本地化部署大语言模型 ChatGLM
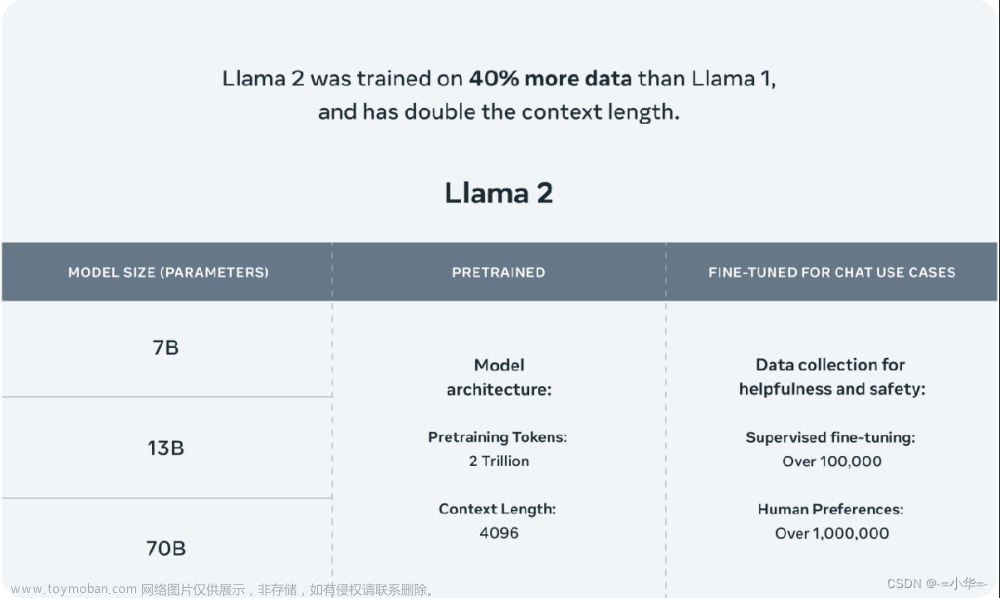
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。
前期筹备
GitHub 基础包
GitHub: ChatGLM-6B
下载 ChatGLM-6B 压缩包到本地

语言模型文件
Hugging Face: Model
下载 训练好的 语言模型文件

每一个都要下载

基础配置
解压 ChatGLM-6B-main.zip 文件

新建一个名为 model 的文件夹

把刚才在 Hugging Face 上下载的所有文件都放进来
应该是 20 个 检查一下

返回 ChatGLM-6B-main 跟目录 找到名为 web_demo.py 的文件

可以用记事本 或则 其他工具打开

更改第 4、5行代码
原本代码:
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
修改过后代码:
tokenizer = AutoTokenizer.from_pretrained("model", trust_remote_code=True)
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().quantize(4).cuda()
就是把 THUDM/chatglm-6b 更改为 model
并在 half()方法之后添加 quantize(4) 方法

量化需求:
如果显存小于14G 就使用 quantize(4) 方法 如果你要使用 quantize(8)你就要关闭所有应用
说一下我的电脑配置:i7、16G内存、2060ti显卡(6G显存)
各位看官老爷自己对比一下

显存查看方法
Win + R 键 打开命令窗口
输入 dxdiag 然后点击确认

打开系统自带的诊断工具之后 随便点一个显示

这个显示内存就是你的 显存

Anaconda 模块
Anaconda 官网: Anaconda 官网
ChatGLM-6B 网页部署
Anaconda 环境创建
打开 Anaconda 点击 Environments

新建一个环境

起一个名字
注意:记住 Python 版本 有点重要 最好使用 3.10.10
如果没有可以在官网重新下载 更新一下

点击那个运行按钮 并打开 Open Terminal

根目录操作
输入 D: 进入相应硬盘

使用 cd 命令 进入到 ChatGML 根目录
我这边是 D:\Unity\ChatGLM-6B\ChatGLM-6B-main
大家根据自己的 解压路径进行 打开

基础依赖加载
键入 pip install -r requirements.txt
加载依赖项 反正我这边是会加载不完全

transformers 和 protobuf 库加载
下载 protobuf 和 transformers 库支持
pip install protobuf==3.20.0 transformers==4.27.1 icetk cpm_kernels

因为要使用 Web 显示 所以也需要加载 gradio库
pip install gradio

先启动跑一下看看 能不能运行的起来 万一可以呢 是吧
python web_demo.py

Pytorch 源修改
Pytorch: Pytorch
报错:AssertionError: Torch not compiled with CUDA enabled
这个就是 只支持 CPU 的 CUDR 问题不大
去 Pytorch 找到对应的 直接 conda

注意选择对啊
如果conda 实在是卡的不能行的话 你就试试 pip
两个命令都给你:
conda: conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
pip: pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117


当出现这一句的时候 你直接 输入 y 回车就行

依赖库补充
下载完毕之后你会发现 还是缺少依赖库 找到相应名称
比如这个 chardet 直接 pip install
pip install chardet

再次运行 python web_demo.py 命令

好吧 果然不可以 缺少 cchardet库
那就继续下载呗
pip install cchardet

来了来了 全场最大的麻烦来了
明明下载都下载好了 就是无法执行 你气不气

找了一百年 重新下载也不行 换成清华源 也不行
最后的最后 就想着要不换下轮子呢

补充依赖 pypi 配置
pypi: pypi官网
在搜索框输入 你想要查询库名称

注意选择对应的 系统 我是 win64 所以就选择了第一个
这里还有一个坑

cd 到你存放 刚刚下载文件的目录

cchardet 依赖错误解决
输入 pip install D:\Unity\ChatGLM-6B\cchardet-2.1.7-cp39-cp39-win_amd64.whl
这是我的路径 各位 自行更改哈
然后你会发现 又错了!!!
不能用 完犊子 真的差点吐血 好在是解决了

回到下载文件夹 各位还记得 自己创建环境时的 Python 版本吗 对 就是那个!
原本名称是 cp39 改成 cp310 就能用了
真真不想吐槽了

你要是不知道自己环境对应的 就输入:
pip debug --verbose
按照对应的更改一下就行了

执行 pip install D:\Unity\ChatGLM-6B\cchardet-2.1.7-cp310-cp310-win_amd64.whl

成功 毫无悬念

cd 到ChatGLM 根目录
cd D:\Unity\ChatGLM-6B\ChatGLM-6B-main

再次运行 python web_demo.py
发现还是不行 那还说什么 上大招

强制 归一化
强制 最新归一化
pip install --force-reinstall charset-normalizer==3.1.0

再次启动
python web_demo.py
搓手等待...

网页部署成功
天见犹怜 终于终于 成功了
真是一波三折 再三折 好在是成功了

好了大家可以尽情的调教自己的 GPT 了

ChatGLM-6B 本地部署
Anaconda Terminal
在上面创建好的环境下 重新打开 执行 Terminal

导航到 根目录

依赖项加载
使用 pip install fastapi uvicorn 命令安装相关 依赖

api.py 文件修改
在根目录找到 api.py 文件并打开

初始代码:这两句在 53、54行
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
更改为下面的:稍微解释一下。
因为我的模型放在了根目录的 model 文件夹下 所以把 "THUDM/chatglm-6b" 更改为了 "model"
你们也可以按需更改。
tokenizer = AutoTokenizer.from_pretrained("model", trust_remote_code=True)
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().cuda()
可以直接替换的完整代码:
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI()
@app.post("/")
async def create_item(request: Request):
global model, tokenizer
json_post_raw = await request.json()
json_post = json.dumps(json_post_raw)
json_post_list = json.loads(json_post)
prompt = json_post_list.get('prompt')
history = json_post_list.get('history')
max_length = json_post_list.get('max_length')
top_p = json_post_list.get('top_p')
temperature = json_post_list.get('temperature')
response, history = model.chat(tokenizer,
prompt,
history=history,
max_length=max_length if max_length else 2048,
top_p=top_p if top_p else 0.7,
temperature=temperature if temperature else 0.95)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {
"response": response,
"history": history,
"status": 200,
"time": time
}
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log)
torch_gc()
return answer
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("model", trust_remote_code=True)
model = AutoModel.from_pretrained("model", trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
api.py 执行
执行命令:python api.py

本地化部署 成功
可以自己设置访问网址和端口 只要设置好就行。
我这边直接使用的是默认的:http://127.0.0.1:8000 或者 http://0.0.0.0:8000

发送 Json 数据 Unity 模块
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
/// <summary>
/// 发送 数据
/// </summary>
[System.Serializable]
public class PostDataJson_ZH
{
/// <summary>
/// 发送信息
/// </summary>
public string prompt;
/// <summary>
/// 细节
/// </summary>
public List<string> history;
}
接收 Json 数据 Unity 模块
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
/// <summary>
/// 接收 数据
/// </summary>
[System.Serializable]
public class AcceptJson_ZH
{
/// <summary>
/// 返回消息
/// </summary>
public string response;
/// <summary>
/// 多个回答
/// </summary>
public List<List<string>> history;
/// <summary>
/// 状态
/// </summary>
public int status;
/// <summary>
/// 返回事件
/// </summary>
public string time;
}
Unity 结合
using System.Collections;
using System.Collections.Generic;
using System.Net;
using System.Net.Sockets;
using System.Threading;
using UnityEngine;
using UnityEngine.Networking;
using UnityEngine.UI;
public class ChatGLM_ZH : MonoBehaviour
{
[Header("本地化访问网址")]
public string _OpenAIUrl= "http://127.0.0.1:8000";
[Header("基础模板设置")]
[SerializeField]
public PostDataJson_ZH _PostData = new PostDataJson_ZH();
[Header("接收数据")]
public string _RobotChatText;
[Header("问题")]
public string _SendMessage= "你好";
void Update()
{
if (Input.GetKeyDown(KeyCode.Q))
{
_SendMessage = GameObject.Find("输入").GetComponent<InputField>().text;
StartCoroutine(GetPostData(_SendMessage));
}
}
/// <summary>
/// POST 方法请求
/// </summary>
/// <param 问题="_SendMessage"></param>
/// <returns></returns>
private IEnumerator GetPostData(string _SendMessage)
{
using (UnityWebRequest _Request = new UnityWebRequest(_OpenAIUrl, "POST"))
{
//{"prompt": "你好", "history": []}
_PostData.prompt = _SendMessage;
//数据转换
string _JsonText = JsonUtility.ToJson(_PostData);
print(_JsonText);
byte[] _Data = System.Text.Encoding.UTF8.GetBytes(_JsonText);
//数据上传 等待响应
_Request.uploadHandler = new UploadHandlerRaw(_Data);
_Request.downloadHandler = new DownloadHandlerBuffer();
//数据重定向
_Request.SetRequestHeader("Content-Type", "application/json");
//等待响应 开始与远程服务器通信
yield return _Request.SendWebRequest();
//数据返回
if (_Request.responseCode == 200)
{
//接收返回信息
string _Message = _Request.downloadHandler.text;
print(_Message);
//数据转换
AcceptJson_ZH _Textback = JsonUtility.FromJson<AcceptJson_ZH>(_Message);
//确保当前有消息传回
if (_Textback.response != null)
{
//输出显示
_RobotChatText = _Textback.response;
GameObject.Find("输出").GetComponent<Text>().text = _RobotChatText;
}
}
}
}
}
本地化 运行 效果
命令行 输出

Unity 输出

使用网址合集
GitHub: ChatGLM-6B
Hugging Face: Model
Anaconda 官网: Anaconda 官网
Pytorch: Pytorch
Pypi: pypi官网
清华大学镜像网站: 清华大学镜像网站文章来源:https://www.toymoban.com/news/detail-419046.html
执行命令合集
//基础包依赖加载
pip install -r requirements.txt
//transformers 和 protobuf 依赖加载
pip install protobuf==3.20.0 transformers==4.27.1 icetk cpm_kernels
//网页使用 gradio 库 加载
pip install gradio
//网页 启动命令
python web_demo.py
//CPU 转换
conda: conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
pip: pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
//chardet 库 补充依赖
pip install chardet
//cchardet 库 补充依赖
pip install cchardet
//查看当前平台支持的版本
pip debug --verbose
//cchardet 库 轮子 加载
pip install D:\Unity\ChatGLM-6B\cchardet-2.1.7-cp310-cp310-win_amd64.whl
//强制 最新归一化
pip install --force-reinstall charset-normalizer==3.1.0
//启动命令
python web_demo.py
//torchnet 库下载
pip install torchnet
//显卡 CUDA 版本查询
nvidia-smi
//本地化 依赖加载
pip install fastapi uvicorn
//本地化 启动命令
python api.py
//断开服务
Ctrl + C
//清华源 镜像
核心句式:-i https://pypi.tuna.tsinghua.edu.cn/simple
例如下载的是:cchardet
正常下载是:pip install cchardet
清华源下载是:pip install cchardet -i https://pypi.tuna.tsinghua.edu.cn/simple
暂时先这样吧,如果有时间的话就会更新模型微调文章以及抽时间更新GLM130B的部署,实在看不明白就留言,看到我会回复的。
路漫漫其修远兮,与君共勉。文章来源地址https://www.toymoban.com/news/detail-419046.html
到了这里,关于本地化部署大语言模型 ChatGLM的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!