📢作者: 小小明-代码实体
📢博客主页:https://blog.csdn.net/as604049322
📢欢迎点赞 👍 收藏 ⭐留言 📝 欢迎讨论!
今天我们将研究pandas如何使用openpyxl引擎读取xlsx格式的Excel的数据,并考虑以面向过程的形式简单的自己实现一下。
截止目前本人所使用的pandas和openpyxl版本为:
- pandas:1.5.2
- openpyxl:3.0.10
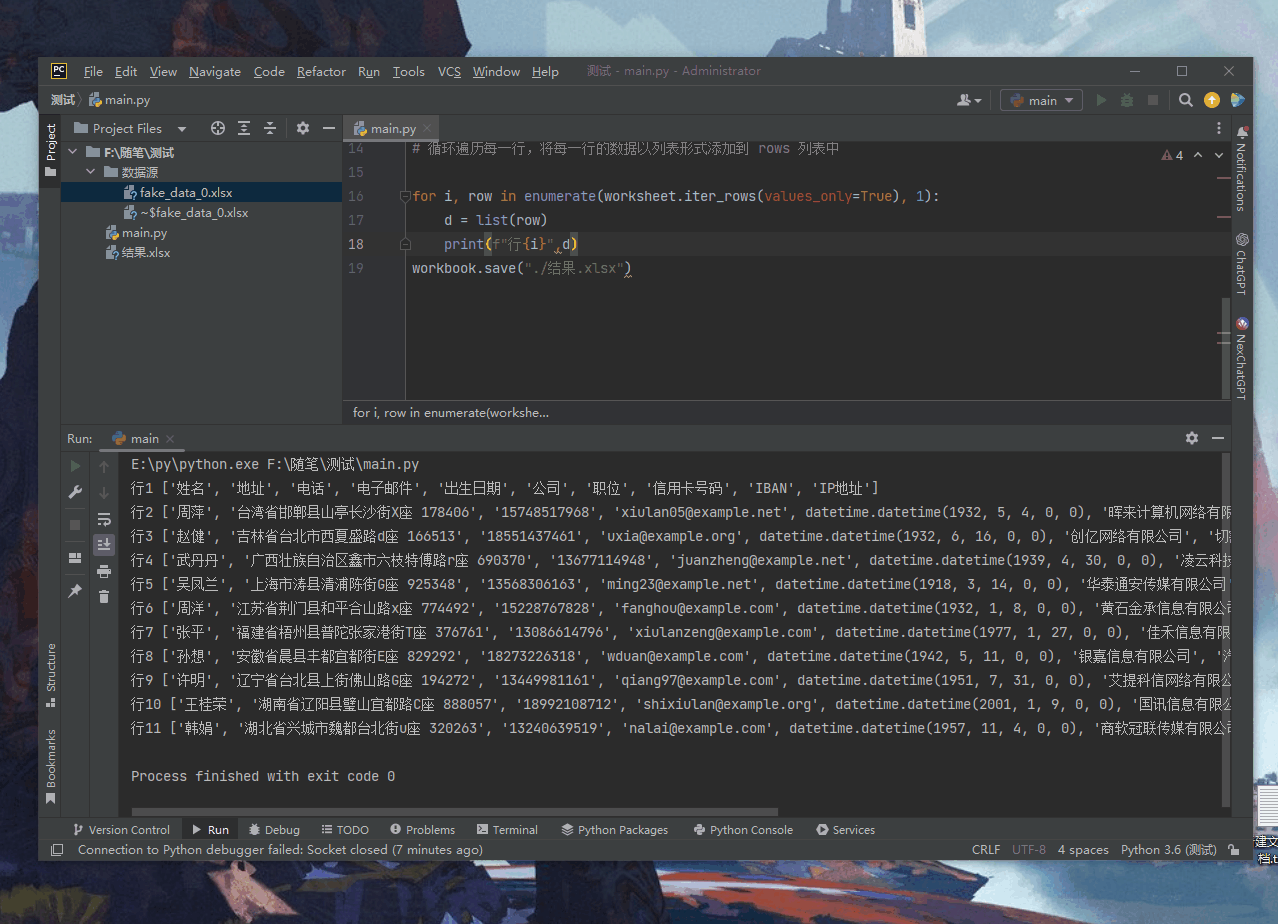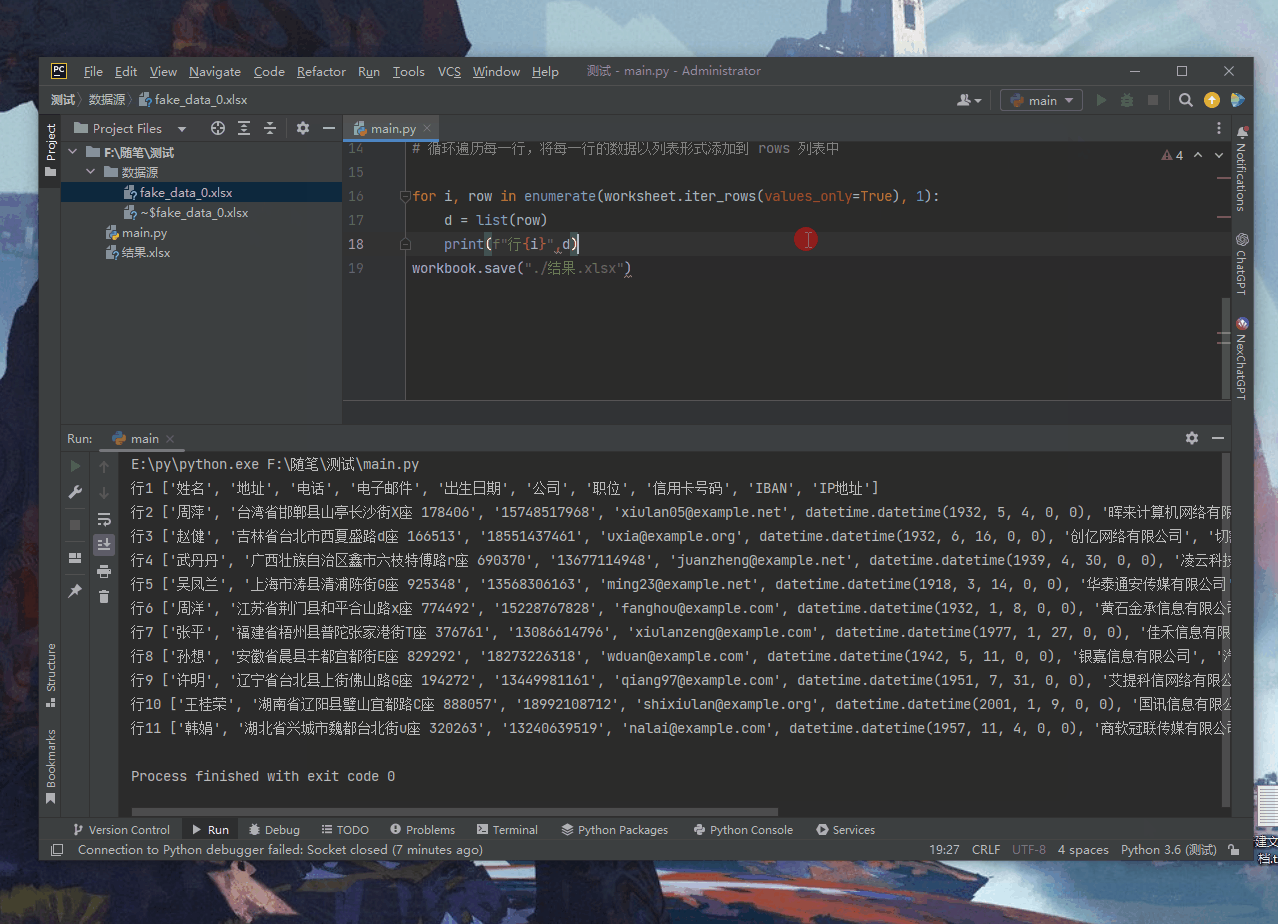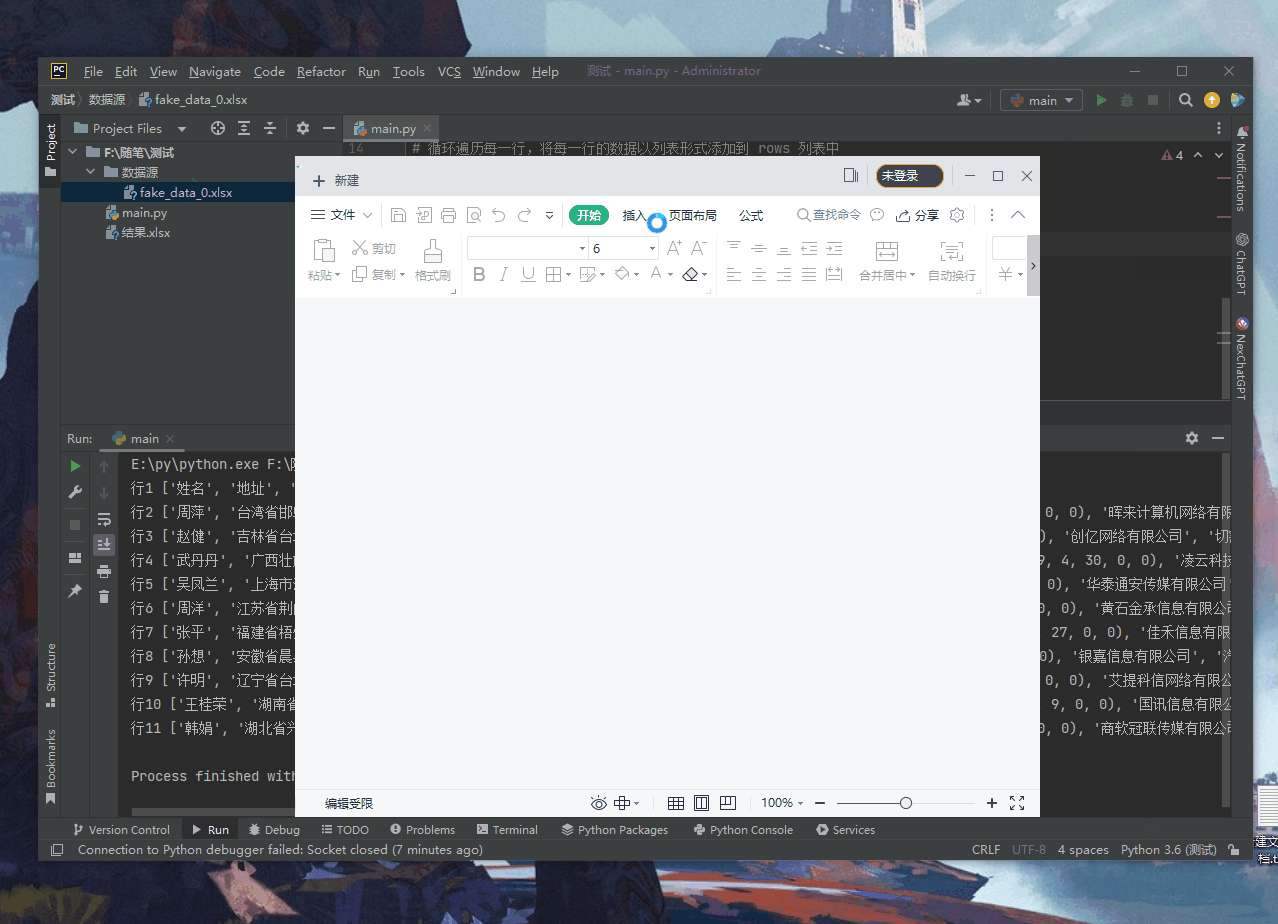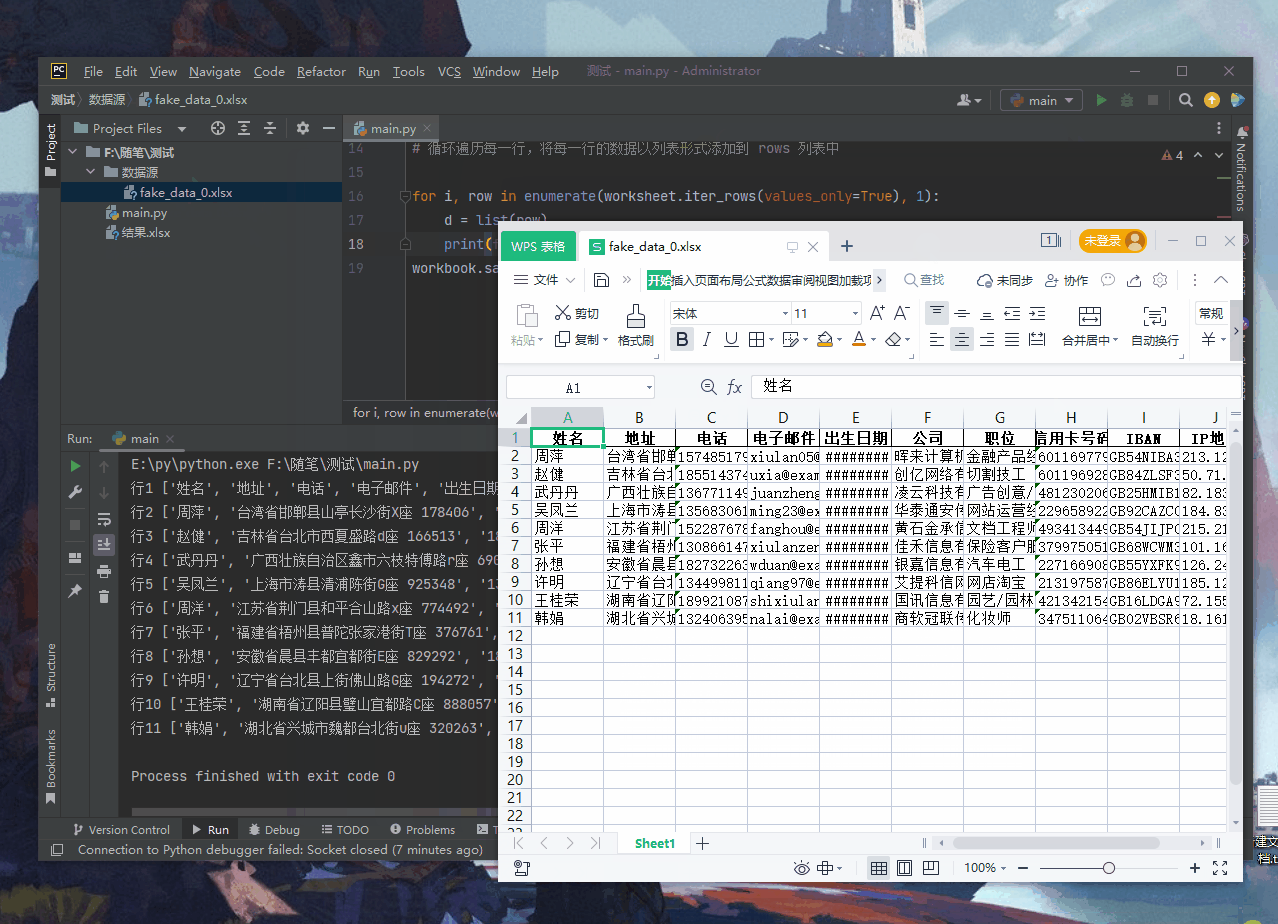
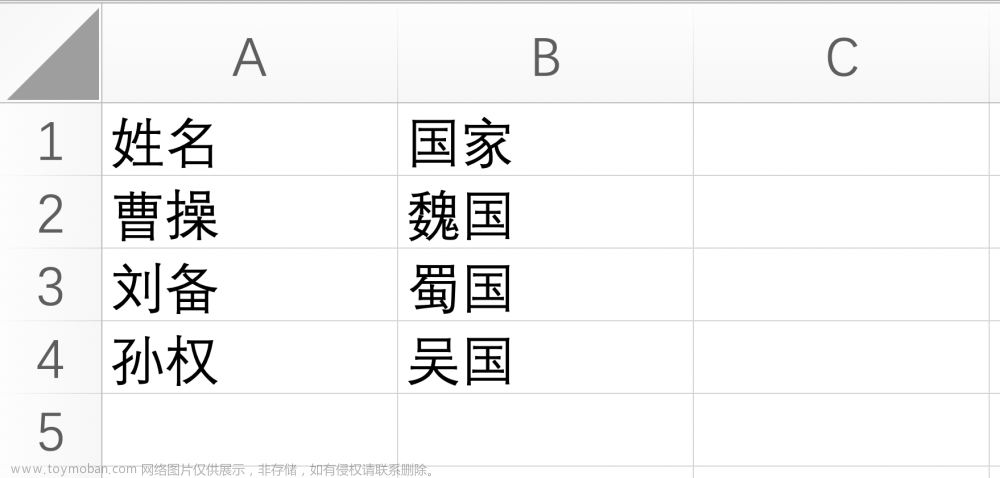
今天所有的测试全部基于以下文件:
pandas的read_excel核心代码
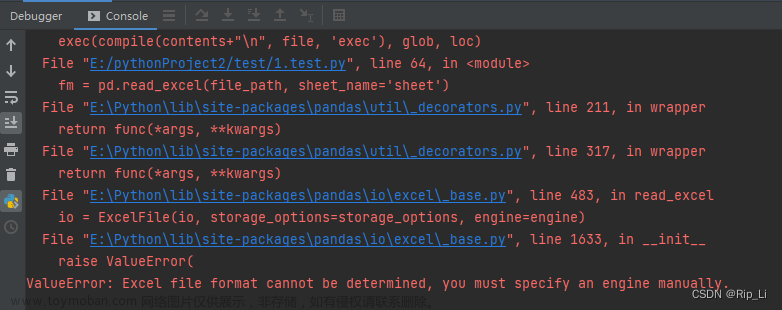
这里我使用pycharm工具对以下代码进行debug跟踪:
import pandas as pd
df = pd.read_excel("张三.xlsx")
核心就是两行代码:
io = ExcelFile(io)
return io.parse(...)
我们研究一下这两行代码所做的事:
ExcelFile构造函数
内容有很多,我们挑一些有价值的内容进行解析。默认传递的参数下,会调用inspect_excel_format函数获取文件的扩展名。
直接通过文件名获取的扩展名有可能不真实,我们可以查看pandas.io.excel._base.inspect_excel_format的源码,研究pandas判断Excel真实扩展名的实现。
个人在阅读源码后,整理出如下可以直接使用的方法:
from zipfile import ZipFile
def inspect_excel_format(filename):
XLS_SIGNATURES = (
b"\x09\x00\x04\x00\x07\x00\x10\x00", # BIFF2
b"\x09\x02\x06\x00\x00\x00\x10\x00", # BIFF3
b"\x09\x04\x06\x00\x00\x00\x10\x00", # BIFF4
b"\xD0\xCF\x11\xE0\xA1\xB1\x1A\xE1", # Compound File Binary
)
ZIP_SIGNATURE = b"PK\x03\x04"
PEEK_SIZE = max(map(len, XLS_SIGNATURES + (ZIP_SIGNATURE,)))
with open(filename, "rb") as stream:
peek = stream.read(PEEK_SIZE)
if peek is None:
raise ValueError("stream is empty")
if any(peek.startswith(sig) for sig in XLS_SIGNATURES):
return "xls"
elif not peek.startswith(ZIP_SIGNATURE):
return None
with ZipFile(stream) as zf:
component_names = [
name.replace("\\", "/").lower() for name in zf.namelist()
]
if "xl/workbook.xml" in component_names:
return "xlsx"
if "xl/workbook.bin" in component_names:
return "xlsb"
if "content.xml" in component_names:
return "ods"
return "zip"
获取到扩展名之后,get_default_engine将获取默认的处理引擎,定义如下:
_default_readers = {
"xlsx": "openpyxl",
"xlsm": "openpyxl",
"xlsb": "pyxlsb",
"xls": "xlrd",
"ods": "odf",
}
self._engines[engine]会找到对应的处理类来处理当前文件。
而ExcelFile有个类定义:
_engines: Mapping[str, Any] = {
"xlrd": XlrdReader,
"openpyxl": OpenpyxlReader,
"odf": ODFReader,
"pyxlsb": PyxlsbReader,
}
于是就可以使用OpenpyxlReader来读取对应的Excel文件:
self._reader = OpenpyxlReader(self._io)
OpenpyxlReader的构造函数
首先判断是否安装openpyxl,然后调用父类BaseExcelReader的构造方法,其中核心代码为:
self.book = self.load_workbook(self.handles.handle)
而OpenpyxlReader的load_workbook实现为:
from openpyxl import load_workbook
return load_workbook(
filepath_or_buffer, read_only=True, data_only=True, keep_links=False
)
可以确定pandas再调用openpyxl时,固定了这些参数。
ExcelFile.parse
跟踪可以看到内部调用了self._reader.parse,这里的核心代码为:
ret_dict = False
sheets = [sheet_name]
output = {}
for asheetname in sheets:
if isinstance(asheetname, str):
sheet = self.get_sheet_by_name(asheetname)
else:
sheet = self.get_sheet_by_index(asheetname)
data = self.get_sheet_data(sheet, convert_float, file_rows_needed)
parser = TextParser(data,header=header)
output[asheetname] = parser.read(nrows=nrows)
if ret_dict:
return output
else:
return output[asheetname]
self.get_sheet_data使用openpyxl引擎读取出指定表格的数据,我们后面再细究。
TextParser用于解析结果,构造函数调用TextFileReader的_make_engine处理结果数据,内部使用python引擎对应的PythonParser进行解析处理,PythonParser的构造方法中,核心代码为:
columns,self.num_original_columns,self.unnamed_cols = self._infer_columns()
该代码根据header参数读取data的前N行作为列,每次调用self._next_line()读取,会改变self.pos的值即当前位置,并当前读取到的行存入self.buf。但是最终该函数会清空self.buf的值。
(index_names, self.orig_names, self.columns) = self._get_index_name(
self.columns
)
这行代码的实现会两次调用self._next_line()读取数据,这两行的数据会存入self.buf中。
parser.read的核心代码为:
index, columns, col_dict = self._engine.read(nrows)
return DataFrame(col_dict, columns=columns, index=index)
self._engine.read调用_get_lines函数将剩余的数据都读入self.buf中并返回,最终得到处理表头以外的所有行数据content。
然后调用self._rows_to_cols(content)将所有的行数据转换为列数据:
alldata = self._rows_to_cols(content)
这行代码内部的核心实现为:
import pandas._libs.lib as lib
zipped_content = list(lib.to_object_array(content, min_width=col_len).T)
不过lib.to_object_array的底层采用其他语言实现,只能直接查看。
然后_exclude_implicit_index将列数据转换为字典,核心代码为:
{
name: alldata[i + offset] for i, name in enumerate(names) if i < len_alldata
}
最终经过一些转换后得到最终结果。
ExcelFile.get_sheet_data
前面在OpenpyxlReader的构造函数中,通过openpyxl的load_workbook函数加载了Excel文件得到self.book。
self.get_sheet_by_name(asheetname)的实现是:
return self.book[asheetname]
self.get_sheet_by_index(asheetname)的实现是:
return self.book.worksheets[index]
可以翻译为:
sheet = self.book.worksheets[0]
data = self.get_sheet_data(sheet, convert_float, file_rows_needed)
get_sheet_data的源码:

内部核心获取数据的代码为sheet.rows,该属性是调用了openpyxl.worksheet.worksheet.Worksheet的iter_rows方法获取数据。
pandas会使用_convert_cell方法对openpyxl获取的单元格提取数值并转换,convert_float参数默认为True,作用是当一个数值可以转为整数时就是整数,并不是所有数值都转为浮点数。
然后while循环实现剔除空行。
总结
pandas读取Excel的核心代码,我们可以总结为如下形式:
from openpyxl import load_workbook
import pandas as pd
import numpy as np
import pandas._libs.lib as lib
from openpyxl.cell.cell import (
TYPE_ERROR,
TYPE_NUMERIC,
)
def convert_cell(cell, convert_float=True):
if cell.value is None:
return "" # compat with xlrd
elif cell.data_type == TYPE_ERROR:
return np.nan
elif cell.data_type == TYPE_NUMERIC:
if convert_float:
val = int(cell.value)
if val == cell.value:
return val
else:
return float(cell.value)
return cell.value
workbook = load_workbook(filename="张三.xlsx", read_only=True, data_only=True, keep_links=False)
sheet = workbook.worksheets[0]
data = [[convert_cell(cell) for cell in row] for row in sheet.rows]
names = data[0]
alldata = lib.to_object_array(data[1:], min_width=len(names)).T
zipped_content = {name: alldata[i] for i, name in enumerate(names)}
df = pd.DataFrame(zipped_content)
当然pandas多余的处理代码比这些更复杂。
我们也可以进一步简化为:
from openpyxl import load_workbook
import pandas as pd
workbook = load_workbook(filename="张三.xlsx", read_only=True, data_only=True, keep_links=False)
sheet = workbook.worksheets[0]
data = [row for row in sheet.iter_rows(values_only=True)]
df = pd.DataFrame(data[1:], columns=data[0])
仿openpyxl源码读取Excel
openpyxl源码读取部分的源码相比pandas处理部分更加复杂,下面我主要对核心代码进行翻译。
load_workbook的代码为:
def load_workbook(filename, read_only=False, keep_vba=KEEP_VBA,
data_only=False, keep_links=True):
reader = ExcelReader(filename, read_only, keep_vba, data_only, keep_links)
reader.read()
return reader.wb
ExcelReader核心:
from zipfile import ZipFile, ZIP_DEFLATED, BadZipfile
filename = r"D:\PycharmProjects\demo1\test\张三.xlsx"
archive = ZipFile(filename, 'r')
valid_files = archive.namelist()
print(valid_files)
['[Content_Types].xml', '_rels/', '_rels/.rels', 'docProps/', 'docProps/app.xml', 'docProps/core.xml', 'docProps/custom.xml', 'xl/', 'xl/_rels/', 'xl/_rels/workbook.xml.rels', 'xl/sharedStrings.xml', 'xl/styles.xml', 'xl/theme/', 'xl/theme/theme1.xml', 'xl/workbook.xml', 'xl/worksheets/', 'xl/worksheets/sheet1.xml', 'xl/worksheets/sheet2.xml', 'xl/worksheets/sheet3.xml']
read的代码为:
def read(self):
self.read_manifest()
self.read_strings()
self.read_workbook()
self.read_properties()
self.read_theme()
apply_stylesheet(self.archive, self.wb)
self.read_worksheets()
self.parser.assign_names()
if not self.read_only:
self.archive.close()
这里将一步步从Excel压缩包中读取需要的数据。
在处理之前,我们定义一些需要用到的常量:
ARC_CORE = 'docProps/core.xml'
PACKAGE_RELS = '_rels'
ARC_THEME = f'xl/theme/theme1.xml'
ARC_STYLE = f'xl/styles.xml'
ARC_CONTENT_TYPES = '[Content_Types].xml'
SHEET_MAIN_NS = 'http://schemas.openxmlformats.org/spreadsheetml/2006/main'
INLINE_STRING = "{%s}is" % SHEET_MAIN_NS
ROW_TAG = '{%s}row' % SHEET_MAIN_NS
VALUE_TAG = '{%s}v' % SHEET_MAIN_NS
SECS_PER_DAY = 24*60*60
read_manifest
该函数用于读取各类xml在压缩包中的路径,openpyxl使用特殊的自定义类来解析xml,我们则使用基本语法读取需要的数据:
from lxml import etree
import re
def localname(name):
NS_REGEX = "({(?P<namespace>.*)})?(?P<localname>.*)"
return re.match(NS_REGEX, name).group('localname')
def read_manifest(archive):
src = archive.read(ARC_CONTENT_TYPES)
manifest = {}
for el in etree.fromstring(src):
manifest.setdefault(localname(el.tag), []).append(el.attrib)
return manifest
manifest = read_manifest(archive)
manifest
{'Default': [{'Extension': 'rels', 'ContentType': 'application/vnd.openxmlformats-package.relationships+xml'},
{'Extension': 'xml', 'ContentType': 'application/xml'}],
'Override': [{'PartName': '/docProps/app.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.extended-properties+xml'},
{'PartName': '/docProps/core.xml', 'ContentType': 'application/vnd.openxmlformats-package.core-properties+xml'},
{'PartName': '/docProps/custom.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.custom-properties+xml'},
{'PartName': '/xl/sharedStrings.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.spreadsheetml.sharedStrings+xml'},
{'PartName': '/xl/styles.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.spreadsheetml.styles+xml'},
{'PartName': '/xl/theme/theme1.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.theme+xml'},
{'PartName': '/xl/workbook.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet.main+xml'},
{'PartName': '/xl/worksheets/sheet1.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.spreadsheetml.worksheet+xml'},
{'PartName': '/xl/worksheets/sheet2.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.spreadsheetml.worksheet+xml'},
{'PartName': '/xl/worksheets/sheet3.xml', 'ContentType': 'application/vnd.openxmlformats-officedocument.spreadsheetml.worksheet+xml'}]}
read_strings
该方法用于读取Excel中的所有常量字符串:
from defusedxml.ElementTree import iterparse
def get_text_content(node):
snippets = []
plain = node.find("./x:t", namespaces={"x": SHEET_MAIN_NS})
if plain is not None:
snippets.append(plain.text)
for t in node.findall("./x:r/x:t", namespaces={"x": SHEET_MAIN_NS}):
snippets.append(t.text)
return "".join(snippets)
def read_strings(manifest, archive):
ct = None
SHARED_STRINGS = "application/vnd.openxmlformats-officedocument.spreadsheetml.sharedStrings+xml"
for t in manifest["Override"]:
if t["ContentType"] == SHARED_STRINGS:
ct = t
break
shared_strings = []
STRING_TAG = '{%s}si' % SHEET_MAIN_NS
if ct is not None:
strings_path = ct["PartName"][1:]
with archive.open(strings_path) as xml_source:
for _, node in iterparse(xml_source):
if node.tag != STRING_TAG:
continue
text = get_text_content(node).replace('x005F_', '')
node.clear()
shared_strings.append(text)
return shared_strings
shared_strings = read_strings(manifest, archive)
print(shared_strings)
openpyxl的源码在这个部分使用defusedxml解析xml,如果我们使用etree解析全部加载到内存的xml,则可以使用如下代码:
def read_strings(manifest, archive):
ct = None
SHARED_STRINGS = "application/vnd.openxmlformats-officedocument.spreadsheetml.sharedStrings+xml"
for t in manifest["Override"]:
if t["ContentType"] == SHARED_STRINGS:
ct = t
break
shared_strings = []
STRING_TAG = '{%s}si' % SHEET_MAIN_NS
if ct is not None:
strings_path = ct["PartName"][1:]
root = etree.fromstring(archive.read(strings_path))
for node in root.xpath("//x:si", namespaces={"x": SHEET_MAIN_NS}):
snippets = node.xpath(".//x:t/text()", namespaces={"x": SHEET_MAIN_NS})
shared_strings.append("".join(snippets).replace('x005F_', ''))
return shared_strings
shared_strings = read_strings(manifest, archive)
print(shared_strings)
使用xpath解析xml可以简化代码。
最终得到的常量字符串有:
['商品', '单价', '数量', '订单号', '订单时间', '总金额', '名称管理', '苹果', 'A', '哈密瓜', 'B', '芒果', 'C']
read_workbook
这部分的核心代码有:
wb_part = _find_workbook_part(self.package)
self.parser = WorkbookParser(self.archive, wb_part.PartName[1:], keep_links=self.keep_links)
self.parser.parse()
我们先翻译_find_workbook_part(self.package):
def find_workbook_part_name(manifest):
part = None
WORKBOOK_MACRO = "application/vnd.ms-excel.{}.macroEnabled.main+xml"
WORKBOOK = "application/vnd.openxmlformats-officedocument.spreadsheetml.{}.main+xml"
XLTM = WORKBOOK_MACRO.format('template')
XLSM = WORKBOOK_MACRO.format('sheet')
XLTX = WORKBOOK.format('template')
XLSX = WORKBOOK.format('sheet')
for ct in (XLTM, XLTX, XLSM, XLSX):
for t in manifest["Override"]:
if t["ContentType"] == ct:
return t["PartName"][1:]
workbook_part_name = find_workbook_part_name(manifest)
workbook_part_name
'xl/workbook.xml'
WorkbookParser.parser解析的数据有点多,下面我尽量只提取需要的数据:
src = archive.read(workbook_part_name)
node = etree.fromstring(src)
workbookPr = node.xpath("./x:workbookPr", namespaces={"x": SHEET_MAIN_NS})[0].attrib
print(workbookPr)
{'codeName': 'ThisWorkbook'}
import datetime
def get_epoch(workbookPr):
MAC_EPOCH = datetime.datetime(1904, 1, 1)
WINDOWS_EPOCH = datetime.datetime(1899, 12, 30)
epoch = WINDOWS_EPOCH
if "date1904" in workbookPr and workbookPr["date1904"]:
epoch = MAC_EPOCH
return epoch
epoch = get_epoch(workbookPr)
epoch
datetime.datetime(1899, 12, 30, 0, 0)
获取活跃表格角标:
bookViews = [el.attrib for el in node.xpath(
"x:bookViews/x:workbookView", namespaces={"x": SHEET_MAIN_NS})]
bookViews
[{'windowWidth': '28800', 'windowHeight': '12690'}]
def get_active(bookViews):
for view in bookViews:
if "activeTab" in view:
return int(view["activeTab"])
return 0
active = get_active(bookViews)
active
0
获取所有工作表的名称和ID:
sheets = [{localname(k): v for k, v in el.attrib.items()} for el in node.xpath(
"x:sheets/x:sheet", namespaces={"x": SHEET_MAIN_NS})]
sheets
[{'name': 'Sheet1', 'sheetId': '1', 'id': 'rId1'},
{'name': 'Sheet2', 'sheetId': '2', 'id': 'rId2'},
{'name': 'Sheet3', 'sheetId': '3', 'id': 'rId3'}]
读取命名空间的定义:
def getDefinedNames(node):
valid_names = {}
for el in node.xpath(
"x:definedNames/x:definedName", namespaces={"x": SHEET_MAIN_NS}):
name, value = el.get("name"), el.text
if name in ("_xlnm.Print_Titles", "_xlnm.Print_Area") and "localSheetId" not in el:
continue
elif name == "_xlnm._FilterDatabase":
continue
valid_names[name] = value
return valid_names
definedNames = getDefinedNames(node)
definedNames
{'aaa': 'Sheet1!$A$3', 'bbb': 'Sheet1!$A$2', 'ccc': 'Sheet1!$A$4'}
read_properties
用于读取文档的一些属性信息:
from openpyxl.utils.datetime import from_ISO8601
properties = {}
if ARC_CORE in valid_files:
for el in etree.fromstring(archive.read(ARC_CORE)):
key = localname(el.tag)
value = el.text
if key in ("lastPrinted", "created", "modified"):
value = from_ISO8601(value)
properties[key] = value
properties
{'creator': 'openpyxl',
'lastModifiedBy': '那年&那天',
'created': datetime.datetime(2023, 3, 8, 9, 7),
'modified': datetime.datetime(2023, 3, 26, 15, 40, 30)}
符合ISO8601格式的时间字符串有很多种形式,上述代码直接使用openpyxl现成的实现,将2023-03-08T09:07:00Z等形式的时间字符串解析为日期时间对象。
核心代码是使用如下正则进行匹配:
ISO_REGEX = re.compile(r'''
(?P<date>(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2}))?T?
(?P<time>(?P<hour>\d{2}):(?P<minute>\d{2})(:(?P<second>\d{2})(?P<microsecond>\.\d{1,3})?)?)?Z?''', re.VERBOSE)
apply_stylesheet
这个函数除了读取字体、对齐、边框、填充等各种样式数据以外,还会读取出哪些列是日期格式的列,用于后续将数值类型的列解析为时间。
对于纯数据读取而言,样式数据并不是我们需要的数据,这里只演示字体列表的读取:
fonts = []
node = etree.fromstring(archive.read(ARC_STYLE))
for el in node.xpath(
"x:fonts/x:font", namespaces={"x": SHEET_MAIN_NS}):
fonts.append({localname(e.tag): e.attrib for e in el})
读取出哪些列是日期格式的列,体现在openpyxl.styles.stylesheet.Stylesheet类构造函数的self._normalise_numbers()函数上。
根据custom_formats函数的实现,解析出所有的自定义格式:
node = etree.fromstring(archive.read(ARC_STYLE))
numFmts = {
int(el.get("numFmtId")): el.get("formatCode") for el in node.xpath(
"x:numFmts/x:numFmt", namespaces={"x": SHEET_MAIN_NS})
}
numFmts
{41: '_ * #,##0_ ;_ * \\-#,##0_ ;_ * "-"_ ;_ @_ ',
42: '_ "¥"* #,##0_ ;_ "¥"* \\-#,##0_ ;_ "¥"* "-"_ ;_ @_ ',
43: '_ * #,##0.00_ ;_ * \\-#,##0.00_ ;_ * "-"??_ ;_ @_ ',
44: '_ "¥"* #,##0.00_ ;_ "¥"* \\-#,##0.00_ ;_ "¥"* "-"??_ ;_ @_ ',
176: 'yyyy\\-m\\-d\\ h:mm:ss',
177: '[h]:mm:ss;@'}
获取日期列的实现:
from openpyxl.styles.numbers import BUILTIN_FORMATS, STRIP_RE
date_formats = set()
cell_styles = node.xpath("x:cellXfs/x:xf", namespaces={"x": SHEET_MAIN_NS})
for idx, el in enumerate(cell_styles):
style = el.attrib
numFmtId = int(style["numFmtId"])
if numFmtId in numFmts:
fmt = numFmts[numFmtId]
else:
fmt = BUILTIN_FORMATS[numFmtId]
fmt = fmt.split(";")[0]
if re.search(r"[^\\][dmhysDMHYS]", STRIP_RE.sub("", fmt)) is not None:
date_formats.add(idx)
date_formats
read_worksheets
这里我们已经设置了只读形式,而且我们不考虑透视图类型的工作表,那么核心代码为:
def read_worksheets(self):
for sheet, rel in self.parser.find_sheets():
ws = ReadOnlyWorksheet(self.wb, sheet.name, rel.target, self.shared_strings)
ws.sheet_state = sheet.state
self.wb._sheets.append(ws)
所需要的数据都封装到ReadOnlyWorksheet对象中。
其实所需要的数据只有表名和对应的路径,解析代码如下:
import posixpath
def get_rels_path(path):
folder, obj = posixpath.split(path)
filename = posixpath.join(folder, '_rels', '{0}.rels'.format(obj))
return filename
def get_dependents(archive, filename):
filename = get_rels_path(filename)
folder = posixpath.dirname(filename)
parent = posixpath.split(folder)[0]
rels = {}
for el in etree.fromstring(archive.read(filename)):
r = el.attrib
if r.get("TargetMode") == "External":
continue
elif r["Target"].startswith("/"):
r["Target"] = r["Target"][1:]
else:
pth = posixpath.join(parent, r["Target"])
r["Target"] = posixpath.normpath(pth)
rels[r.get("Id")] = r
return rels
rels = get_dependents(archive, workbook_part_name)
name2file = {}
for sheet in sheets:
name2file[sheet["name"]] = rels[sheet["id"]]["Target"]
name2file
{'Sheet1': 'xl/worksheets/sheet1.xml',
'Sheet2': 'xl/worksheets/sheet2.xml',
'Sheet3': 'xl/worksheets/sheet3.xml'}
而ReadOnlyWorksheet的构造函数中,self._get_size()函数会解析整个表的大小,面向过程的实现为:
from openpyxl.utils.cell import column_index_from_string
def parse_dimensions(worksheet_path):
source = archive.open(worksheet_path)
for _event, element in iterparse(source):
tag_name = localname(element.tag)
if tag_name == "dimension":
ref = element.get("ref")
min_col, min_row, sep, max_col, max_row = re.match(
"\$?([A-Za-z]{1,3})\$?(\d+)(:\$?([A-Za-z]{1,3})\$?(\d+))?", ref).groups()
min_col, max_col = map(
column_index_from_string, (min_col, max_col))
min_row, max_row = map(int, (min_row, max_row))
return min_col, min_row, max_col, max_row
elif tag_name == "sheetData":
break
element.clear()
source.close()
worksheet_path = name2file['Sheet1']
dimensions = parse_dimensions(worksheet_path)
dimensions
(1, 1, 7, 4)
该值分别代表行列的最小和最大数量:
min_col, min_row, max_col, max_row = dimensions
sheet.iter_rows是如何解析数据的
最后我们终于到了解析数据的环节,当调用ReadOnlyWorksheet对象的iter_rows方法时,到底发生了什么呢?
iter_rows实际上调用的是ReadOnlyWorksheet对象的_cells_by_row函数,核心代码为:
def _cells_by_row(self, min_col, min_row, max_col, max_row, values_only=False):
src = self._get_source()
parser = WorkSheetParser(src, self._shared_strings,
data_only=self.parent.data_only, epoch=self.parent.epoch,
date_formats=self.parent._date_formats)
for idx, row in parser.parse():
row = self._get_row(row, min_col, max_col, values_only)
yield row
src.close()
最终翻译过来的实现代码为:
def from_excel_time(value, epoch):
SECS_PER_DAY = 24*60*60
day, fraction = divmod(value, 1)
diff = datetime.timedelta(
milliseconds=round(fraction * SECS_PER_DAY * 1000))
if 0 <= value < 1 and diff.days == 0:
mins, seconds = divmod(diff.seconds, 60)
hours, mins = divmod(mins, 60)
dt = datetime.time(hours, mins, seconds, diff.microseconds)
else:
if 0 < value < 60 and epoch == WINDOWS_EPOCH:
day += 1
dt = epoch + datetime.timedelta(days=day) + diff
return dt
def load_data(archive, file):
src = archive.open(file)
data = []
for _, element in iterparse(src):
tag_name = element.tag
if tag_name != ROW_TAG:
continue
cells = []
for el in element:
data_type = el.get('t', 'n')
coordinate = el.get('r')
style_id = int(el.get('s', 0))
if data_type == "inlineStr":
child = el.find(INLINE_STRING)
value = None
if child is not None:
data_type = 's'
value = get_text_content(child)
else:
value = el.findtext(VALUE_TAG, None) or None
if data_type == 'n':
if re.search("[.e]", value, flags=re.I):
value = float(value)
else:
value = int(value)
if style_id in date_formats:
data_type = 'd'
try:
value = from_excel_time(value, epoch)
except (OverflowError, ValueError):
data_type = "e"
value = "#VALUE!"
elif data_type == 's':
value = shared_strings[int(value)]
elif data_type == 'b':
value = bool(int(value))
elif data_type == "str":
data_type = "s"
elif data_type == 'd':
value = from_ISO8601(value)
cells.append(value)
element.clear()
data.append(cells)
src.close()
return data
data = load_data(archive, name2file['Sheet1'])
data
结果:
[['商品', '单价', '数量', '订单号', '订单时间', '总金额', '名称管理'],
['苹果', 5.5, 1, 'A', datetime.datetime(2020, 1, 5, 12, 20), 5.5, '哈密瓜'],
['哈密瓜', 8, 3, 'B', datetime.time(12, 35), 24, '苹果'],
['芒果', 10, 2, 'C', datetime.datetime(2020, 1, 7, 9, 10), 20, '芒果']]
可以看到已经顺利的读取所需要的各种类型的数据。
注意:
get_text_content在前面的read_strings一节已经实现。文章来源:https://www.toymoban.com/news/detail-418433.html
最终我们终于顺利的实践了解析Excel的全过程,可以基于以上过程封装几个简易的类解决该问题。文章来源地址https://www.toymoban.com/news/detail-418433.html
到了这里,关于pandas读取Excel核心源码剖析,面向过程仿openpyxl源码实现Excel数据加载的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!