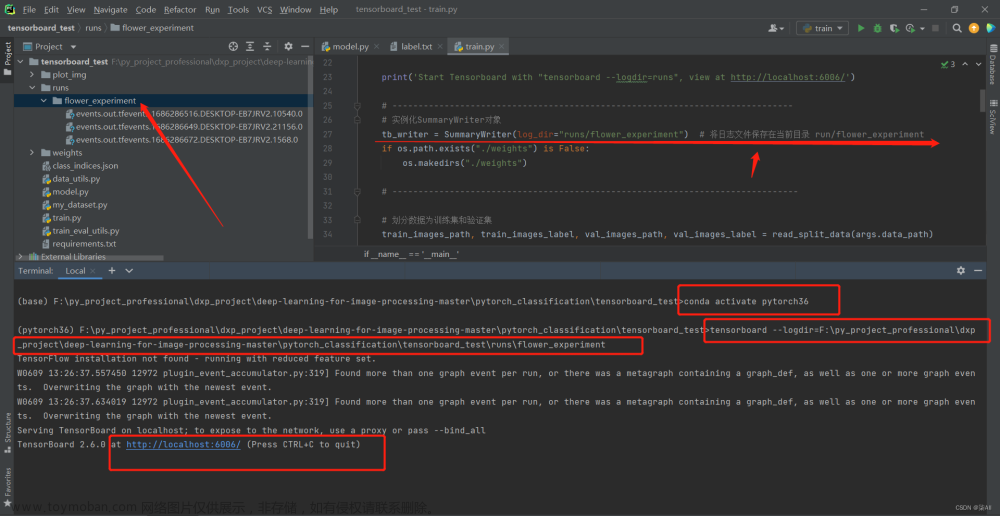
2远端电脑启动tensorboard
tensorboard --logdir logs
如果您的 TensorBoard 日志存储在远程服务器上,但您无法通过本地计算机上的浏览器访问它,可能是由于防火墙或网络设置的限制导致的。以下是一些可能的解决方案:
使用 SSH 隧道:如果您无法直接访问远程服务器上的 TensorBoard 日志,请考虑使用 SSH 隧道来建立本地和远程服务器之间的安全连接。在终端中使用以下命令建立 SSH 隧道:
ssh -L 6006:localhost:6006 username@remote_server_ip
其中 username 是您在远程服务器上的用户名,remote_server_ip 是远程服务器的 IP 地址。然后,在本地计算机上打开浏览器并访问 http://localhost:6006 即可访问 TensorBoard 日志。文章来源:https://www.toymoban.com/news/detail-417995.html
如果您使用的是 Windows 操作系统,可以使用 PuTTY 或其他 SSH 客户端来建立 SSH 隧道。
实例文章来源地址https://www.toymoban.com/news/detail-417995.html
到了这里,关于使用Tensorboard多超参数随机搜索训练的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!