摘要
kafka的存储消息,生产者发送消息,消费者消费消息。这些看起来简单,但实际细想,会有很多问题需要解决:消息是单个单个发送还是批量发送?broker的主题里一有消息就立即推送给消费者吗?生产者的消息怎么保证成功发送到kafka,kafka怎么保证消息传给了消费者?
生产者
生产者组件以及发送流程如下图所示:

1、创建生产者,生产者创建代码如下:
Properties producerConfig = new Properties();
producerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");
producerConfig.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
producerConfig.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer<>(producerConfig);基本只要指定 broker的地址、key和value序列化类就可以创建。这里建议序列化类就使用String序列化类,即消息就是字符串存在kafka里,无论哪种语言哪种框架,字符串是认得的,也不存在新旧消息兼容问题。
当然,生产者参数还有很多,具体可以看ProducerConfig,主要参数还有有:acks、buffer.memory、compression.type、retries、batch.size、linger.ms、client.id、max.in.flight.request.per.connection、timeout.ms、request.timeout.ms、metadata.fetch.timeout.ms、max.block.ms、max.request.size、receive.buffer.bytes、send.buffer.bytes。
2、发送消息,发送消息方式有:发送并忘记、同步发送、异步发送。
发送并忘记:调用send()方法,无需管返回值,具体代码如下:
producer.send(new ProducerRecord<>("topic", "key","value"));同步发送:调用send()方法,该方法其实会返回Future对象,并再调用Future对象的get()方法,发送成功后get()方法会返回消息元数据对象RecordMetadata,该对象可以查看偏移量offset等数据。注意,若acks=0,则offset只会返回-1,无法获取broker返回的真实偏移量。具体如下:
try {
RecordMetadata result = (RecordMetadata)producer.send(new ProducerRecord<>("topic", "key","value")).get();
System.out.println(result.partition()+":"+result.offset());
}catch (Exception e){
e.printStackTrace();
}异步发送:先定义一个Callback的实现类,实现onCompletion方法,调用send()方法时传入这个Callback即可。具体如下:
public class ProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception != null){
System.out.println("消息发送异常:"+ exception.getMessage());
}else{
System.out.println("消息发送成功["+metadata.partition()+":"+metadata.offset()+"]");
}
}
}
producer.send(new ProducerRecord("topic","key","value"),new ProducerCallback());由于是异步发送,会出现主线程不会等待onCompletion运行就已经结束。
3、发送过程:结合流程图和API具体步骤如下:
(1)、生产者先将消息序列化,序列化类可用key.serializer和value.serializer参数指定。另外,序列化之前,可以调用拦截器对消息进行处理,interceptor.classes参数可以指定拦截器。
(2)、将消息分区,若ProducerRecord没有指定分区,则默认按key来分区,同key的消息分到同一分区。若key为空,则轮询分配分区。
(3)、将同topic和同partition的消息记录到同一批次中,该批次消息达到触发条件(大小达到缓存区限制或请求大小限制等)或有空余线程,则该批次消息会被发送到broker。
(4)、broker收到消息并写入到相应的topic、partition以及offest上后会将结果响应给客户端。
(5)、若broker写入消息失败,则返回错误,或生产者断网发送失败,生产者会重试,直到retries参数指定的次数完成。
4、消息发送成功的关键:确保发送成功的关键就是生产者acks参数和retries参数。acks=0,无法保证消息发送成功,因为生产者不会确认broker的响应。acks=1,生产者只会确认broker里leader节点的响应。只有acks=all,生产者才会确认leader节点写入以及follwer节点同步都成功的响应。当失败时,消息可以通过retries进行数次重试以及通过retry.backoff.ms参数设置重试间隔时间。
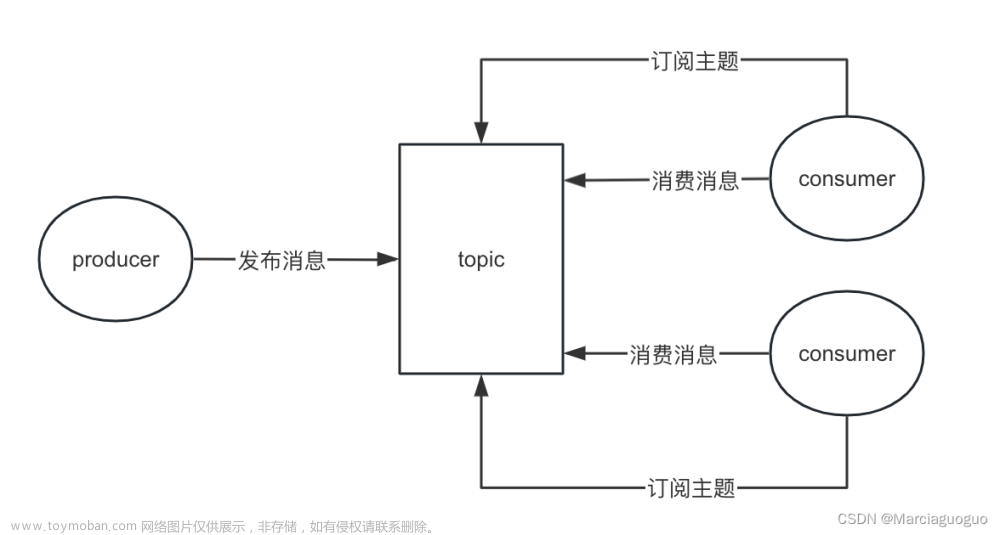
消费者
消费者主要是消费分区里的消息,具体如下图所示:

可以看到同消费组的消费者会分别消费分区下的消息。注意,若消费者数量大于分区数,则会有空闲消费者,一个分区的消息只能被一个消费者消费,不能被多个消费者消费。
1、创建消费者,创建代码如下:
Properties consumerConfig = new Properties();
// consumerConfig.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");
consumerConfig.put("bootstrap.servers", "192.168.189.128:9092,92.168.189.128:9093,192.168.189.128:9094");
consumerConfig.put("group.id","boot-kafka");
consumerConfig.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
consumerConfig.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> kafkaConsumer = new KafkaConsumer(consumerConfig);2、订阅主题,具体代码如下:
kafkaConsumer.subscribe(Arrays.asList("device-alarm-test"));当然,这个订阅可以订阅多个主题,也可以订阅正则匹配的主题。
3、轮询获取消息,具体代码如下:
while (true){
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(10000));
for(ConsumerRecord<String, String> record:records){
System.out.println(record.value());
}
}其中poll方法的超时时间是指消费者等待返回消息的时间,无论有没有获取到消息,等待该时间后都会返回。该方法会隐藏 群组协调、分区再平衡、发送心跳、获取数据的所有细节,
4、消费过程:首先要搞清楚fetch和poll,当调用poll时,会先从缓存区取数据,缓存区没数据则发请求获取broker的消息。关键源码如下:

具体消费步骤如下:
(1) 消费者通过poll()方法请求数据,该方法首先会去缓存区(一个ConcurrentLinkedQueue)获取数据,若缓存区有数据则最多返回max.poll.size条消息。
(2) 若缓存区无数据,则会调用client.send()方法发送请求broker获取数据。
(3) 若broker收到消费者请求,会根据fetch.min.bytes(获取记录最小字节数)以及fetch.max.wait.ms(获取记录最大等待时间)这两个值参考,比如两个值分别是1M和500ms,则broker需要等消息积压到1M或等待500ms才会聚合分区的消息返回给消费者。这两个参数在消费者里设置,send()时会带上这两个参数。
(4) broker聚合分区消息时,为了平衡分区数据,每个分区最多返回max.parttion.fetch.bytes数据给broker。这个参数是在消费者里设置,默认是1M,这个值必须大于broker的max.message.size,否则会出现broker能存大消息,但分区无法发送消息的情况。另外,fetch.max.bytes默认是max.parttion.fetch.bytes的50倍,即每个topic最多配置50个分区。
(5) 消费者获取到broker返回的消息后,会保存到缓存区中,然后再调用一次fetcher.collectFetch()方法从缓存区获取消息返回。
(6) 若enable.auto.commit=true,则会自动提交偏移量,默认每auto.commit.interval.ms(默认5秒)时间提交一次偏移量。当然,可以手动提交,需要自己在poll()获取记录消费后调用同步或异步提交api更新offset。文章来源:https://www.toymoban.com/news/detail-420377.html
5、消费消息成功的关键:提交偏移量,消费者获取到消息消费后及时更新偏移量才是保证消费准确的关键,没及时更新偏移量,会导致重复消费,但更新错误偏移量,比如偏移量更新大了,会导致漏消费。所以偏移量的更新是消费准确的关键。当然,我们可以也设置UUID来标识消息,用UUID来给消息去重。文章来源地址https://www.toymoban.com/news/detail-420377.html
到了这里,关于kafka:消息发送以及消费的过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!