0、k8s安装、docker安装
参考:前两步Ubuntu云原生环境安装,docker+k8s+kubeedge(亲测好用)_爱吃关东煮的博客-CSDN博客_ubantu部署kubeedge
配置节点gpu:
K8S调用GPU资源配置指南_思影影思的博客-CSDN博客_k8s 使用gpu
1、重置和清除旧工程:每个节点主机都要运行
kubeadm reset
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X2、部署新的k8s项目:
只在主节点运行,apiserver-advertise-address填写主节点ip
sudo kubeadm init \
--apiserver-advertise-address=192.168.1.117 \
--control-plane-endpoint=node4212 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.21.10 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config主节点完成后,子节点运行主节点完成后展示的join命令
3、装网络插件
curl https://docs.projectcalico.org/manifests/calico.yaml -O
kubectl apply -f calico.yaml等待完成
4、装bashboard:主节点运行
sudo kubectl apply -f /dashbord.yaml
sudo kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
将type: ClusterIP 改为 type: NodePort# 找到端口,关闭对应防火墙
sudo kubectl get svc -A |grep kubernetes-dashboard
任意主机ip:31678为实际访问连接(https://192.168.1.109:31678/)
验证所有pod为run状态,否则检查前面步骤
kubectl get pods --all-namespaces -o wide
#查看pod状态
kubectl describe pod kubernetes-dashboard-57c9bfc8c8-lmb67 --namespace kubernetes-dashboard
#打印log
kubectl logs nvidia-device-plugin-daemonset-xn7hx --namespace kube-system创建访问账号
kubectl apply -f /dashuser.yaml获取访问令牌,在主节点运行,每天都会更新
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"填入token

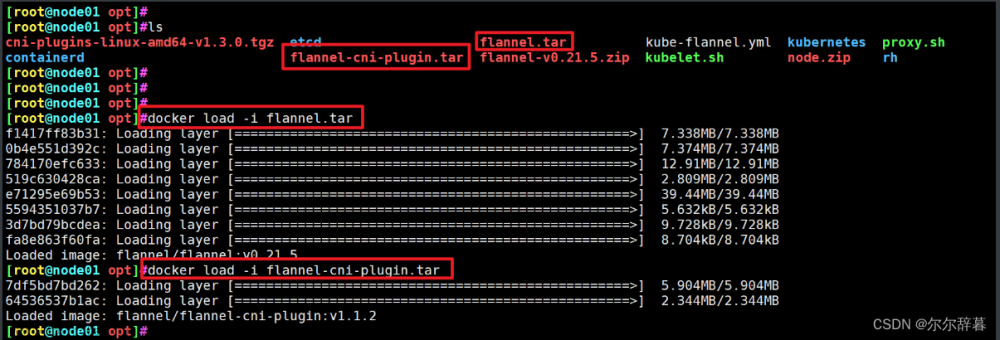
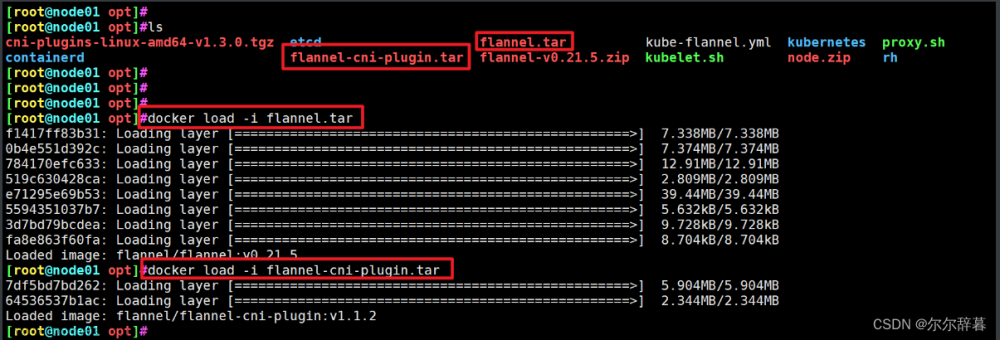
5、创建镜像并上传dockerhub:
查看本地镜像:docker images
登陆docker账户
给docker打标签,左:本地名:tag 右hub用户名/仓库名:tag
docker tag deeplabv3plus:1.0.0 chenzishu/deepmodel:labv3
上传hub
docker push chenzishu/deepmodel:labv3
6、dashboard使用
创建deployment
应用名随意,镜像地址填写docherhub上对应镜像地址(chenzishu/deepmodel:pytorch)
等待容器运行,需要时间

########
#pod启动后一直重启,并报Back-off restarting failed container
#找到对应的deployment添加
command: ["/bin/bash", "-ce", "tail -f /dev/null"]
######## 
7、运行pod:
显示本地容器:docker ps -a
找到容器:
kubectl get pods --all-namespaces -o wide
进入容器:
kubectl exec -it segnet-747b798bf5-4bjqk /bin/bash
查看容器中文件:
ls
nvidia-smi查看容器是否可以调用gpu
8、容器使用显卡资源,gpu资源分片
https://gitcode.net/mirrors/AliyunContainerService/gpushare-scheduler-extender/-/blob/master/docs/install.md
先安装nvidia-docker2:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo systemctl restart docker
#测试
sudo docker run --rm --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smiupdate可能会报错:参见官方文档Conflicting values set for option Signed-By error when running apt update
E: Conflicting values set for option Signed-By regarding source https://nvidia.github.io/libnvidia-container/stable/ubuntu18.04/amd64/ /: /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg !=
E: The list of sources could not be read.解决方法:
grep -l "nvidia.github.io" /etc/apt/sources.list.d/* | grep -vE "/nvidia-container-toolkit.list\$"
删除列出的文件即可
安装 gpushare-device-plugin 之前,确保在 GPU 节点上已经安装 Nvidia-Driver 以及 Nvidia-Docker2,同时已将 docker 的默认运行时设置为 nvidia:
配置runtime:/etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}GPU Sharing 部署
再参考阿里开发文档,写的很详细 :配置、使用nvidia-share:https://developer.aliyun.com/article/690623
K8S 集群使用阿里云 GPU sharing 实现 GPU 调度 - 点击领取 (dianjilingqu.com)
部署 GPU 共享调度插件 gpushare-schd-extender
cd /tmp/
curl -O https://raw.githubusercontent.com/AliyunContainerService/gpushare-scheduler-extender/master/config/gpushare-schd-extender.yaml
kubectl create -f gpushare-schd-extender.yaml
# 需要能够在 master 上进行调度,在 gpushare-schd-extender.yaml 中将
# nodeSelector:
# node-role.kubernetes.io/master: ""
# 这两句删除,使 k8s 能够在 master 上进行 GPU 调度
### 无法下载参考如下链接:
wget http://49.232.8.65/yaml/gpushare-schd-extender.yaml部署设备插件 gpushare-device-plugin
cd /tmp/
wget https://raw.githubusercontent.com/AliyunContainerService/gpushare-device-plugin/master/device-plugin-rbac.yaml
kubectl create -f device-plugin-rbac.yaml
wget https://raw.githubusercontent.com/AliyunContainerService/gpushare-device-plugin/master/device-plugin-ds.yaml
# 默认情况下,GPU 显存以 GiB 为单位,若需要使用 MiB 为单位,需要在这个文件中,将 --memory-unit=GiB 修改为 --memory-unit=MiB
kubectl create -f device-plugin-ds.yaml
### 无法下载参考如下链接:
wget http://49.232.8.65/yaml/device-plugin-rbac.yaml
wget http://49.232.8.65/yaml/device-plugin-ds.yaml为 GPU 节点打标签
# 为了将 GPU 程序调度到带有 GPU 的服务器,需要给服务打标签 gpushare=true
kubectl get nodes
# 选取 GPU 节点打标
kubectl label node <target_node> gpushare=true
kubectl describe node <target_node>更新 kubectl 可执行程序
wget https://github.com/AliyunContainerService/gpushare-device-plugin/releases/download/v0.3.0/kubectl-inspect-gpushare
chmod u+x kubectl-inspect-gpushare
mv kubectl-inspect-gpushare /usr/local/bin
### 无法下载参考如下链接:
wget http://49.232.8.64/k8s/kubectl-inspect-gpushare查看 GPU 信息:若能看到 GPU 信息,则代表安装成功
root@dell21[/root]# kubectl inspect gpushare
NAME IPADDRESS GPU0(Allocated/Total) PENDING(Allocated) GPU Memory(GiB)
10.45.61.22 10.45.61.22 0/7 2 2/7
------------------------------------------------------
Allocated/Total GPU Memory In Cluster:
2/7 (28%) 9、部分问题
pod无法启动、资源不足文章来源:https://www.toymoban.com/news/detail-419279.html
#设置污点阈值
systemctl status -l kubelet
#文件路径
/etc/systemd/system/kubelet.service.d/
#放宽阈值
#修改配置文件增加传参数,添加此配置项 --eviction-hard=nodefs.available<3%
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --eviction-hard=nodefs.available<3%"
systemctl daemon-reload
systemctl restart kubeletpod反复重启:文章来源地址https://www.toymoban.com/news/detail-419279.html
pod启动后一直重启,并报Back-off restarting failed container
找到对应的deployment
command: ["/bin/bash", "-ce", "tail -f /dev/null"]
spec:
containers:
- name: test-file
image: xxx:v1
command: ["/bin/bash", "-ce", "tail -f /dev/null"]
imagePullPolicy: IfNotPresent
到了这里,关于K8S部署后的使用:dashboard启动、使用+docker镜像拉取、容器部署(ubuntu环境+gpu3080+3主机+部署深度学习模型)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!