00_资料
- 论文地址1
- 论文地址2
- 项目地址
- Demo 地址
- SA-1B数据集
- 参考链接
- 论文翻译
01_浅谈 segment-anything
展望未来
- Meta 在论文中发布的新模型名叫 Segment Anything Model (SAM) 。
- 如标题所述,这篇论文只做了一件事情:(零样本)分割一切。类似 GPT-4 已经做到的「回答一切」。
- 将 NLP 的 prompt 范式引入了 CV 领域,进而为 CV 基础模型提供更广泛的支持与深度研究。
- SAM的出现统一了分割这个任务(CV任务的一个子集)的下流应用,说明了CV的大模型是可能存在的。
- 可以预想,今年这类范式在学术界将迎来一次爆发。其肯定会对CV的研究带来巨大的变革,很多任务会被统一处理,可能再过不久,检测、分割和追踪也会被all in one了。
- 新数据集+新范式+超强零样本泛化能力。
放眼当下
- 虽然作者们声称要“segment everything”,但距离这个目标还有很长的路要走。CV最大的困难之一,就是图像语义可以无限细分,且逻辑关系非常复杂。势必会遇到识别的粒度和确定性之间的冲突。至少到目前为止,没有任何方法可以解决这个问题,也就没法做到真正的万物分割。
- 不过这个工作确实把 engineering 做到了极致,而且上手即用,非常方便。
- SAM其实缩小了大厂和小厂的差距,使得大部分没有资源和数据训练视觉 foundation model 的人,都可以使用SAM的特征做各种下游任务。
- 下游任务所面临的困难或许比预训练还要更多!但是不管怎么说,我看好SAM作为 foundation model 的潜力,它很可能拥有与CLIP比肩的影响力,未来将为大量的视觉任务提供基础能力。
- 最后还是强调:CV还有很长的路要走,不要散布恐慌,自己吓自己。
评价谈论
- 英伟达人工智能科学家 Jim Fan 表示:「对于 Meta 的这项研究,我认为是计算机视觉领域的 GPT-3 时刻之一。它已经了解了物体的一般概念,即使对于未知对象、不熟悉的场景(例如水下图像)和模棱两可的情况下也能进行很好的图像分割。最重要的是,模型和数据都是开源的。恕我直言,Segment-Anything 已经把所有事情(分割)都做的很好了。」
- 网友表示,NLP 领域的 Prompt 范式,已经开始延展到 CV 领域了,可以预想,今年这类范式在学术界将迎来一次爆发。
- 更是有网友表示蚌不住了,SAM 一出,CV 是真的不存在了。投稿 ICCV 的要小心了。
- 也有人表示,该模型在生产环境下的测试并不理想。或许,这个老大难问题的解决仍需时日?
- 总而言之,未来已来,CV的LM时代将彻底开启,至少标注是肯定不存在了
02_SAM功能介绍
- 通用涵盖广泛的用例(学会了关于物体的一般概念)。
- 零样本迁移(可以在新的图像领域上即开即用,无需额外的训练)。
- SAM 能很好的自动分割图像中的所有内容。
- SAM 能根据提示词进行图像分割。
- SAM 能用交互式点和框的方式进行提示。
- SAM 能为不明确的提示生成多个有效掩码。可以为任何图像或视频中的任何物体(包括训练中没有的)生成 mask。
03_SA-1B数据集
- 图像注释数据集 Segment Anything 1-Billion (SA-1B)
- 有史以来最大的分割数据集,超过 11 亿个分割掩码,掩码具有高质量和多样性。
- SAM 在不同群体中的表现类似,在拥有更多图像的同时对所有地区的总体代表性也更好。
- SA-1B 可用于研究目的,开放许可Apache 2.0。可以帮助其他研究人员训练图像分割的基础模型。
04_Meta数据标注:Data Is All You Need!
Meta或许在憋大招,正所谓兵马未动粮草先行,为了攒数据而开发了这么一个副产物,顺便放了出来。
注释员使用 SAM 交互式地注释图像,然后新注释的数据反过来用于更新 SAM,彼此相互作用,重复执行此循环来改善模型和数据集。
- 先用开源数据集训练一个小模型
- 标注员用训好的模型辅助标注,优先标好标的。如果图中一个instance开始花费超过30s就可以跳下一张图了
- 用新增的label在大模型上重新训练,并重复第2步。随着模型能力的增强,之前难标的会逐渐变成好标的
- 第3步迭代6次后,开始攻克剩余所有困难的instance。先用模型把容易的instance都mask掉,剩下的就得拿去标了。
05_方法介绍
Pre-分割任务
- 在此之前,分割作为计算机视觉的核心任务,已经得到广泛应用。
- 为特定任务创建准确的分割模型,通常需要技术专家进行高度专业化的工作
- 需要大量的领域标注数据,种种因素限制了图像分割的进一步发展。
此前解决分割问题大致有两种方法。
- 交互式分割,该方法允许分割任何类别的对象,但需要一个人通过迭代细化掩码来指导该方法。
- 自动分割,允许分割提前定义的特定对象类别(例如,猫或椅子),但需要大量的手动注释对象来训练(例如,数千甚至数万个分割猫的例子)。
Now-SAM
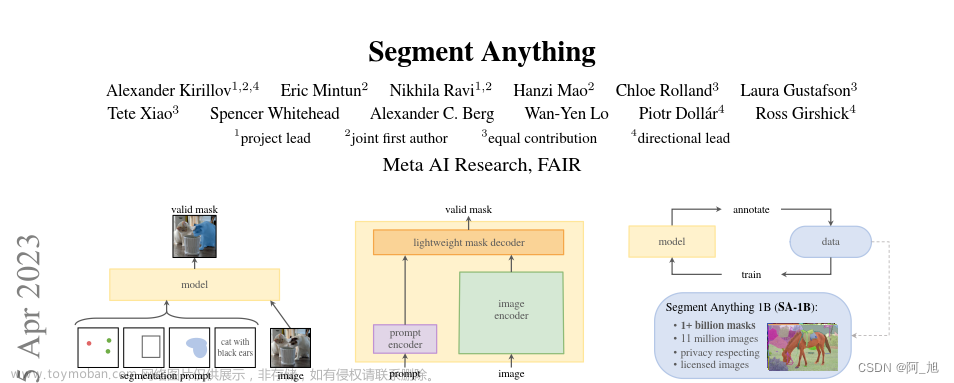
SAM 单一模型,可以轻松地执行交互式分割和自动分割。此任务用于预训练模型并通过提示解决一般的下游分割任务。
- 灵活方便:SAM 允许用户通过单击、交互式点击或边界框提示来分割对象。提示可以是前景、背景点、粗框或掩码、自由格式文本,或者说能指示图像中要分割内容的任何信息。
- 有效掩码的要求:即使提示不明确并且可能指代多个对象,还能为为不明确的提示生成多个有效掩码。当面临关于正在分割的对象歧义时,SAM可以输出多个有效掩码,这是解决现实世界中分割问题所必需的重要能力;
- 可以自动查找并遮罩图像中的所有对象:在预计算图像嵌入后,SAM 可以为任何提示生成实时分割掩码,允许与模型进行实时交互。图像编码器为图像生成一次性嵌入,而轻量级编码器将提示实时转换为嵌入向量。然后将这两个信息源组合在一个预测分割掩码的轻量级解码器中。在计算图像嵌入后,SAM 可以在 50 毫秒内根据网络浏览器中的任何提示生成一个分割。
06_研发思路
开发一个可提示的模型并使用一项任务在广泛的数据集上进行预训练,以实现强大的泛化。通过这个模型,我们的目标是使用提示工程解决一系列新的数据分布上的下游分割问题。这个计划的成功取决于三个组成部分:任务、模型和数据。
SAM 的研发灵感来自于自然语言和计算机视觉中的 “prompt 工程”,只需对新数据集和任务执行零样本学习和少样本学习即可使其能够基于任何提示返回有效的分割掩模。其中,提示可以是前景/背景点、粗略框或掩模、自由文本或者一般情况下指示图像中需要进行分割的任何信息。有效掩模的要求意味着即使提示不明确并且可能涉及多个对象(例如,在衬衫上的一个点既可能表示衬衫也可能表示穿着它的人),输出应该是其中一个对象合理的掩模。这项任务用于预训练模型,并通过提示解决通用下游分割任务。
07_未来展望
将来,SAM 可能被用于任何需要在图像中找到和分割任何对象的领域应用程序。文章来源:https://www.toymoban.com/news/detail-418856.html
- 通过研究和数据集共享,进一步加速对图像分割以及更通用图像与视频理解的研究。
- 可提示的分割模型可以充当更大系统中的一个组件,执行分割任务。
- 基于 prompt 工程等技术的可组合系统设计将支持更广泛的应用。可以成为 AR、VR、内容创建、科学领域和更通用 AI 系统的强大组件。
- 对于 AI 研究社区或其他人来说,SAM 可能更普遍理解世界、例如理解网页视觉和文本内容等更大型 AI 系统中组件;
- 在 AR/VR 领域,SAM 可以根据用户注视选择一个对象,然后将其“提升”到 3D;
- 对于内容创作者来说,SAM 可以改进诸如提取碎片或视频编辑等创意应用程序;
- SAM 也可用来辅助科学领域研究,如地球上甚至空间自然现象, 例如通过定位要研究并跟踪视频中的动物或物体。SAM 还有可能在农业领域帮助农民或者协助生物学家进行研究。
未来在像素级别的图像理解与更高级别的视觉内容语义理解之间,我们将看到更紧密的耦合,进而解锁更强大的 AI 系统。
08_先行者试跑demo的感受
模型推理速度挺快的,在单块V100上,对于1200x800这种正常分辨率的图,生成所有的mask需要2-3秒。这种速度,可以为大部分人提供可用的feature extractor了。文章来源地址https://www.toymoban.com/news/detail-418856.html
- 当前版本下,作者们并没有提供标准的text prompt做法,所以输出的mask都没有标签。我有两个猜测:要么效果还不是很好,要么FAIR想单独出个别的paper。按照FAIR的风格,不做这最后一步,有点不能理解,毕竟这能够轻松刷掉一堆分割任务的SOTA。
- 我尝试用GitHub的issue#6里的“野路子”,抽取了文本的CLIP特征然后用来做prompt。实验效果比较一般:很多物体的score并不高,比如一个水果摊上放着很多水果的时候,明明能够认出一个个的橙子,但是用orange作为query,score大多数情况下只有0.02左右,很不稳定。结合这个实验,我更倾向于上面的前一种猜测:SAM开放环境下的zero-shot recognition能力还不太稳定。
如果我的判断是对的,那么这里就还有不少相对简单的事情可以做。当然,复杂的事情更多:毕竟SAM没有解决逻辑问题,zero-shot效果也未必好,那么在各种下游任务上,大家就有了各显神通、施展才艺的空间。
引用参考链接
- 知乎问题:Meta 发布图像分割论文 Segment Anything,将给 CV 研究带来什么影响?
- 谢凌曦:试跑demo的感受
- 初入AI的高中生:meta是怎么做标注的
- 机器之心(公众号):CV不存在了?Meta发布「分割一切」AI 模型,CV或迎来GPT-3时刻
- CSDN(公众号):CV 迎来 GPT-3 时刻,Meta 开源万物可分割 AI 模型和 1100 万张照片,1B+掩码数据集!
- AI浩:分割anything
到了这里,关于【segment-anything】- Meta 开源万物可分割 AI 模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!