引言
前段时间,清华公布了中英双语对话模型 ChatGLM-6B,具有60亿的参数,初具问答和对话功能。最!最!最重要的是它能够支持私有化部署,大部分实验室的服务器基本上都能跑起来。因为条件特殊,实验室网络不通,那么如何进行离线部署呢?经过一下午的折腾终于搞定了,总结了这么一个部署文档供大家讨论学习。除去下载模型以及依赖包的时间,部署十分钟搞定!!让我们冲~~
前提条件
CUDA Version 11.0,内存32G或者显卡内存8G+8G机器内存及以上。
安装Miniconda
1.1 获取安装包
方法一、把Miniconda安装包、ChatGLM-6B模型、webui项目、项目依赖包都放到网盘里面了,可以直接通过网盘获取(获取方式放在最后)。
方法二、因为Miniconda自带python,所以要在官网下载python版本为3.10的Miniconda版本。下载地址为:https://docs.conda.io/en/latest/miniconda.html#linux-installers,具体截图如下。(如果不想自己麻烦,我也已经把它放到云盘里面了)。
1.2 安装 Miniconda
将Miniconda下载安装包放到你要放的目录,这里我放在:/home/work/chatglm/miniconda 中,然后执行sh Miniconda3-latest-Linux-x86_64.sh 如下图所示,执行完之后按照提示进行回车(enter)就好了,注意:最后选择“yes”,这样每次启动,它都会自动给你切换到conda的base环境中。
2、创建项目运行虚拟机环境
miniconda支持创建多个虚拟环境,用来支撑不同版本(python)版本的代码,这里就为chatglm-6b创建一个单独的python虚拟机环境,名字叫:chatglm,后面会在该环境中安装跑chatglm-6b模型的所有依赖。下面是命令及截图:
conda create -n chatglm --clone base (注:因为是离线安装这里选择clone的方式创建,直接创建会报错)
conda env list
conda activate chatglm

3、安装模型需要的所有依赖
chatglm-6b在centos上用到的所有依赖全都打包在packages里面了(在云盘中,获取方式放在最后),将其也放到/home/work/chatglm/packages下面,然后执行:
pip install --no-index --find-links=/home/work/chatglm/packages -r requirements.txt
4、获取模型文件
方法一、通过网盘获取模型文件。
方法二、通过Hugging Face获取,连接地址:https://huggingface.co/THUDM/chatglm-6b/tree/main,下载所有的文件。建立chatglm_model文件夹,把下载的所有文件都塞到这里面。
不管通过以上哪种方法:将模型文件放到机器目录:/home/work/chatglm/chatglm_model下面。
5、获取项目webui
方法一、通过网盘获取模型文件
方法二、通过github开源项目获取,连接地址:https://github.com/Akegarasu/ChatGLM-webui,下载所有文件。建立webui文件夹,将下载的所有文件都塞到这个文件夹里面。
还是不管按照以上哪种方法获取,将模型文件放到机器目录:/home/work/chatglm/webui里面。
6、启动webui(最后一步)
按照上面的操作,最终的文件夹目录如下:

接着,进入到webui文件夹里面,执行如下命令:
python webui.py --model-path /home/work/chatglm/chatglm_model --listen --port 8898 --precision fp16
上面参数主要是:模型路径、监听端口、以及模型工作模式;除此之外还有其它的几个参数没有用到。所有参数解释具体如下:
--model-path 指定模型路径
--listen 如果不加该参数,只能通过127.0.0.0本地访问。注意:在centos服务器上部署,该参数一定要加,不然没有办法通过IP加端口访问模型服务。
--port 没有啥好说的,指定端口用的。
--share 通过gradio进行分享,它会帮你生成一个域名连接,但是需要访问互联网。离线centos服务器部署用不到。
--precision 精度参数有4个,分别是fp32(只用CPU,32G内存以上), fp16,(12G以上显存) int4(8G以下显存使用), int8(8G显存使用)
--cpu 只应用CPU,无显卡的时候使用
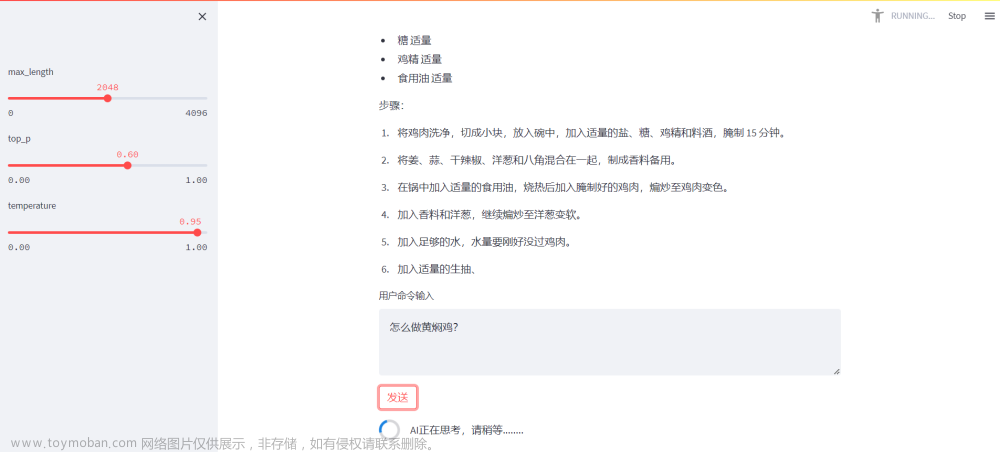
执行完以上命令之后,等待模型加载完成,通过IP+端口就可以访问服务啦!截图如下
7,资料获取

下载方式 关注: AINLPer 回复:chatglm6B
推荐阅读
[1] EMNLP2022 | 带有实体内存(Entity Memory)的统一编解码框架 (美国圣母大学)
[2] NeurIPS2022 | 训练缺少数据?你还有“零样本学习(zero-shot Learning)”(香槟分校)
[3] 一文了解EMNLP国际顶会 && 历年EMNLP论文下载 && 含EMNLP2022文章来源:https://www.toymoban.com/news/detail-418893.html
[4]【历年NeurIPS论文下载】一文带你看懂NeurIPS国际顶会(内含NeurIPS2022)文章来源地址https://www.toymoban.com/news/detail-418893.html
到了这里,关于Centos/Ubuntu离线部署清华chatGLM(特别详细,十分钟搞定)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!