前言
大家好,我是阿光。
本专栏整理了《PyTorch深度学习项目实战100例》,内包含了各种不同的深度学习项目,包含项目原理以及源码,每一个项目实例都附带有完整的代码+数据集。
正在更新中~ ✨
🚨 我的项目环境:
- 平台:Windows10
- 语言环境:python3.7
- 编译器:PyCharm
- PyTorch版本:1.8.1
💥 项目专栏:【PyTorch深度学习项目实战100例】
一、基于LSTM实现乐器声音音频识别
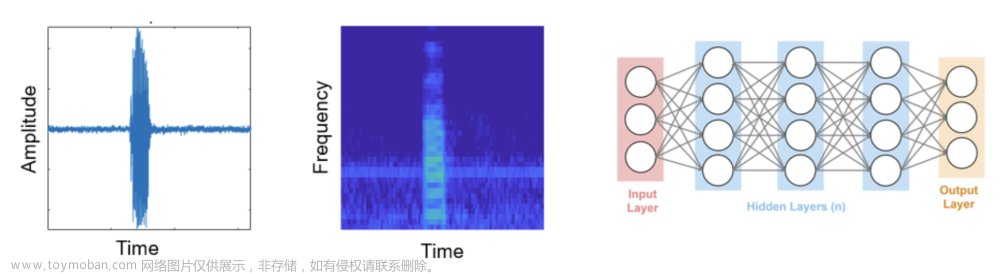
本文我们将介绍如何使用Pytorch训练一个网络模型用来进行语音识别,由于语音是属于时序信息,所以本项目主要使用循环神经网络LSTM来进行建模,我们将建立一个用现代算法来分类一个曲调是大和弦还是小和弦的语音识别模型。

二、数据集介绍
该数据集包含吉他和钢琴两种乐器的音频文件。
 文章来源:https://www.toymoban.com/news/detail-418891.html
文章来源:https://www.toymoban.com/news/detail-418891.html
这些数据是从各种来源搜集来的。音乐是关于模式的。一旦你知道了这些“规则”和模式,你就可以自文章来源地址https://www.toymoban.com/news/detail-418891.html
到了这里,关于基于LSTM实现乐器声音音频识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[语音识别] 基于Python构建简易的音频录制与语音识别应用](https://imgs.yssmx.com/Uploads/2024/02/662057-1.png)