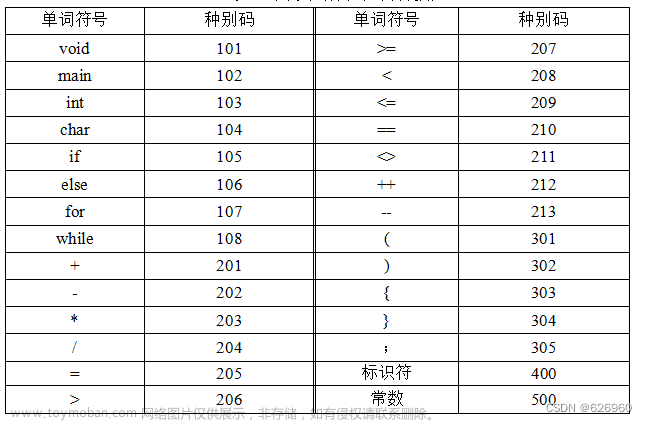
本实验基于词法分析程序实现,可参考本人前面的文章。
目录
一、目标任务
二、程序功能描述
三、主要数据结构描述
四、程序结构描述
设计方法
First集和Follow集
递归子程序框图
函数定义及函数之间的调用关系
五、程序测试
测试用例1
测试结果1
测试用例2
测试结果2
测试用例3
测试结果3
测试用例4
测试结果4
一、目标任务
完成以下描述赋值语句的 LL(1)文法的递归下降分析程序
G[S]: S→V=E
E→TE′
E′→ATE′|ε
T→FT′T′→MFT′|ε
F→ (E)|i
A→+|-
M→*|/
V→i终结符号 i 为用户定义的简单变量,即标识符的定义。
二、程序功能描述
输入词法分析输出的二元式序列,能够输出该算术表达式是否为该文发定义的判断结果;
输出二元式序列对应的算术表达式;
输出算术表达式对应的单词符号类别编码;
输出递归下降语法分析的过程;
能够通过递归下降分析发现简单的语法错误。
三、主要数据结构描述
常量MAX_LENG定义数组的最大长度;
sign用于标记语句是否正确;
key[MAX_LENG]存放单词符号的编码类别;
buf[MAX_LENG]保存词法分析程序的二元式序列;
shuru[MAX_LENG]保存待检测的算术表达式;
len为buf的长度。
四、程序结构描述
设计方法
First集和Follow集

递归子程序框图








函数定义及函数之间的调用关系
S():调用V、E
E():调用E’
E’():调用A、T、E’
T():调用F、T’、
T’():调用M、F、T’
F():调用E
A()
M()
V()
五、代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_LENG 1024
int i;
int sign=0;//标记语句是否正确
int key[MAX_LENG];//存放单词符号的编码类别
void S();
void E();
void E_();
void T();
void T_();
void F();
void A();
void M();
void V();
void S(){
if(sign==0){
printf("S ");
if(key[i]==1){
V();
if(sign==0&&key[i]==31){
i++;
E();
}
else{
sign=1;
printf("\nS处出现错误\n");
}
}
else{
sign=1;
printf("\nS处出现错误\n");
}
}
}
void E(){
if(sign==0){
printf("->E ");
if(key[i]==23||key[i]==1){
T();
if(sign==0){
if(key[i]==16||key[i]==17){
E_();
}else if(key[i]==24||key[i]==-1){
return;
}else{
sign=1;
printf("\nE处出现错误\n");
}
}
}else{
sign=1;
printf("\nE处出现错误\n");
}
}
}
void E_(){
if(sign==0){
printf("->E' ");
if(key[i]==16||key[i]==17){
A();
if(sign==0){
if(key[i]==23||key[i]==1){
T();
if(sign==0){
if(key[i]==16||key[i]==17){
E_();
}else if(key[i]==24||key[i]==-1){
return;
}else{
sign=1;
printf("\nE'处出现错误\n");
}
}
}else{
sign=1;
printf("\nE'处出现错误\n");
}
}
}else if(key[i]==24||key[i]==-1){
return;
}else{
sign=1;
printf("\nE'处出现错误\n");
}
}
}
void T(){
if(sign==0){
printf("->T ");
if(key[i]==23||key[i]==1){
F();
if(sign==0){
if(key[i]==18||key[i]==19){
T_();
}else if(key[i]==16||key[i]==17||key[i]==24||key[i]==-1){
return;
}else{
sign=1;
printf("\nT处出现错误\n");
}
}
}else{
sign=1;
printf("\nT处出现错误\n");
}
}
}
void T_(){
if(sign==0){
printf("->T' ");
if(key[i]==18||key[i]==19){
M();
if(sign==0){
F();
if(sign==0){
T_();
}
}
}else if(key[i]==16||key[i]==17||key[i]==24||key[i]==-1){
return;
}else{
sign=1;
printf("\nT'处出现错误\n");
}
}
}
void F(){
if(sign==0){
printf("->F ");
if(key[i]==23){
i++;
if(key[i]==23||key[i]==1){
E();
if(sign==0){
if(key[i]==24){
i++;
}
else{
sign=1;
printf("\nF处出现错误\n");
}
}
}
else{
sign=1;
printf("\nF处出现错误\n");
}
}
else if(key[i]==1){
i++;
}
else{
sign=1;
printf("\nF处出现错误\n");
}
}
}
void A()
{
if(sign==0){
printf("->A ");
if(key[i]==16||key[i]==17){
i++;
}
else{
sign=1;
printf("\nA处出现错误\n");
}
}
}
void M()
{
if(sign==0){
printf("->M");
if(key[i]==18||key[i]==19){
i++;
}
else{
sign=1;
printf("\nM处出现错误\n");
}
}
}
void V()
{
if(sign==0){
printf("->V ");
if(key[i]==1){
i++;
}
else{
sign=1;
printf("\nV处出现错误\n");
}
}
}
int main(){
FILE *fp;
char buf[MAX_LENG]={0};//用于保存文件词法分析的结果
char shuru[MAX_LENG]={0};//shuru为待检测的语句
int len;//buf的长度
int k=0,x=0,j=0;
printf("词法分析二元式序列:\n");
if((fp=fopen("demo_out.txt","r"))!=NULL){
while(fgets(buf,MAX_LENG,fp)!=NULL){//每次读取一行
len=strlen(buf);
buf[len]='\0';//去除换行符
printf("%s \n",buf);
for(i=0;i<len;i++){
if(buf[i]=='('){//将单词符号类别编码转换成数字
if(buf[i+2]!=',')//如果是十位数数字
key[j++]=int((buf[i+1]-'0')*10+buf[i+2]-'0');
else//如果是个位数数字
key[j++]=int(buf[i+1]-'0');
continue;
}
if(buf[i]==','){
i++;
if(buf[i]==')')//解决(24,))的情况
{
shuru[x++]=')';
i++;
continue;
}
while(buf[i]!=')'){//分析的词法可能多个字符,如果没有while则只能保存一个字符
shuru[x++]=buf[i];
i++;
}
}
}
}
}
shuru[x++]='#';
key[j++]=-1;
fclose(fp);
printf("算术表达式为:\n%s\n",shuru);
printf("算术表达式的单词符号类别编码依次为:\n");
for(i=0;i<j;i++)
printf("%d ",key[i]);
printf("\n");
if(key[0]==-1)//当输入的第一个字符为#,直接结束
return 0;
printf("递归下降语法分析过程:\n");
i=0;
S();
printf("\n");
if(key[i]==-1&&sign==0){
printf("此语句合法!\n");
}else{
printf("此语句不合法!\n");
}
return 0;
}六、程序测试
输入为词法分析程序的二元式序列
测试用例1
(1,a)(31,=)(1,b)(18,*)(1,c)(16,+)(1,d)(16,+)(1,e)

测试结果1

测试用例2
(1,a)(31,=)(1,b)(18,*)(1,c)(16,+)(23,()(1,d)(16,+)(1,e)(24,))

测试结果2

测试用例3
(1,a)(31,=)(1,b)(18,*)(1,c)(16,+)(1,d)(16,+)(1,e)(24,))

测试结果3

测试用例4
(1,p)(31,=)(1,a)(16,+)(23,()(1,b)(18,*)(23,()(1,c)(16,+)(1,d)(24,))(19,/)(1,e)(16,+)(23,()(1,x)(16,+)(1,y)(24,))

测试结果4
 文章来源:https://www.toymoban.com/news/detail-419920.html
文章来源:https://www.toymoban.com/news/detail-419920.html
如果对你有帮助,不妨点个赞~~~文章来源地址https://www.toymoban.com/news/detail-419920.html
到了这里,关于【编译原理】-- 递归下降语法分析设计原理与实现(C语言实现)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!