本小白不久前才刚开始学习c艹,众所周知,c艹是本贾尼祖师爷在使用c的时候遇到了诸多不便,便在对c进行扩展和改进后的得到的新语言,所以说这一篇博客就带来c艹对c的两个个优化点
命名空间
存在意义
当我们在使用C进行日常编程时不会有太多关于变量的烦恼。
但是当我们进行一些中大项目的编写时,就会遇到变量名重复的问题
变量重复有多种情况
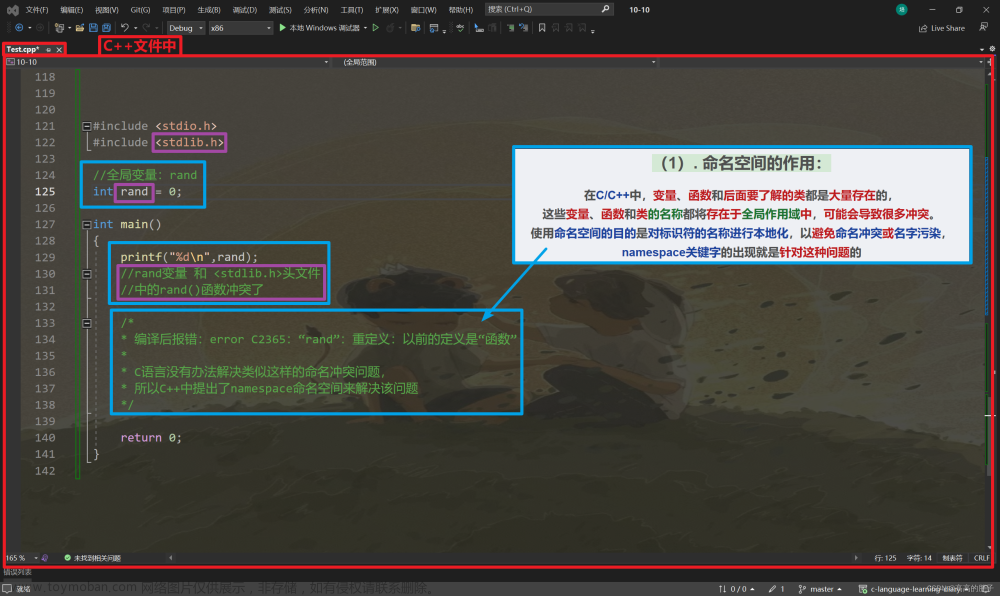
1:全局变量与头文件变量重命名
#include<time.h>
#include<stdio.h>
int time = 0;
int main()
{
printf("%d", time);
}
当我们包含头文件,对头文件进行展开时针对.h,没有h后缀的cpp标准库都对它们的变量放入了std命名空间中
其全部变量都会在展开的作用域中出现,导致我们命名变量可能会和头文件中的变量重命名。
2:定义了一样名字的变量。
#include<time.h>
#include<iostream>
int cout = 0;
int main()
{
int a = 0;
int a = 0;
printf("%d", a);
}
当我们写项目时,往往是多个人合作,所以当写完的各个部分代码合并时,就有可能导致这种情况。
使用方法
所以我们的命名空间就在C艹中闪亮登场了。
#include<iostream>
using std::cout;
using std::endl;
int a = 0;
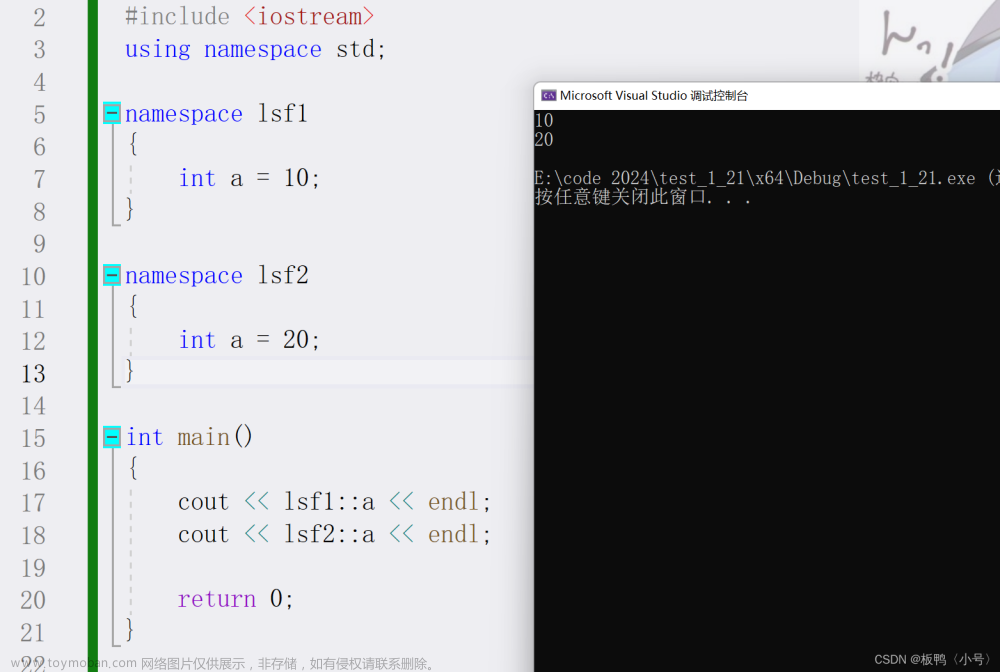
namespace test
{
int a = 2;
}
int main()
{
cout << a << endl;
cout << test::a<< endl;
//::是对特定的作用域进行访问的方式
}
其中的test就是我们自定义的命名空间
命名空间就好像一堵墙,将外面的作用域围了起来。
在不访问时,编译器不会去命名空间进行搜索。
这样使全局的a和围在test命名空间中的a也不会产生冲突
因为当打印全局a时,不会对test空间进行搜索
而使用::来特定访问test空间时,编译器只会对test空间进行单独访问。
同样,在命名空间也可以定义函数。
#include<stdio.h>
namespace test
{
int add(int x, int y)
{
return x + y;
}
}
int main()
{
printf("%d", test::add(1, 2));
}
命名空间嵌套
namespace test1
{
namespace test2
{
int n2;
}
}
命名空间是可以支持嵌套的,当我们想要取出test2的数据时
int main()
{
printf("%d", test1::test2::n2);
}
就像结构体一样的逐个->一样。
嵌套通常需要对变量进行更近一步限制时使用。
相同命名域合并
还记得我们前面说的吗
针对.h,没有h后缀的cpp标准库都对它们的变量放入了std命名空间中
在c++标准库中,祖师爷把所有的头文件变量和函数全部放入了一个std的命名空间中
防止像C中引入头文件展开后就有大量变量导致非常容易与自己定义的变量重命名的情况发生。
就比如
在test1.h头文件中
namespace test
{
int add(int x, int y)
{
return x + y;
}
}
在test2.h头文件中
namespace test
{
int Sub(int x,int y)
{
return x - y;
}
}
在源文件中
#include<stdio.h>
#include"test1.h"
#include"test2.h"
int main()
{
printf("%d", test::add(1, 2));
printf("%d", test::Sub(1, 2));
}
这样我们能清楚的看到,当我们使用相同名字的命名空间中,会进行合并。
c++标准库也同样是用这种方法进行合并的。
并且全都合并在了std这个命名空间中。
#include<iostream>
using namespace std;
int main()
{
cout << "学CPP真是太开心啦!!" << endl;
}
展开命名空间
看到我们上面写的代码
using namespace std;
这串代码就好像让编译器跨国std的墙,进行变量搜索。
如果是在全局变量中展开,那就会将std的变量作用域调整至全局变量。
这个时候命名空间的优势将不存在,所以我们一般只在日常使用代码量较少的情况下展开。
推荐还是使用限制作用域访问
cout << test::a<< endl;
或者展开一小部分
using std::cout;
using std::endl;
这样就只展开了std中的cout与endl变量。
缺省参数
这也是C++较于C的改进部分。
#include<iostream>
int add(int x,int y)
{
return x + y;
}
int main()
{
std::cout << add(1, 2) << std::endl;
}
这是最普通的函数以及传参方式。
而C++特地优化了函数的定义方式。
int add(int x = 0,int y = 0)
{
return x+y;
}
int main()
{
std::cout << add() << std::endl;
}
在定义函数的时候,给参数传一个缺省值
当我们不给函数传参时,函数就会默认使用缺省值来进行运算
全缺省参数
顾名思义,就是给所有参数一个缺省值
int add(int x = 0,int y = 0)
{
return x+y;
}
但是我们要注意
在我们传参的时候
std::cout << add(,2) << std::endl;
这样的形式是不可以的
对于缺省函数传参时只能从左往右传,不能跳着传
std::cout << add(1) << std::endl;
这样就代表给参数x传了1,而y使用缺省值赋值
半缺省参数
全缺省参数就是给每个参数都给缺省值,那半缺省参数就是给一半的缺省值。
意思我们是知道了
但是要怎么缺呢?int add(int x =0,int y);
是从右到左吗?
如果这样的话,当我们只传一个参数时
std::cout << add(1) << std::endl;
这样编译器就不知道这个1是传给x还是y了。
因为按照语法设定,传参传的参数是从左到右的顺序的。
这样当然就会报错了
这样我们就得出了,半缺省是从左往右的int add(int x,int y=0);
这样我们就得出了结论
参数传参不能用跳过,只能从右往左省略传参。
而函数给缺省值,则只能从左向右,因为传参设定是从左向左文章来源:https://www.toymoban.com/news/detail-418535.html
ps:设置缺省,只能在声明函数时设定,不能在定义函数时设置。文章来源地址https://www.toymoban.com/news/detail-418535.html
//test.h
int add(int x,int y=0);
//come_true.cpp
int add(int x,int y)
{
return x + y;
}
到了这里,关于cpp入门-命名空间,缺省参数的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!