一、opencv模块的使用
1、简介
opencv-python是一个python绑定库,旨在解决计算机视觉问题。使用opencv模块,可以实现一些对图片和视频的操作。
2、安装
安装opencv之前需要先安装numpy, matplotlib。然后使用pip安装opencv库即可。
3、导入
使用import cv2进行导入即可,需要注意的是cv2读取图片的颜色通道是BGR(蓝绿红)。
4、使用
使用cv2.imread()接收读取的图片,此处需要注意的是读取路径必须为英文。
cat = cv2.imread("cat1.png")
使用cv2.imshow()函数显示读取的图片。
cv2.imshow("cat", cat)
其中,函数内的第一个参数为显示图片窗口左上角的名字,第二个参数为接收读取的图片。
注意:在调用显示图像的API后,要调用cv2.waitKey()给图像绘制留下时间,否则窗口会出现无响应情况,并且图像无法显示出来。
cv2.waitKey(0)
其中,函数内的意思是等待键盘输入的时间,单位毫秒,如果为0则无限等待。
最后,使用cv2.destroyAllWindows()释放内存。
cv2.destroyAllWindows()
显示图像结果如下。

二、实现简单的人脸识别
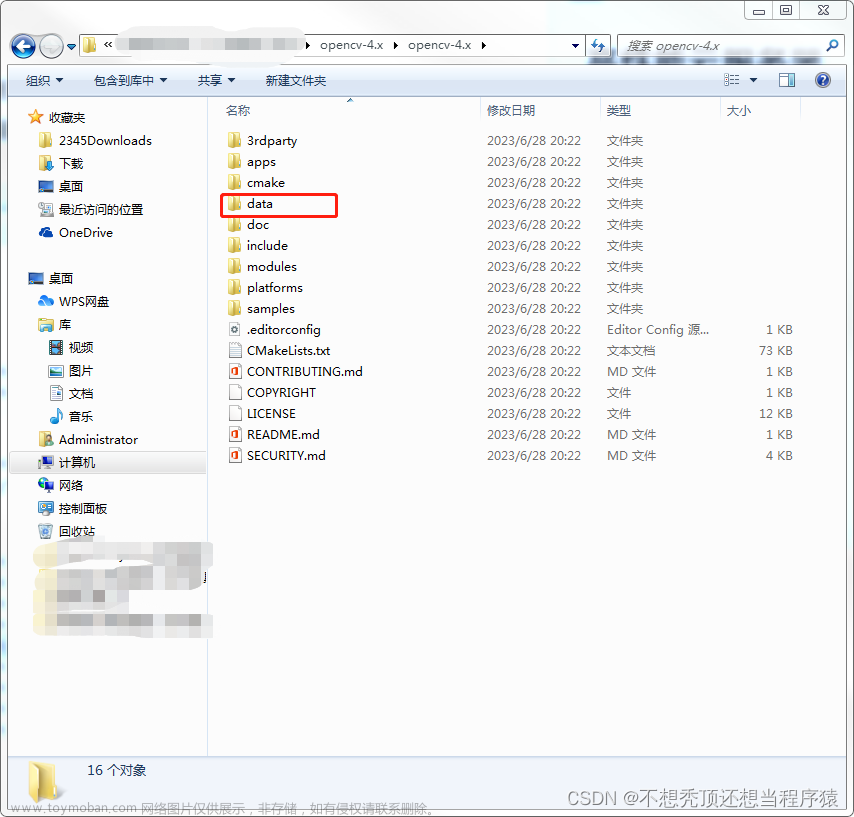
1、下载人类特征数据
首先在github网站下载开源人脸特征数据。网址:opencv/data at 4.x · opencv/opencv · GitHub

选择如上文件

选择人脸数据进行下载。
2、简单的人脸识别代码
首先使用cv2.imread()接收要读取的图片。
yoogni = cv2.imread("myq.jpg")
CascadeClassifier是opencv下objdetect模块中用来做目标检测的级联分类器的一个类。传入人脸特征数据,返回识别出的人脸对象。
detector = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
使用detectMultiScale()接收返回检测出的人脸对象。
face_zone = detector.detectMultiScale(yoogni)
打印接收的对象。
print(face_zone)
输出结果如下:

输出的为检测的人类区域。
3、在图上绘制识别出的人脸区域
使用cv2.rectangle()绘制出识别成功的人脸区域。
for x, y, w, h in face_zone:
cv2.rectangle(yoogni, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 255))
其中pt1是左上角坐标,pt2是右下角坐标,w是识别区域的宽,h是识别区域的高。颜色选择的是红色。
使用cv2.imshow()函数显示绘制完成的图片。
cv2.imshow("myq",yoogni)
输出结果如下:

三、进行多个人脸识别
在进行一张图片的多个人脸识别时,常常会出现识别错误的情况,如下图。

所以在识别时进行参数的调整。
face_zone = detector.detectMultiScale(myq, scaleFactor=1.3, minNeighbors=5)
scaleFactor表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%,此处调整为1.3。
minNeighbors表示构成检测目标的相邻矩形的最小个数(默认为3个)。该参数指定每一个候选矩形边界框需要有多少相邻的检测点,此处调整为5。
输出结果如下。

可以看出,检测精度明显上升。
四、进行视频人脸识别
本周在图片人脸识别的基础上进行扩展,进行视频的人脸识别。
1、视频捕获
首先进行视频捕获。
cap = cv2.VideoCapture("video2.mp4")
videocapture是按帧读取视频,就是读取视频里的图片,这个函数返回一张图片和一个布尔类型的值,布尔类型的值表示还有没有下一帧。
flag, frame = cap.read()
print(flag, frame.shape)
此时frame是第一帧图片,frame.shape输出的是图片维度。输出结果如下:

传入人脸特征数据
detector = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
2、将图像转为黑白影像再进行人脸识别
因为在识别人脸的时候,黑白和彩色不影响识别,所以为了运行速度更快,可以将识别时候的视频转为黑白。
gray = cv2.cvtColor(luo, code=cv2.COLOR_BGR2GRAY)
对黑白图像进行人脸识别
face_zone = detector.detectMultiScale(gray)
3、对视频进行人脸识别
首先要使用while语句进行判别,判断视频是否读到最后一帧。返回全部帧,使用isOpened函数判断视频是否还打开。
while cap.isOpened():
在while语句中,首先按帧读取视频。
flag, frame = cap.read()
由于原视频过大,所以将视频重新调整一下大小,使用luo接收返回值。
luo = cv2.resize(frame, dsize=(640, 360))
再将图片转为黑白色,并进行人脸识别。
gray = cv2.cvtColor(luo, code=cv2.COLOR_BGR2GRAY)
face_zone = detector.detectMultiScale(gray)
在按帧绘制出识别区域。
for x, y, w, h in face_zone:
cv2.rectangle(luo, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 255))
写判断语句,当视频播放到最后一帧时退出循环。
if not flag:
break
显示视频。
cv2.imshow("me", luo)
下面判断语句的意思是,等待10毫秒,如果用户没有摁下q键,就显示下一帧视频,并且cv2只读了图片没有读声音。及摁下q键退出视频。
if ord("q") == cv2.waitKey(20):
break
以上代码均写在while语句中。下面释放内存。
cv2.destroyAllWindows()
cap.release()
输出结果如下。

文章来源地址https://www.toymoban.com/news/detail-418266.html
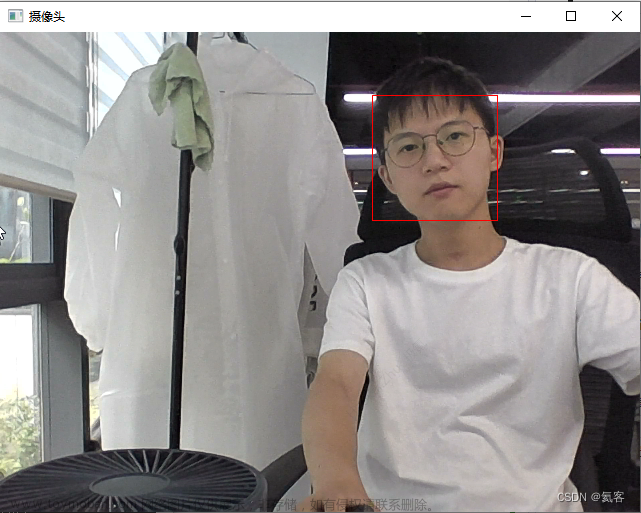
五、进行摄像头人脸识别
1、调取本地摄像头
还是使用videocapture函数,参数为0调取本地摄像头。
cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)
2、人脸识别
与上一节的人脸识别代码一样,输出结果如下。

文章来源:https://www.toymoban.com/news/detail-418266.html
3、保存视频
获取宽高,方便写入视频,因为转换为整形数字时可能会把小数点后几位截走,所以+1,视频大一点可以,小一点不行。
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) + 1
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) + 1
函数内第一个参数是视频名字;第二个是视频编码,及保存的视频格式;第三个是一秒几帧,第四个是视频的高宽。此处保存的视频名字为me,视频为avi格式。
vw = cv2.VideoWriter("me.avi", cv2.VideoWriter_fourcc("M", "P", "4", "2"), 24, (w, h))
在上一节人脸识别的while语句中,
cv2.imshow("me", frame)
这一句代码后面,判断摄像头录制是否结束。
if not flag:
break
如果视频没结束,把这一帧写入视频。
vw.write(frame)
保存结果如下。


到了这里,关于使用opencv实现简单的人脸识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!