🎊专栏【数据结构】
🍔喜欢的诗句:更喜岷山千里雪 三军过后尽开颜。
🎆音乐分享【星辰大海】
大一同学小吉,欢迎并且感谢大家指出我的问题🥰

目录
⭐时间复杂度分类
🍔 方法
🎈平方阶
🎈立方阶
🎈对数阶
🍔例子
✨常数时间复杂度 O(1)
🎈数组读取、索引和赋值
🎈判断一个整数是否为偶数或奇数
🎈 返回固定长度的数组,字符串或其他数据结构
✨线性时间复杂度O(n)
🎈遍历数组或列表中的元素
🎈线性搜索算法
🎈求数组或列表的元素之和或平均值
✨对数时间复杂度O(log n)
🎈二分查找
🎈堆排序算法
✨平方时间复杂度O(n^2)
🎈冒泡排序
🎈插入排序算法
✨立方时间复杂度
三重循环
✨指数时间复杂度 O(2^n)
🎈斐波那契数列
🍔易错分析
✨误以为时间复杂度都要用 n 表示
🎈递归的时间复杂度
🎈数据规模的影响
一个算法的执行时间大致上等于其所有语句执行时间的总和
一个语句的执行时间为该条语句的重复执行次数和执行一次所需时间的乘积
⭐时间复杂度分类
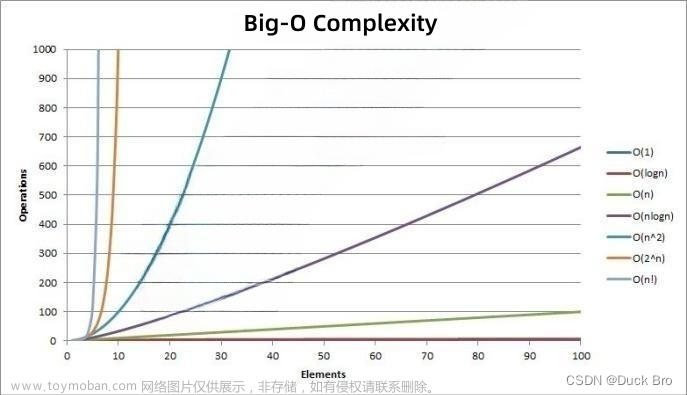
算法的时间复杂度是指运行算法所需的时间与问题规模之间的增长关系。通常用大O符号来表示算法的时间复杂度,也被称为渐进时间复杂度。算法时间复杂度分为以下几类:
-
常数时间复杂度 O(1):无论问题规模如何变化,算法的运行时间都保持不变。
-
线性时间复杂度 O(n):当输入规模n线性增加时,算法的运行时间呈现出线性增长趋势。
-
对数时间复杂度 O(log n):当输入规模n呈指数增长时,算法的运行时间呈对数增长趋势。
-
平方时间复杂度 O(n^2):当输入规模n线性增加时,算法的运行时间呈现出平方增长趋势。
-
立方时间复杂度O(n^3):当输入规模n线性增加时,算法的运行时间呈现出立方增长趋势。
-
指数时间复杂度 O(2^n):当问题规模成指数增长时,算法的运行时间将会急剧增加。
在设计和优化算法时,理解算法的时间复杂度非常重要。因为时间复杂度直接影响着算法的效率和可扩展性,我们应该尽可能选择时间复杂度低的算法来解决问题。
🍔 方法
找程序段里面频度最大的语句
🎈平方阶
1 x=0;y=0;
2 for(int i=1;i<=n;i++)
3 x++;
4 for(int j=1;j<=n;j++)
5 for(int k=1;k<=n;k++)
6 y++;
这个程序段里面频度最大的语句是第6句,是n^2
🎈立方阶
1 x=1;
2 for(int i=1;i<=n;i++)
3 for(int j=1;j<=i;j++)
4 for(int k=1;k<=j;k++)
5 x++;
文章来源地址https://www.toymoban.com/news/detail-419674.html
这个程序段里面频度最大的语句是第5句,是n^3

🎈对数阶
1 for(int i=1;i<=n;i*=2)
2 {
3 x++;
4 }

🍔例子
✨常数时间复杂度 O(1)
常数时间复杂度 O(1) 的算法指的是无论输入规模如何变化,该算法的运行时间都保持不变。这种算法的执行时间与具体输入的数据规模无关,通常是表格查找、数组索引或者直接返回常量值等简单的操作。
🎈数组读取、索引和赋值
int array[] = {1, 2, 3, 4, 5}; // 声明一个数组
int x = array[2]; // 读取数组中第三个元素,即3
array[3] = 10; // 修改数组中第四个元素,将其改为10
🎈判断一个整数是否为偶数或奇数
int num = 7;
if (num % 2 == 0) {
cout << num << " is even." << endl;
} else {
cout << num << " is odd." << endl;
}
🎈 返回固定长度的数组,字符串或其他数据结构
int* getFixedArray() {
return new int[5]{1, 2, 3, 4, 5}; // 返回一个固定长度的数组
}string getFixedString() {
return "Hello, world!"; // 返回一个固定长度的字符串
}
✨线性时间复杂度O(n)
要从头到尾遍历一遍
线性时间复杂度 O(n) 的算法指的是随着输入规模n的增长,该算法的运行时间呈现出线性增长趋势。也就是说,当输入规模n增加1倍时,算法的运行时间也增加了1倍。通常情况下,O(n)的算法需要对数据进行从头到尾的遍历处理。
🎈遍历数组或列表中的元素
int array[] = {1, 3, 5, 7, 9};
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++) {
cout << array[i] << " "; // 输出数组中的每一个元素
}
以上代码中,遍历数组中的元素需要从头到尾逐个访问,时间复杂度为 O(n)。
🎈线性搜索算法
从数组或列表的开头开始逐个比较元素的值,直到找到目标元素或遍历完整个数组或列表。
bool linearSearch(int array[], int target) {
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++) {
if (array[i] == target) return true;
}
return false;
}
🎈求数组或列表的元素之和或平均值
int sum(int array[]) {
int result = 0;
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++) {
result += array[i];
}
return result;
}double average(int array[]) {
return sum(array) / (double)(sizeof(array) / sizeof(array[0]));
}
✨对数时间复杂度O(log n)
对数时间复杂度 O(log n) 的算法指的是随着输入规模n的增长,该算法执行时间呈现出对数增长趋势。例如,当输入规模n增加1倍时,算法的运行时间可能会增加约2倍。常见的O(log n)算法通常是使用二分查找或者树结构等数据结构实现的。
🎈二分查找
int binarySearch(int array[], int size, int target) {
int left = 0;
int right = size - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (array[mid] == target) return mid;
else if (array[mid] < target) left = mid + 1;
else right = mid - 1;
}
return -1;
}
以上代码中,二分查找算法每次将元素范围缩小一半,时间复杂度为 O(log n)
🎈堆排序算法
void heapify(int array[], int size, int i) {
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if (left < size && array[left] > array[largest]) largest = left;
if (right < size && array[right] > array[largest]) largest = right;
if (largest != i) {
swap(array[i], array[largest]);
heapify(array, size, largest);
}
}void heapSort(int array[], int size) {
for (int i = size / 2 - 1; i >= 0; i--) {
heapify(array, size, i);
}
for (int i = size - 1; i > 0; i--) {
swap(array[0], array[i]);
heapify(array, i, 0);
}
}
以上代码中,堆排序算法使用了二叉堆的数据结构,每次都将元素拆分为两个相等长度的子集,并递归处理其中一个子集。因此,堆排序的时间复杂度为 O(log n)。在实现时,我们使用heapify()函数维护二叉堆的性质,用两个for循环来进行堆排序。
✨平方时间复杂度O(n^2)
平方时间复杂度 O(n^2) 的算法指的是随着输入规模n的增长,该算法执行时间呈现出平方增长趋势。例如,当输入规模n增加1倍时,算法的运行时间会增加约4倍
🎈冒泡排序
双重for循环
void bubbleSort(int array[], int size) {
for (int i = 0; i < size - 1; i++) {
for (int j = 0; j < size - i - 1; j++) {
if (array[j] > array[j + 1]) swap(array[j], array[j + 1]);
}
}
}
以上代码中,冒泡排序算法使用每一次内层循环来比较相邻元素的大小,并根据需要交换它们的位置,时间复杂度为 O(n^2)。在实现时,我们使用两个for循环分别遍历整个数组并比较相邻的元素。
🎈插入排序算法
void insertSort(int array[], int size) {
for (int i = 1; i < size; i++) {
int key = array[i];
int j = i - 1;
while (j >= 0 && array[j] > key) {
array[j + 1] = array[j];
j--;
}
array[j + 1] = key;
}
}
✨立方时间复杂度
三重循环
在这个例子中,我们使用了三重循环来演示立方阶时间复杂度的算法,其中第一重循环运行了 n 次,第二重循环也运行了 n 次,第三重循环也运行了 n 次,因此总的计算次数为 n * n * n,也就是立方阶时间复杂度 O(n^3)。
#include <iostream>
using namespace std;
int main() {
int n; // 输入规模
cin >> n;for (int i = 0; i < n; i++) { // 第一重循环
for (int j = 0; j < n; j++) { // 第二重循环
for (int k = 0; k < n; k++) { // 第三重循环
cout << i * j * k << " "; // 立方阶计算
}
}
}return 0;
}
在实际编程中,由于立方阶算法的效率非常低下,通常应该尽可能避免使用它,或者通过一些技巧将其转化为更高效的算法,以提高程序的性能。
✨指数时间复杂度 O(2^n)
指数时间复杂度是指算法执行的时间与数据规模 n 的指数成正比,通常表示为 O(2^n)。一种计算方式是,在算法中使用了嵌套循环或递归,每次运算次数都是上一次的两倍或更多,这种情况就容易出现指数级别的时间复杂度。
🎈斐波那契数列
#include <iostream>
using namespace std;int fib(int n) {
if (n <= 1) {
return n;
} else {
return fib(n - 1) + fib(n - 2);
}
}int main() {
int n = 10;
for (int i = 0; i < n; i++) {
int res = fib(i);
cout << res << " ";
}
cout << endl;
return 0;
}
🍔易错分析
✨误以为时间复杂度都要用 n 表示

这个例子,就用了 n 和 m 两个字母
🎈递归的时间复杂度
递归算法在实现某些功能时非常方便,但是在计算时间复杂度时需要格外注意。因为递归调用会导致函数的多次调用,从而增加程序的时间复杂度。
🎈数据规模的影响
算法的时间复杂度与数据规模有关,当数据规模较小时,算法的时间复杂度可能看起来并不显著,但是随着数据规模的增大,算法的时间复杂度也会明显增加。因此,在测试算法时间复杂度时,需要考虑不同数据规模下的运行时间。
如果大家发现文章里面的问题和不明白的地方,欢迎提出自己的见解和疑问🥰
Code over!文章来源:https://www.toymoban.com/news/detail-419674.html
到了这里,关于【数据结构】时间复杂度(详细解释,例子分析,易错分析,图文并茂)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!