C语言
实验环境:Visual Studio 2019
author:zoxiii
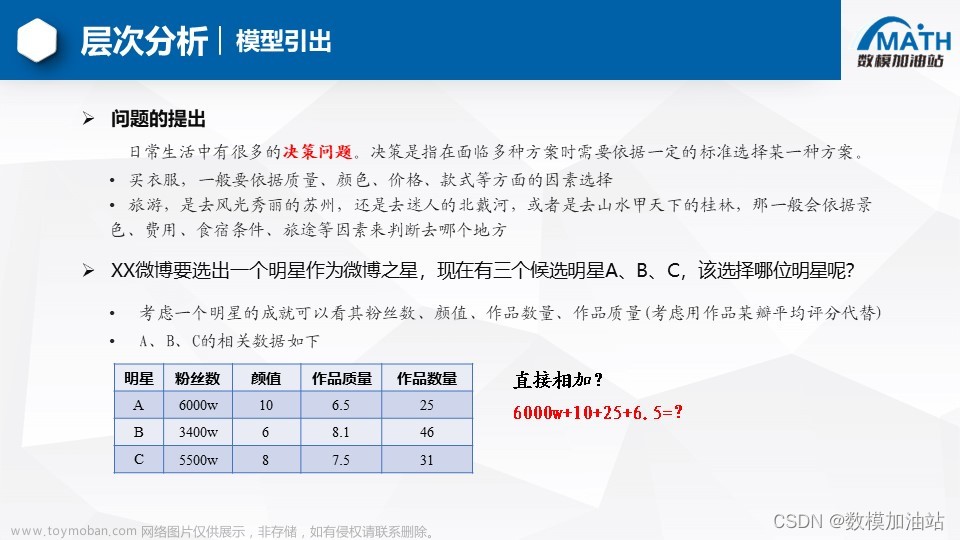
1、实验内容
用高级语言实现递归下降分析程序。使用输入串i*(i+i),输出分析栈中所有内容,并给出分析结果。
2、前期准备
2.1 递归下降分析法原理
自顶向下分析就是从文法的开始符触发并寻找出这样一个推导序列:推导出的句子恰好为输入符号串;或者说,能否从根节点出发向下生长出一颗语法树,其叶节点组成的句子恰好为输入符号串。显然,语法树的每一步生长(每一步推导)都以能否与输入符号串匹配为准,如果最终句子得到识别,则证明输入符号串为该文发的一个句子;否则,输入符号串不是该文法的句子。
递归下降分析法是一种自顶向下的分析方法,文法的每个非终结符对应一个递归过程(函数)。分析过程就是从文法开始符触发执行一组递归过程(函数),这样向下推到直到推出句子;或者说从根节点出发,自顶向下为输入串寻找一个最左匹配序列,建立一颗语法树。
2.2 要实现的文法
已知要实现的文法如下,可以观察到该文法G[E]中包含直接左递归:
G[E]: E->E+T|T
T->T*F|F
F->(E)|i
为了实现确定的自顶向下分析,要求文法满足下述两个条件:
(1) 文法不含左递归,即不存在这样的非终结符A:有A->A……存在;
(2) 无回溯,对文法的任一非终结符号,当其产生式右部有多个候选式可供选择时,各候选式所推出的终结符号串的首字符集合要两两不相交。
因为文法如果包含左递归和回溯在文法分析的时候就可能会做大量无用的工作,导致分析效率降低。
所以首先需要对该文法消除左递归和回溯,得到如下文法G’[E]:
G’[E]: E->TE’
E’->TE’|ε
T->FT’
T’->*FT’|ε
F->(E)|i
另外为了方便编写代码,所以将文法表示符替换成便于书写的单个大写字母,得到新的G[E]文法如下:
G[E]: E->TG
G->+TG|ε
T->FS
S->*FS|ε
F->(E)|i
2.3 需要的函数
在不含左递归和回溯的条件下,我们就能够构造一个不带回溯的自顶向下的分析程序,这个分析程序是由一组递归过程组成的,每个过程对应文法的一个非终结符。这样的一个分析程序称为递归下降分析器。分析书上给出的伪代码首先可以确定的函数有以下几个:
(1)void E(); //E–>TG
(2)void G(); //G–>+TG|ε
(3)void T(); //T–>FS
(4)void S(); //S–>*FS|ε
(5)void F(); //F–>(E)|i
(6)void err(); //提示错误信息
然后对于实验要求对于分析过程中的分析栈进行输出,所以我们使用一个字符串类型的变量stackStr来模拟分析栈,并添加vector类型的链表记录每一步的分析结果,以供输出。在此基础上就需要添加压栈等相关函数如下:
(1)int check();//验证是否已经到栈底
(2)void push(string pre, string value);//将字符串存入输出栈
3、分析过程
3.1 递归下降分析法设计思想及算法
为文法G[E]的每个非终结符号E构造一个递归过程,不妨命名为E。E的产生式的右部指出这个过程的代码结构,在匹配时:
(1)若是终结符a,则继续对照,若匹配则输入串向前进一个符号;否则出错。
(2)若是非终结符号A,则调用与此非终结符对应的过程。当A的右部有多个产生式时,可用选择结构实现。
具体为:
1)对于每个非终结符号 E->A|B|,|Z 处理的方法如下:
E( )
{
ch=s[i];
if(ch 可能是 A 的首字符 ) 处理 A 的程序部分 ;
else if(ch 可能是 B 的首字符 ) 处理 B 的程序部分 ;
,
else error()
}
2)对于每个右部 A->x1x2,xn的处理架构如下:
处理 x1 的程序;
,
处理 xn 的程序;
3)如果右部为空,则不处理。
4)对于右部中的每个符号 xi
① 如果 xi 为终结符号:
if(xi == 当前的符号 )
{
NextChar() ; //NextChar 为前进一个字符函数
return;
}
else 出错处理2;
② 如果 xi 为非终结符号,直接调用相应的过程 xi()
3.2 分析栈的分析过程
我们将对符合要实现的文法的、正确的输入串“i*(i+i)#”进行分析,其中,“#”为输入串的分隔符。进行语法分析时,首先将“#”和文法开始符E压入栈中,当语法分析到栈中仅剩“#”而扫描输入串指针已经指向输入串尾部的“#”时,则语法分析成功。
首先我们按照已给的文法和输入串画出该语法树如下图所示:


3.3 流程图

对于文法的每一个表达式都要编写对应的函数来匹配字符,下面为其中一个过程的流程图。

另外,压栈函数在每一次匹配字符的过程中都需要压栈,其中使用到了一些C++自带的函数:
(1) substr(a,b):a:起始位置、b:字符串长度;
(2) str.find_first_of(ch):从str开始查找ch的位置;
(3) erase(idx, n):删除从位置idx开始的n个字符;
(4) v.push_back():将字符串压入向量v中;

3.4 源代码
#include <iostream>
#include <iomanip>
#include <string>
#include <vector>
using namespace std;
//变量定义
string s, str, stackStr;//s:输入串、str:中间变量、stackStr : 模拟栈
int i;
string ch;//当前分析字符
vector<string> v;//字符串类型的向量(文法+分析栈)
//函数声明
void E(); //E-->TG
void G(); //G-->+TG|ε
void T(); //T-->FS
void S(); //S-->*FS|ε
void F(); //F-->(E)|i
void err(); //提示错误信息
int check();//验证是否已经到栈底
void push(string pre, string value);//将字符串存入输出栈
/**
* 函数功能:提示错误信息
*/
void err()
{
cout << "ERROR" << endl;
exit(0);
}
/**
* 函数功能:将字符串存入输出栈
*/
void push(string pre, string value)
{
ch += s[i];
int idx = stackStr.find_first_of(pre[0], 0);//从头开始找到pre开始的位置
if (value != "ε")//不是空字时
{
string value1;
value1 = value;
if (value[0] == '+')value1 = "TG";
if (value[0] == '*')value1 = "FS";
if (value[0] == '(')value1 = "E";
if (value[0] == 'i')value1 = "";
stackStr.replace(idx, 1, value1);//将第一个pre的位置替换为value
}
else
{
stackStr.erase(idx, 1);//删除从该位置开始的1个字符
}
v.push_back((pre + value + "," + stackStr));//将对应的表达式和栈的内容存加入在向量v尾部
}
/**
* 函数功能:验证是否已经到栈底
*/
int check()
{
if (i >= s.size()) {
return 1;
}
else if (s[i] == '#')
{
ch += '#';
return 1;
}
return 0;
}
/**
* 函数功能:E-->TG
*/
void E()
{
push("E-->", "TG");
T();
G();
}
/**
* 函数功能:G-->+TG|ε
*/
void G() {
if (s[i] == '+')
{
str = s[i];
str += "TG";
i++;
push("G-->", str);
T();
G();
}
else
{
push("G-->", "ε");
}
}
/**
* 函数功能:T-->FS
*/
void T()
{
push("T-->", "FS");
F();
S();
}
/**
* 函数功能:S-->*FS|ε
*/
void S() {
if (s[i] == '*')
{
str = s[i];
str += "FS";
i++;
push("S-->", str);
F();
S();
}
else
{
push("S-->", "ε");
}
}
/**
* 函数功能:F-->(E)|i
*/
void F() {
if (s[i] == '(')
{
i++;
push("F-->", "(E)");
E();
if (s[i] == ')')
{
i++;
}
else
{
err();
}
}
else if (s[i] == 'i')
{
i++;
push("F-->", "i");
}
else
{
err();
}
}
/**
* 函数功能:主函数
*/
int main() {
cout << "===================================================" << endl;
cout << "=== 递归下降分析 ===" << endl;
cout << "===================================================" << endl;
cout << "===请输入字符串 (以#号结束)===" << endl;
while (cin >> s) //输入要分析的字符串
{
v.clear();
i = 0;
stackStr = "E#";//初始化栈
E();
if (check())
{
cout << "=====>\t\t 输入串分析正确! " << endl;
cout << "推导过程如下: " << endl;
cout << "文法\t\t分析栈\t\t当前分析字符\n";
cout << "E \t\tE#\t\t" << s[0] << endl;//初始栈的内容
int i;
for (i = 0; i < v.size(); i++)
{
cout << v[i].substr(0, v[i].find_first_of(",", 0)) << "\t";
cout << setiosflags(ios::right) << setw(10) << v[i].substr(v[i].find_first_of(",", 0) + 1) << "\t\t";
cout << ch[i] << endl;
}
}
else
cout << "==>\t 输入串不符合该文法 " << endl;
}
return 0;
}
3.5 运行结果
下图为递归下降分析法的推导过程、输出内容为:
(1) 文法表达式;
(2) 分析栈;
(3) 当前分析字符;


4、遇到问题
对于文法的最后一个表达式中的F->(E)在判断“)”时出错,检查发现原因是因为前面识别到“(”时已经对输入串的索引值加1了,所以直接比较就可以,但在编写时由进行了一次加1操作,导致出错。文章来源:https://www.toymoban.com/news/detail-420349.html
参考文献:《编译原理教程 (第4版)》 胡元义 2016文章来源地址https://www.toymoban.com/news/detail-420349.html
到了这里,关于【编译原理】【C语言】实验三:递归下降分析法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!