深度学习 Day 31——YOLOv5-Backbone模块实现
一、前言
在上一期博客中我们将利用YOLOv5算法中的C3模块搭建网络,了解学习一下C3的结构,并在最后我们尝试增加C3模块来进行训练模型,看看准确率是否增加了。本期博客我们将学习另一个模块(Backbone)的实现,我们将利用这个模块搭建网络进行上一期博客实现的天气识别,对比一下两个模块的准确率的差异,本期博客除了模型网络结构外,其他部分和上期博客内容一样,所有我们将着重学习该模块的实现。
二、我的环境
本期博客我们继续使用谷歌云平台Colab进行学习。
print("============查看GPU信息================")
# 查看GPU信息
!/opt/bin/nvidia-smi
print("==============查看pytorch版本==============")
# 查看pytorch版本
import torch
print(torch.__version__)
print("============查看虚拟机硬盘容量================")
# 查看虚拟机硬盘容量
!df -lh
print("============查看cpu配置================")
# 查看cpu配置
!cat /proc/cpuinfo | grep model\ name
print("=============查看内存容量===============")
# 查看内存容量
!cat /proc/meminfo | grep MemTotal
============查看GPU信息================
Thu Apr 20 09:12:02 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 43C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
==============查看pytorch版本==============
2.0.0+cu118
============查看虚拟机硬盘容量================
Filesystem Size Used Avail Use% Mounted on
overlay 79G 24G 55G 30% /
tmpfs 64M 0 64M 0% /dev
shm 5.7G 0 5.7G 0% /dev/shm
/dev/root 2.0G 1.1G 841M 58% /usr/sbin/docker-init
tmpfs 6.4G 56K 6.4G 1% /var/colab
/dev/sda1 77G 44G 34G 57% /opt/bin/.nvidia
tmpfs 6.4G 0 6.4G 0% /proc/acpi
tmpfs 6.4G 0 6.4G 0% /proc/scsi
tmpfs 6.4G 0 6.4G 0% /sys/firmware
drive 15G 0 15G 0% /content/drive
============查看cpu配置================
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
=============查看内存容量===============
MemTotal: 13297192 kB
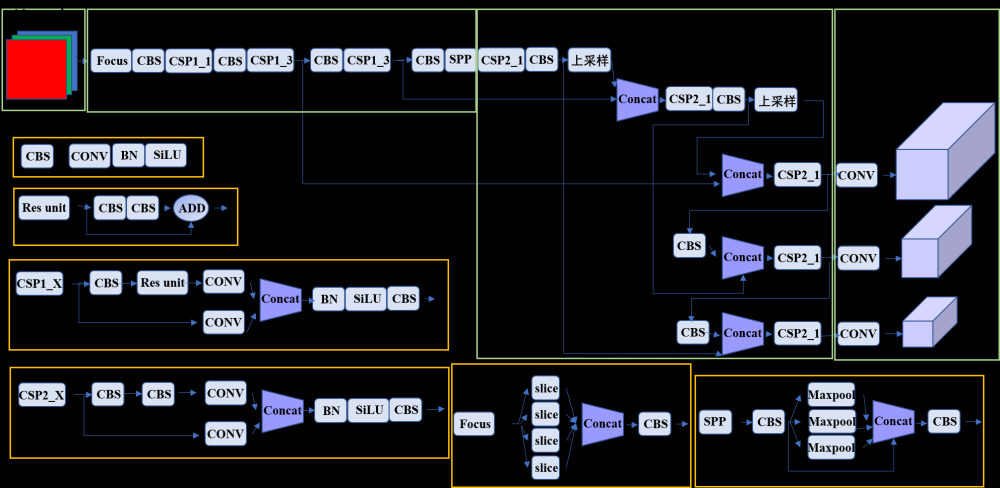
三、什么是YOLOv5-Backbone模块?
YOLOv5是一种目标检测算法,其核心是YOLOv5-Backbone模块。该模块是一个深度卷积神经网络(DCNN),用于从图像中提取特征并预测边界框。
YOLOv5-Backbone模块的基本实现方法包括以下步骤:
- 输入预处理:将原始图像转换为网络所需的输入格式,如将RGB图像转换为BGR格式,并将像素值缩放到0到1之间。
- 特征提取:使用卷积层和池化层等操作从图像中提取特征。YOLOv5-Backbone模块使用一系列残差块(Residual Block)来构建特征提取网络。这些残差块包括卷积层、批量归一化(Batch Normalization)层和激活函数(如LeakyReLU)。
- 特征金字塔:为了检测不同大小的目标,YOLOv5-Backbone模块使用特征金字塔来获取不同尺度的特征图。这个过程使用不同步长(stride)的卷积层来获取不同分辨率的特征图,并将它们级联在一起。
- 预测输出:将特征图送入卷积层和全连接层,生成目标检测的输出。这个过程使用锚点框(Anchor Boxes)来检测目标边界框。锚点框是一组预定义的边界框,用于检测不同大小的目标。YOLOv5-Backbone模块使用多个卷积层来输出目标的边界框、类别置信度和偏移量。
- 后处理:使用非极大值抑制(NMS)来去除重叠的边界框,并将最终的目标框输出。
从原理上来说,YOLOv5-Backbone模块是一个基于残差网络的深度卷积神经网络,用于从图像中提取特征并预测边界框。在实现方面,该模块使用一系列残差块来构建特征提取网络,使用不同步长的卷积层来获取不同尺度的特征图,并使用锚点框来检测目标边界框。最终使用非极大值抑制算法来去除重叠的边界框,并输出最终的目标框。
四、搭建包含Backbone模块的模型
1、模型整体代码
下面我们给出搭建包含Backbone模块的模型的整体代码,并在后面对模型的每一部分进行解释:
import torch.nn.functional as F
def autopad(k, p=None): # 内核,填充
# 填充到“相同”
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动填充
return p
class Conv(nn.Module):
# 标准瓶颈
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
# 标准瓶颈
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # 隐藏频道
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# 具有 3 个卷积的 CSP 瓶颈
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # 隐藏频道
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5): # 相当于 SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # 隐藏频道
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # 抑制torch1.9.0的max_pool2d()警告
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
class YOLOv5_backbone(nn.Module):
def __init__(self):
super(YOLOv5_backbone, self).__init__()
self.Conv_1 = Conv(3, 64, 3, 2, 2)
self.Conv_2 = Conv(64, 128, 3, 2)
self.C3_3 = C3(128,128)
self.Conv_4 = Conv(128, 256, 3, 2)
self.C3_5 = C3(256,256)
self.Conv_6 = Conv(256, 512, 3, 2)
self.C3_7 = C3(512,512)
self.Conv_8 = Conv(512, 1024, 3, 2)
self.C3_9 = C3(1024, 1024)
self.SPPF = SPPF(1024, 1024, 5)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=65536, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self, x):
x = self.Conv_1(x)
x = self.Conv_2(x)
x = self.C3_3(x)
x = self.Conv_4(x)
x = self.C3_5(x)
x = self.Conv_6(x)
x = self.C3_7(x)
x = self.Conv_8(x)
x = self.C3_9(x)
x = self.SPPF(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = YOLOv5_backbone().to(device)
model
Using cuda device
YOLOv5_backbone(
(Conv_1): Conv(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(Conv_2): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_3): C3(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_4): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_5): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_6): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_7): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_8): Conv(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_9): C3(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(SPPF): SPPF(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=65536, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)
2、模型每一部分详解
下面我们将详细对每一步进行解释:
-
autopad(k, p=None):一个自动填充函数,用于在卷积操作中自动填充边缘以保持输出和输入大小相同。# 定义自动填充函数,用于计算填充大小 def autopad(k, p=None): # 填充到“相同”,即保持输入和输出具有相同的空间维度 if p is None: # 如果 k 是一个整数,则在所有空间维度上使用相同的填充大小 if isinstance(k, int): p = k // 2 # 如果 k 是一个元组,则逐个计算每个空间维度上的填充大小 else: p = [x // 2 for x in k] return p -
Conv模块:包含卷积、BN(批量归一化)和激活函数,用于卷积操作和特征提取。该模块的参数包括输入通道数 c 1 c1 c1、输出通道数 c 2 c2 c2、卷积核大小 k k k、步长 s s s、填充 p p p、分组卷积数 g g g和是否使用激活函数 a c t act act。其中,卷积核大小 k k k可以是整数或元组,用于指定卷积核的宽度和高度。当 p p p为None时,自动进行填充使得输出大小等于输入大小。# 定义卷积层 class Conv(nn.Module): def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): super().__init__() # 创建一个二维卷积层,其中 c1 是输入通道数,c2 是输出通道数,k 是卷积核大小,s 是步幅,p 是填充大小,g 是分组数量,bias=False 表示不使用偏置 self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) # 创建一个二维批归一化层,用于加速训练 self.bn = nn.BatchNorm2d(c2) # 创建一个激活函数层,默认使用 SiLU(即 Mish 激活函数) self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity()) def forward(self, x): # 对输入进行卷积、批归一化、激活函数处理,并返回结果 return self.act(self.bn(self.conv(x))) -
Bottleneck模块:一个标准的瓶颈模块,包含两个卷积层和一个残差连接,用于构建多层卷积神经网络。该模块的参数包括输入通道数 c 1 c1 c1、输出通道数 c 2 c2 c2、是否使用残差连接 s h o r t c u t shortcut shortcut、分组卷积数 g g g和扩展系数 e e e。其中,扩展系数 e e e表示隐藏层通道数相对于输出层通道数的扩展倍数。# 定义标准瓶颈结构 class Bottleneck(nn.Module): def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): super().__init__() # 计算隐藏通道数 c_ = int(c2 * e) # 创建一个 1x1 卷积层,用于降维 self.cv1 = Conv(c1, c_, 1, 1) # 创建一个 3x3 卷积层,用于特征提取 self.cv2 = Conv(c_, c2, 3, 1, g=g) # 判断是否需要添加残差连接 self.add = shortcut and c1 == c2 def forward(self, x): # 如果需要添加残差连接,则将输入直接加到输出上 return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x)) -
C3模块:一个具有3个卷积的CSP(Cross Stage Partial)瓶颈模块,包含两个Bottleneck模块和一个残差连接,用于构建多层卷积神经网络。该模块的参数包括输入通道数 c 1 c1 c1、输出通道数 c 2 c2 c2、Bottleneck模块的个数 n n n、是否使用残差连接 s h o r t c u t shortcut shortcut、分组卷积数 g g g和扩展系数 e e e。# 定义具有 3 个卷积的 CSP 瓶颈结构 class C3(nn.Module): def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): super().__init__() # 计算隐藏通道数 c_ = int(c2 * e) # 创建一个 1x1 卷积层,用于降维 self.cv1 = Conv(c1, c_, 1, 1) # 创建一个 1x1 卷积层,用于辅助特征提取 self.cv2 = Conv(c1, c_, 1, 1) # 创建一个 1x1 卷积层,用于融合特征 self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2) # 创建 n 个标准瓶颈结构 self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n))) def forward(self, x): # 将输入经过 cv1 和 cv2 后与 m(cv1(x)) 进行拼接,并经过 cv3 处理后输出 return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1)) -
SPPF模块:一个空间金字塔池化模块,用于在不同尺度下对特征图进行池化,以提高模型的感受野和尺度不变性。该模块的参数包括输入通道数 c 1 c1 c1、输出通道数 c 2 c2 c2和池化核大小 k k k。# SPPF模块定义 class SPPF(nn.Module): def __init__(self, c1, c2, k=5): # 相当于 SPP(k=(5, 9, 13)) super().__init__() c_ = c1 // 2 # 隐藏频道 self.cv1 = Conv(c1, c_, 1, 1) # 1x1卷积,降低通道数 self.cv2 = Conv(c_ * 4, c2, 1, 1) # 1x1卷积,增加通道数 self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) # SPP池化层 def forward(self, x): x = self.cv1(x) # 1x1卷积 with warnings.catch_warnings(): warnings.simplefilter('ignore') # 抑制torch1.9.0的max_pool2d()警告 y1 = self.m(x) # SPP池化层 y2 = self.m(y1) # SPP池化层 # 拼接四个尺度的特征图 return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1)) -
YOLOv5_backbone模块:一个完整的YOLOv5主干网络,包含多个Conv、C3和SPPF模块,用于特征提取和分类。该模块还包含一个全连接网络层,用于分类。class YOLOv5_backbone(nn.Module): def __init__(self): super(YOLOv5_backbone, self).__init__() self.Conv_1 = Conv(3, 64, 3, 2, 2) # 3x3卷积,步长2,空洞率2 self.Conv_2 = Conv(64, 128, 3, 2) # 3x3卷积,步长2 self.C3_3 = C3(128,128) # CSP瓶颈,包含3个卷积层 self.Conv_4 = Conv(128, 256, 3, 2) # 3x3卷积,步长2 self.C3_5 = C3(256,256) # CSP瓶颈,包含3个卷积层 self.Conv_6 = Conv(256, 512, 3, 2) # 3x3卷积,步长2 self.C3_7 = C3(512,512) # CSP瓶颈,包含3个卷积层 self.Conv_8 = Conv(512, 1024, 3, 2) # 3x3卷积,步长2 self.C3_9 = C3(1024, 1024) # CSP瓶颈,包含3个卷积层 self.SPPF = SPPF(1024, 1024, 5) # SPPF模块 # 全连接网络层,用于分类 self.classifier = nn.Sequential( nn.Linear(in_features=65536, out_features=100), # 第一个全连接层,输入大小为65536,输出大小为100 nn.ReLU(), nn.Linear(in_features=100, out_features=4) # 第二个全连接层,输入大小为100,输出大小为4 ) def forward(self, x): x = self.Conv_1(x) x = self.Conv_2(x) x = self.C3_3(x) x = self.Conv_4(x) x = self.C3_5(x) x = self.Conv_6(x) x = self.C3_7(x) x = self.Conv_8(x) x = self.C3_9(x) x = self.SPPF(x) x = torch.flatten(x, start_dim=1) # 将特征图转换为一维向量,用于全连接层 x = self.classifier(x) # 过全连接层,输出分类结果 return x
3、模型详情
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 113, 113] 1,728
BatchNorm2d-2 [-1, 64, 113, 113] 128
SiLU-3 [-1, 64, 113, 113] 0
Conv-4 [-1, 64, 113, 113] 0
Conv2d-5 [-1, 128, 57, 57] 73,728
BatchNorm2d-6 [-1, 128, 57, 57] 256
SiLU-7 [-1, 128, 57, 57] 0
Conv-8 [-1, 128, 57, 57] 0
Conv2d-9 [-1, 64, 57, 57] 8,192
BatchNorm2d-10 [-1, 64, 57, 57] 128
SiLU-11 [-1, 64, 57, 57] 0
Conv-12 [-1, 64, 57, 57] 0
Conv2d-13 [-1, 64, 57, 57] 4,096
BatchNorm2d-14 [-1, 64, 57, 57] 128
SiLU-15 [-1, 64, 57, 57] 0
Conv-16 [-1, 64, 57, 57] 0
Conv2d-17 [-1, 64, 57, 57] 36,864
BatchNorm2d-18 [-1, 64, 57, 57] 128
SiLU-19 [-1, 64, 57, 57] 0
Conv-20 [-1, 64, 57, 57] 0
Bottleneck-21 [-1, 64, 57, 57] 0
Conv2d-22 [-1, 64, 57, 57] 8,192
BatchNorm2d-23 [-1, 64, 57, 57] 128
SiLU-24 [-1, 64, 57, 57] 0
Conv-25 [-1, 64, 57, 57] 0
Conv2d-26 [-1, 128, 57, 57] 16,384
BatchNorm2d-27 [-1, 128, 57, 57] 256
SiLU-28 [-1, 128, 57, 57] 0
Conv-29 [-1, 128, 57, 57] 0
C3-30 [-1, 128, 57, 57] 0
Conv2d-31 [-1, 256, 29, 29] 294,912
BatchNorm2d-32 [-1, 256, 29, 29] 512
SiLU-33 [-1, 256, 29, 29] 0
Conv-34 [-1, 256, 29, 29] 0
Conv2d-35 [-1, 128, 29, 29] 32,768
BatchNorm2d-36 [-1, 128, 29, 29] 256
SiLU-37 [-1, 128, 29, 29] 0
Conv-38 [-1, 128, 29, 29] 0
Conv2d-39 [-1, 128, 29, 29] 16,384
BatchNorm2d-40 [-1, 128, 29, 29] 256
SiLU-41 [-1, 128, 29, 29] 0
Conv-42 [-1, 128, 29, 29] 0
Conv2d-43 [-1, 128, 29, 29] 147,456
BatchNorm2d-44 [-1, 128, 29, 29] 256
SiLU-45 [-1, 128, 29, 29] 0
Conv-46 [-1, 128, 29, 29] 0
Bottleneck-47 [-1, 128, 29, 29] 0
Conv2d-48 [-1, 128, 29, 29] 32,768
BatchNorm2d-49 [-1, 128, 29, 29] 256
SiLU-50 [-1, 128, 29, 29] 0
Conv-51 [-1, 128, 29, 29] 0
Conv2d-52 [-1, 256, 29, 29] 65,536
BatchNorm2d-53 [-1, 256, 29, 29] 512
SiLU-54 [-1, 256, 29, 29] 0
Conv-55 [-1, 256, 29, 29] 0
C3-56 [-1, 256, 29, 29] 0
Conv2d-57 [-1, 512, 15, 15] 1,179,648
BatchNorm2d-58 [-1, 512, 15, 15] 1,024
SiLU-59 [-1, 512, 15, 15] 0
Conv-60 [-1, 512, 15, 15] 0
Conv2d-61 [-1, 256, 15, 15] 131,072
BatchNorm2d-62 [-1, 256, 15, 15] 512
SiLU-63 [-1, 256, 15, 15] 0
Conv-64 [-1, 256, 15, 15] 0
Conv2d-65 [-1, 256, 15, 15] 65,536
BatchNorm2d-66 [-1, 256, 15, 15] 512
SiLU-67 [-1, 256, 15, 15] 0
Conv-68 [-1, 256, 15, 15] 0
Conv2d-69 [-1, 256, 15, 15] 589,824
BatchNorm2d-70 [-1, 256, 15, 15] 512
SiLU-71 [-1, 256, 15, 15] 0
Conv-72 [-1, 256, 15, 15] 0
Bottleneck-73 [-1, 256, 15, 15] 0
Conv2d-74 [-1, 256, 15, 15] 131,072
BatchNorm2d-75 [-1, 256, 15, 15] 512
SiLU-76 [-1, 256, 15, 15] 0
Conv-77 [-1, 256, 15, 15] 0
Conv2d-78 [-1, 512, 15, 15] 262,144
BatchNorm2d-79 [-1, 512, 15, 15] 1,024
SiLU-80 [-1, 512, 15, 15] 0
Conv-81 [-1, 512, 15, 15] 0
C3-82 [-1, 512, 15, 15] 0
Conv2d-83 [-1, 1024, 8, 8] 4,718,592
BatchNorm2d-84 [-1, 1024, 8, 8] 2,048
SiLU-85 [-1, 1024, 8, 8] 0
Conv-86 [-1, 1024, 8, 8] 0
Conv2d-87 [-1, 512, 8, 8] 524,288
BatchNorm2d-88 [-1, 512, 8, 8] 1,024
SiLU-89 [-1, 512, 8, 8] 0
Conv-90 [-1, 512, 8, 8] 0
Conv2d-91 [-1, 512, 8, 8] 262,144
BatchNorm2d-92 [-1, 512, 8, 8] 1,024
SiLU-93 [-1, 512, 8, 8] 0
Conv-94 [-1, 512, 8, 8] 0
Conv2d-95 [-1, 512, 8, 8] 2,359,296
BatchNorm2d-96 [-1, 512, 8, 8] 1,024
SiLU-97 [-1, 512, 8, 8] 0
Conv-98 [-1, 512, 8, 8] 0
Bottleneck-99 [-1, 512, 8, 8] 0
Conv2d-100 [-1, 512, 8, 8] 524,288
BatchNorm2d-101 [-1, 512, 8, 8] 1,024
SiLU-102 [-1, 512, 8, 8] 0
Conv-103 [-1, 512, 8, 8] 0
Conv2d-104 [-1, 1024, 8, 8] 1,048,576
BatchNorm2d-105 [-1, 1024, 8, 8] 2,048
SiLU-106 [-1, 1024, 8, 8] 0
Conv-107 [-1, 1024, 8, 8] 0
C3-108 [-1, 1024, 8, 8] 0
Conv2d-109 [-1, 512, 8, 8] 524,288
BatchNorm2d-110 [-1, 512, 8, 8] 1,024
SiLU-111 [-1, 512, 8, 8] 0
Conv-112 [-1, 512, 8, 8] 0
MaxPool2d-113 [-1, 512, 8, 8] 0
MaxPool2d-114 [-1, 512, 8, 8] 0
MaxPool2d-115 [-1, 512, 8, 8] 0
Conv2d-116 [-1, 1024, 8, 8] 2,097,152
BatchNorm2d-117 [-1, 1024, 8, 8] 2,048
SiLU-118 [-1, 1024, 8, 8] 0
Conv-119 [-1, 1024, 8, 8] 0
SPPF-120 [-1, 1024, 8, 8] 0
Linear-121 [-1, 100] 6,553,700
ReLU-122 [-1, 100] 0
Linear-123 [-1, 4] 404
================================================================
Total params: 21,729,592
Trainable params: 21,729,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 137.59
Params size (MB): 82.89
Estimated Total Size (MB): 221.06
----------------------------------------------------------------
五、模型训练
import copy
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 60
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
模型训练的结果是:文章来源:https://www.toymoban.com/news/detail-420056.html
Epoch: 1, Train_acc:54.9%, Train_loss:1.150, Test_acc:66.2%, Test_loss:0.636, Lr:1.00E-04
Epoch: 2, Train_acc:66.3%, Train_loss:0.777, Test_acc:76.9%, Test_loss:0.603, Lr:1.00E-04
Epoch: 3, Train_acc:69.7%, Train_loss:0.696, Test_acc:82.2%, Test_loss:0.622, Lr:1.00E-04
Epoch: 4, Train_acc:78.1%, Train_loss:0.589, Test_acc:80.9%, Test_loss:0.507, Lr:1.00E-04
Epoch: 5, Train_acc:81.3%, Train_loss:0.498, Test_acc:80.9%, Test_loss:0.537, Lr:1.00E-04
Epoch: 6, Train_acc:83.6%, Train_loss:0.436, Test_acc:78.7%, Test_loss:0.494, Lr:1.00E-04
Epoch: 7, Train_acc:86.1%, Train_loss:0.370, Test_acc:87.6%, Test_loss:0.380, Lr:1.00E-04
Epoch: 8, Train_acc:86.7%, Train_loss:0.348, Test_acc:77.3%, Test_loss:0.559, Lr:1.00E-04
Epoch: 9, Train_acc:89.0%, Train_loss:0.345, Test_acc:81.3%, Test_loss:0.513, Lr:1.00E-04
Epoch:10, Train_acc:90.4%, Train_loss:0.258, Test_acc:84.9%, Test_loss:0.403, Lr:1.00E-04
Epoch:11, Train_acc:89.4%, Train_loss:0.270, Test_acc:83.6%, Test_loss:0.489, Lr:1.00E-04
Epoch:12, Train_acc:89.7%, Train_loss:0.276, Test_acc:86.2%, Test_loss:0.414, Lr:1.00E-04
Epoch:13, Train_acc:90.8%, Train_loss:0.247, Test_acc:84.9%, Test_loss:0.499, Lr:1.00E-04
Epoch:14, Train_acc:90.0%, Train_loss:0.273, Test_acc:84.9%, Test_loss:0.498, Lr:1.00E-04
Epoch:15, Train_acc:93.9%, Train_loss:0.179, Test_acc:85.8%, Test_loss:0.418, Lr:1.00E-04
Epoch:16, Train_acc:94.0%, Train_loss:0.165, Test_acc:82.7%, Test_loss:0.692, Lr:1.00E-04
Epoch:17, Train_acc:93.1%, Train_loss:0.193, Test_acc:86.2%, Test_loss:0.504, Lr:1.00E-04
Epoch:18, Train_acc:92.6%, Train_loss:0.220, Test_acc:85.8%, Test_loss:0.550, Lr:1.00E-04
Epoch:19, Train_acc:95.1%, Train_loss:0.126, Test_acc:87.6%, Test_loss:0.479, Lr:1.00E-04
Epoch:20, Train_acc:96.4%, Train_loss:0.114, Test_acc:80.9%, Test_loss:0.719, Lr:1.00E-04
Epoch:21, Train_acc:97.7%, Train_loss:0.074, Test_acc:88.9%, Test_loss:0.405, Lr:1.00E-04
Epoch:22, Train_acc:96.6%, Train_loss:0.103, Test_acc:88.0%, Test_loss:0.428, Lr:1.00E-04
Epoch:23, Train_acc:96.3%, Train_loss:0.090, Test_acc:85.3%, Test_loss:0.540, Lr:1.00E-04
Epoch:24, Train_acc:95.9%, Train_loss:0.109, Test_acc:87.6%, Test_loss:0.437, Lr:1.00E-04
Epoch:25, Train_acc:96.9%, Train_loss:0.085, Test_acc:89.3%, Test_loss:0.333, Lr:1.00E-04
Epoch:26, Train_acc:97.7%, Train_loss:0.065, Test_acc:87.6%, Test_loss:0.393, Lr:1.00E-04
Epoch:27, Train_acc:97.3%, Train_loss:0.094, Test_acc:85.3%, Test_loss:0.542, Lr:1.00E-04
Epoch:28, Train_acc:96.7%, Train_loss:0.087, Test_acc:85.3%, Test_loss:0.652, Lr:1.00E-04
Epoch:29, Train_acc:95.8%, Train_loss:0.097, Test_acc:80.4%, Test_loss:0.838, Lr:1.00E-04
Epoch:30, Train_acc:97.4%, Train_loss:0.071, Test_acc:87.1%, Test_loss:0.540, Lr:1.00E-04
Epoch:31, Train_acc:97.3%, Train_loss:0.071, Test_acc:88.9%, Test_loss:0.797, Lr:1.00E-04
Epoch:32, Train_acc:96.9%, Train_loss:0.108, Test_acc:86.2%, Test_loss:0.500, Lr:1.00E-04
Epoch:33, Train_acc:98.0%, Train_loss:0.058, Test_acc:88.0%, Test_loss:0.536, Lr:1.00E-04
Epoch:34, Train_acc:99.7%, Train_loss:0.018, Test_acc:89.8%, Test_loss:0.479, Lr:1.00E-04
Epoch:35, Train_acc:99.7%, Train_loss:0.008, Test_acc:87.6%, Test_loss:0.605, Lr:1.00E-04
Epoch:36, Train_acc:98.8%, Train_loss:0.040, Test_acc:89.3%, Test_loss:0.527, Lr:1.00E-04
Epoch:37, Train_acc:98.3%, Train_loss:0.042, Test_acc:83.6%, Test_loss:0.709, Lr:1.00E-04
Epoch:38, Train_acc:97.1%, Train_loss:0.083, Test_acc:84.0%, Test_loss:0.719, Lr:1.00E-04
Epoch:39, Train_acc:95.4%, Train_loss:0.133, Test_acc:87.1%, Test_loss:0.617, Lr:1.00E-04
Epoch:40, Train_acc:98.2%, Train_loss:0.051, Test_acc:86.7%, Test_loss:0.565, Lr:1.00E-04
Epoch:41, Train_acc:98.2%, Train_loss:0.060, Test_acc:85.3%, Test_loss:0.776, Lr:1.00E-04
Epoch:42, Train_acc:98.9%, Train_loss:0.040, Test_acc:88.0%, Test_loss:0.596, Lr:1.00E-04
Epoch:43, Train_acc:100.0%, Train_loss:0.006, Test_acc:89.8%, Test_loss:0.654, Lr:1.00E-04
Epoch:44, Train_acc:99.0%, Train_loss:0.029, Test_acc:90.7%, Test_loss:0.405, Lr:1.00E-04
Epoch:45, Train_acc:99.3%, Train_loss:0.016, Test_acc:89.3%, Test_loss:0.540, Lr:1.00E-04
Epoch:46, Train_acc:98.6%, Train_loss:0.033, Test_acc:87.6%, Test_loss:0.635, Lr:1.00E-04
Epoch:47, Train_acc:99.0%, Train_loss:0.034, Test_acc:83.6%, Test_loss:1.015, Lr:1.00E-04
Epoch:48, Train_acc:96.0%, Train_loss:0.160, Test_acc:87.1%, Test_loss:0.538, Lr:1.00E-04
Epoch:49, Train_acc:97.7%, Train_loss:0.074, Test_acc:87.6%, Test_loss:0.644, Lr:1.00E-04
Epoch:50, Train_acc:98.3%, Train_loss:0.053, Test_acc:87.6%, Test_loss:0.566, Lr:1.00E-04
Epoch:51, Train_acc:99.2%, Train_loss:0.032, Test_acc:87.6%, Test_loss:0.600, Lr:1.00E-04
Epoch:52, Train_acc:99.2%, Train_loss:0.023, Test_acc:88.0%, Test_loss:0.675, Lr:1.00E-04
Epoch:53, Train_acc:99.8%, Train_loss:0.007, Test_acc:89.3%, Test_loss:0.620, Lr:1.00E-04
Epoch:54, Train_acc:99.6%, Train_loss:0.009, Test_acc:90.7%, Test_loss:0.658, Lr:1.00E-04
Epoch:55, Train_acc:99.7%, Train_loss:0.008, Test_acc:88.9%, Test_loss:0.750, Lr:1.00E-04
Epoch:56, Train_acc:99.7%, Train_loss:0.007, Test_acc:88.9%, Test_loss:0.758, Lr:1.00E-04
Epoch:57, Train_acc:99.9%, Train_loss:0.003, Test_acc:88.9%, Test_loss:0.777, Lr:1.00E-04
Epoch:58, Train_acc:97.0%, Train_loss:0.155, Test_acc:87.6%, Test_loss:0.862, Lr:1.00E-04
Epoch:59, Train_acc:96.1%, Train_loss:0.115, Test_acc:88.0%, Test_loss:0.597, Lr:1.00E-04
Epoch:60, Train_acc:98.4%, Train_loss:0.046, Test_acc:87.6%, Test_loss:0.859, Lr:1.00E-04
Done
六、最终结果
1、Loss-Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
 文章来源地址https://www.toymoban.com/news/detail-420056.html
文章来源地址https://www.toymoban.com/news/detail-420056.html
2、模型准确率
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print('Test_acc:{:.1f}%, Test_loss:{:.3f}'.format(epoch_test_acc*100, epoch_test_loss))
Test_acc:90.7%, Test_loss:0.459
到了这里,关于深度学习 Day 31——YOLOv5-Backbone模块实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!