摘要
| 工作 | 内容 | 效果 |
|---|---|---|
| 提升复杂环境中目标检测的效果 | 采用通道注意力机制对 YOLO-V3 进行改进,增强网络对图像特征提取的能力 | 平均识别率较改进前增加 0.32% |
| 针对目前姿态估计角度存在离散性的问题 | 提出一种基于 VGG-16 主干网络嵌入最小面积外接矩形(MABR)算法,进行抓取位姿估计和角度优化 | 改进后的抓取角度与目标实际角度平均误差小于 2.47° |
| 搭建了一套视觉抓取系统 | 利用 UR5 机械臂、气动两指机械手、Realsense D435 相机及 ATI-Mini45 六维力传感器等设备 | 对不同物体进行抓取分类操作、对硬件的要求较低、并且将有害扭矩降低约 75% |
关键词
- 深度学习;
- 神经网络;
- 目标检测;
- 姿态估计;
- 机器人抓取;
| 学者 | 工作 |
|---|---|
| Mallick 等 | 通过深层卷积网络语义分割法实现物体的检测和定位,利用机械臂完成物体的分拣工作。 |
| 白成超 | 通过改进的 YOLO(You Only Look Once)算法实现目标检测,实现机械臂的抓取动作。 |
| 黄怡蒙 | 对 Tiny-YOLOV3 目标检测的结果进行三角函数转换,并控制机械臂完成物体抓取。 |
缺点:没有获取物体有效抓取点的位姿,抓取具有一定的局限性
| 学者 | 工作 |
|---|---|
| Jiang | 通过两步走模型框架,使用支持向量机排序算法预测物体的抓取点和角度 |
| Chu | 通过 ResNet-50 主干网络结合抓取建议框图实现物体抓取位姿预测。 |
| 夏浩宇 | 基于 Keypoit RCNN 改进模型的抓取检测算法,实现对管纱的有效抓取 |
| 提高了抓取成功率,但是存在预测抓取角度离散的问题,导致机械手容易与物体产生偏角,在抓取过程中容易改变物体当前状态甚至造成物体损坏,具有一定的干扰性 |
缺点:提高了抓取成功率,但是存在预测抓取角度离散的问题,导致机械手容易与物体产生偏角,在抓取过程中容易改变物体当前状态甚至造成物体损坏,具有一定的干扰性
- 准备阶段,首先利用张正友标定法获取相机的内部参数,接着通过探针法设置两指机械手末端中心,然后通过手眼标定获取机械臂和相机的坐标转换关系矩阵;
- 图像处理阶段,计算机首先对目标图像进行预处理,接着将处理后的数据传入到两个通道中:通道一采用通道注意力模块改进的 YOLO-V3 对物体进行目标检测;通道二采用 VGG-16 主干网络和最小面积外接矩形MABR算法对物体的抓取位姿进行预测和抓取角度连续化矫正;
- 控制阶段,PC 端与控制柜建立通信,并发送抓取点坐标和机械手偏转角度信息,进行抓取分类动作;
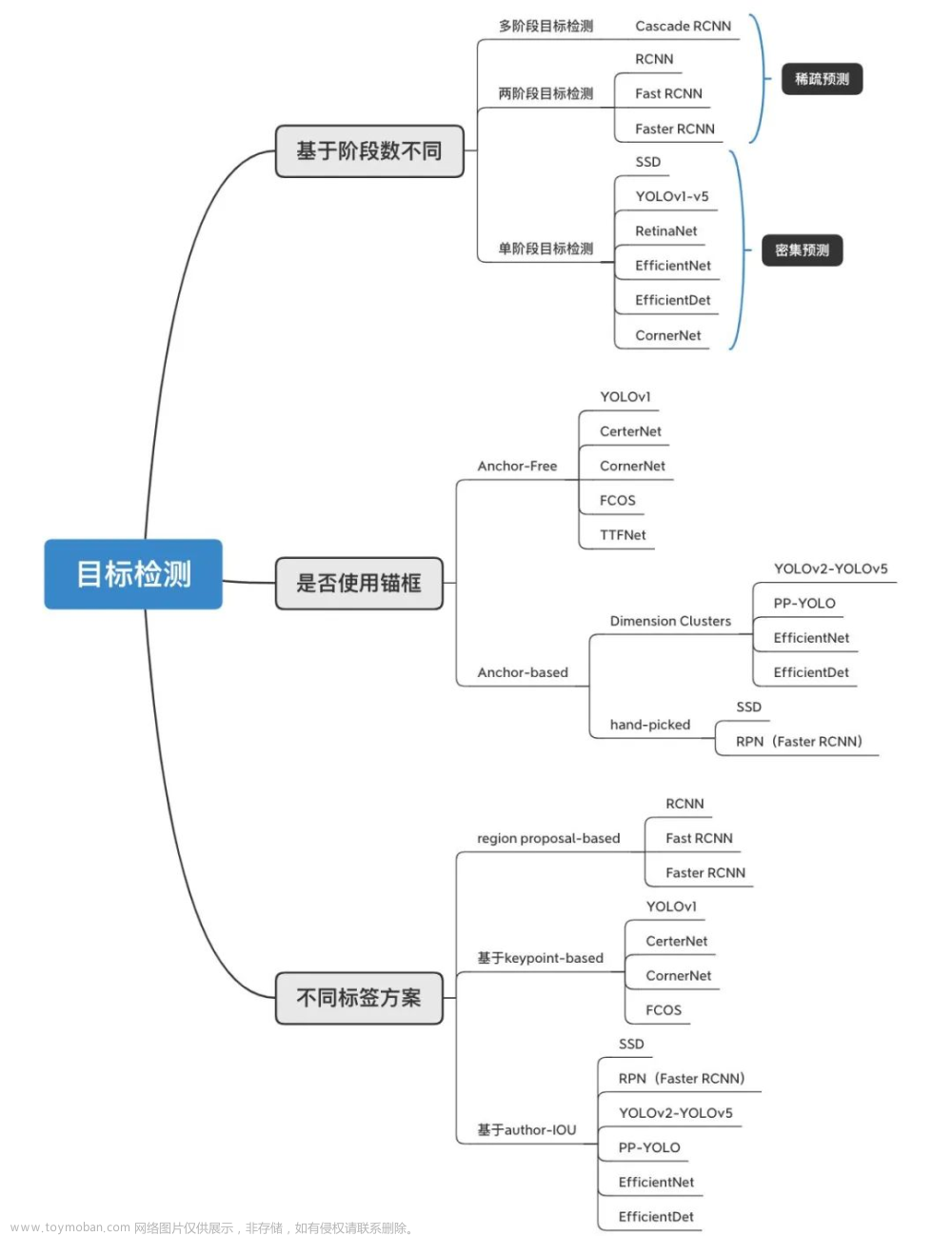
1 目标检测
自 2014 年 Girshick 等提出基于区域的卷积神经网络(Region proposals Convolutional Neural Networks, R-CNN)以来,该方向的目标检测算法不断地被改进,出现了以Fast R-CNN和Faster R-CNN为代表的先通过区域推荐再进行目标分类的两步走目标检测算法、以及以YOLO为代表的采用一个网络直接进行预测输出的目标检测算法等。
1.1 YOLO-V3 模型
YOLO 模型:
- 结合了候选区域调整和网络预测结果优化两个步骤
- 有端到端的网络结构特性
- 具有输入一张图像直接输出预测结果的功能
- 最大特点是整个网络的运行速度很快
YOLO-V3 模型:
- 多尺度预测模块,对象分类器由以前 softmax 函数改为 logistic 函数
- 借鉴特征金字塔网络(Feature Pyramid Network, FPN)的思想来对小、中、大物体预测
- Draknet-53 使用残差网络对图像特征进行更深层地提取

1.2 算法优化
通过对 YOLO-V3 检测模型加入通道注意力机制模块来增强网络提取特征
的效果,改善相机拍摄目标多尺度和图像场景复杂情况下的目标检测识别度和准确率,通道注意力机制模块如图。
利用权重矩阵对原网络结构中提取的目标特征进行重构,对有利特征信息进行加分无关特征进行减分处理,从而提升目标检测的效果。
2 抓取位姿估计
2.1 五维抓取框
| 种类 | 特点 |
|---|---|
| 3DOF | 目标抓取点的平面坐标 ( x , y ) (x, y) (x,y)和偏转角度 θ θ θ |
| 6DOF | 目标抓取点的空间坐标 ( x , y , z ) (x, y, z) (x,y,z)和旋转向量 ( r x , r y , r z ) (rx, ry, rz) (rx,ry,rz)组成 |
| 区别 | 多以工作台上的物体抓取为主,与空间位姿相比,平面的位姿估计方法更加高效、实用 |
2.2 抓取位姿估计模型
目前基于深度学习的抓取位姿估计算法,本质是对 RGB 或 RGD 图像进行回归预测和分类预测。
- 对单个目标进行位姿估计的单层网络
- 使用 VGG-16 网络替换 ResNet-50 进行特征提取
相比于由 49 个卷积层和 1 个全连接层组成 ResNet-50 网络,VGG-16 由 13 个卷积层和 3 个全连接层组成,网络结构深度不足 ResNet-50 的 1/3 - 单层的 VGG-16 网络结构满足对单个不同目标的准确预测且估计速度得到提升
网络总损失函数
L
g
c
r
L_{gcr}
Lgcr由抓取角度分类预测损失和四维边框预测损失组成
L
g
c
r
(
{
(
p
l
,
β
l
)
}
c
=
0
C
)
=
∑
c
L
g
c
r
−
c
l
s
(
p
t
)
+
λ
∑
c
l
c
≠
0
L
g
c
r
−
r
e
g
(
β
c
,
β
c
∗
)
L_{gcr}(\{ (p_{l},\beta_{l}) \}^{C}_{c=0})=\sum\limits_{c}L_{gcr-cls(p_{t})}+\lambda\sum\limits_{c}l_{c \neq 0}L_{gcr-reg(\beta_{c},\beta_{c}^{\ast})}
Lgcr({(pl,βl)}c=0C)=c∑Lgcr−cls(pt)+λc∑lc=0Lgcr−reg(βc,βc∗)
| 参数 | 意义 |
|---|---|
| C C C | R R R+1,取值19 |
| p l p_{l} pl | 经过 Softmax 归一化指数函数层输出第 l l l 个角度的分类概率 |
| β l / β c , β ∗ β_{l}/β_{c},β_{\ast} βl/βc,β∗ | 预测的抓取框和真实的抓取框 |
| L_{gcr-cls} | 抓取角度分类的交叉熵损失 |
| L_{gcr-reg} | 边界框预测的回归损失 |
2.3 角度优化
机械手与物体存在较大角度偏差
对工作台上容易移动的物体抓取影响较小,因为物体滑动会消除角度误差;
对工作台上通过夹具固定而不易移动物体的抓取影响较大,角度偏差会导致机械手在抓取物体过程中产生一个有害扭矩,导致抓取失败,也容易改变物体当前状态造成再装配困难;
位姿估计中还引入 MABR 算法。
- 对图像进行阈值分割;然后,进行腐蚀、膨胀、开运算和闭运算等操作对二值图像进
行去干扰处理;最后,利用最小面积外接矩形包围物体,输出矩形四个顶点坐标。 - 求出矩形任意相邻两条边的长度 a a a 和 b b b
- 对边长 a a a 和 b b b 值进行大小判断,确定矩形框的长 h h h 和宽 w w w
- 根据公式求出角度
α = a r c t a n ∣ y 3 − y 0 x 3 − x 0 ∣ × 180 ° π β = a r c t a n ∣ y 3 − y 0 x 3 − x 0 ∣ × 180 ° π + 90 ° \alpha = \mathbf{arctan}|\frac{y_{3}-y_{0}}{x_{3}-x_{0}}|\times\frac{180\degree}{\pi} \\ \beta = \mathbf{arctan}|\frac{y_{3}-y_{0}}{x_{3}-x_{0}}|\times\frac{180\degree}{\pi}+90\degree α=arctan∣x3−x0y3−y0∣×π180°β=arctan∣x3−x0y3−y0∣×π180°+90°
3 实验结果与分析
系统采用 linux 下基于 Visual Studio Code 编译软件进行开发,确保系统和编译环境的统一性,便于图像处理与机械臂运动控制间的数据传输。
3.1 目标检测
由于主干特征提取网络具有特征通用性,因此也采用冻结训练方法二次加快模型训练的速度。
| 解冻前 | 解冻后 | |
|---|---|---|
| 学习率 l r lr lr | 0.001 | 0.0001 |
| 批量大小 b a r t c h _ s i z e bartch\_size bartch_size | 8 | 4 |
| 初始迭代 I n i t _ e p o c h Init\_epoch Init_epoch | 0 | 50 |
| 冻结/解冻迭代 F r e e z e / U n f r e e z e e p o c h Freeze/Unfreeze_epoch Freeze/Unfreezeepoch | 50 | 100 |
- 相比于改进前,加入注意力机制模型的检测网络平均识别准确率 m A P mAP mAP由 92.33%增加到 92.65%,提升 0.32%。
- 在网络置信度不变的情况下,降低模型在杂乱环境下了漏检的可能,检测效果更加突出,证明了改进模型的实际意义。
3.2 抓取位姿估计
抓取位姿估计采用 cornell 数据集制作模型训练所需的数据样本
从对比结果能够得出,对于单个物体的抓取位姿估计,双层结构和更深层 ResNet-50 网络在估计准确率上并没有突出的表现,反而单层结构 VGG-16 的方法在运行时间上有明显的优势。
相比于改进前,改进后位姿估计的抓取角度连续化,更加趋于物体的偏转角度。
通过实验测量,计算出改进后的预测抓取角度与目标的实际偏转角度平均误差小于2.47°。
3.3 机械臂抓取实验
抓取对象通过胶水固定在亚克力板上,硅胶起传导作用力和避免较大扭矩损坏设备的作用。
抓取系统的坐标转换流程如下。文章来源:https://www.toymoban.com/news/detail-419954.html
- 相机首先获取图像的二维像素坐标,通过相机的深度信息和内参数据将图像像素坐标转换到基于相机坐标系下三维坐标;
- 利用手眼标定的关系矩阵,将相机坐标系下的坐标转换成机械臂基座坐标系下的三维坐标,最终实现了抓取目标到机械臂基座坐标系下的坐标转换。

 文章来源地址https://www.toymoban.com/news/detail-419954.html
文章来源地址https://www.toymoban.com/news/detail-419954.html
- 设置 UR5 机械臂抓取拍照等待位姿,坐标为 ( x 0 , y 0 , z 0 ) (x_{0}, y_{0}, z_{0}) (x0,y0,z0),两指机械手偏转角度为 0°;
- 相机获取目标图像,计算机处理数据,输出目标抓取点的坐标 ( x , y , z ) (x, y, z) (x,y,z)和偏转角度 θ θ θ 信息;
- 控制两指机械手偏转 θ 角度,机械臂由等待位 ( x 0 , y 0 , z 0 ) (x_{0}, y_{0}, z_{0}) (x0,y0,z0)移到抓取位 ( x , y , z ) (x, y, z) (x,y,z),准备抓取;
- 气动控制两指机械手闭合,完成物体抓取,然后机械臂根据目标检测结果进行相应分类
放置; - 完成放置操作后,机械臂回到初始拍照等待位置;
- 如果继续抓取,则返回步骤 1;否则,抓取任务结束。
4 结论
到了这里,关于【论文笔记】基于深度学习的视觉检测及抓取方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!