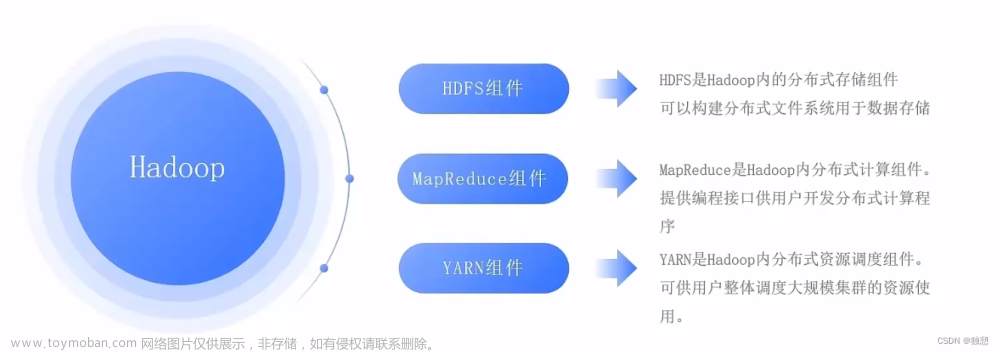
文章目录
一、环境要求
二、在Ubuntu中安装Eclipse
三、在Eclipse创建项目
四、为项目添加需要用到的JAR包
五、编写Java应用程序代码
总结
前言
Hadoop不同的文件系统之间通过调用Java API进行交互,利用Java API进行交互,需要利用软件Eclipse编写Java程序。
一、环境要求
- 已经配置好网络的Ubuntu系统的虚拟机
- Ubuntu 16.04 64位
- hadoop-3.1.3.tar,可在官网下载或者点击下载(提取码:0412)
- jdk-8u162-linux-x64.tar
二、在Ubuntu中安装Eclipse
利用Ubuntu左侧边栏自带的软件中心安装软件,在Ubuntu左侧边栏打开软件中心

打开软件中心后,在软件中心搜索栏输入“ec”,软件中心会自动搜索相关的软件,点击如下图中Eclipse,进行安装

安装需要管理员权限,Ubuntu系统需要用户认证,弹出“认证”窗口,请输入当前用户的登录密码

等待安装,安装结束后安装进度条便会消失。
安装好后侧边栏就会出现eclipse图标。点击打开eclipse。

三、在Eclipse创建项目
第一次打开Eclipse,需要填写workspace(工作空间),用来保存程序所在的位置,这里按照默认,不需要改动,如下图

点击“OK”按钮,进入Eclipse软件。
可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
Eclipse启动以后,会呈现下图的界面

选择“File->New->Java Project”菜单,开始创建一个Java工程,会弹出下图界面。在“Project name”后面输入工程名称“HDFSExample”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/HDFSExample”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如java-8-openjdk-amd64。然后,点击界面底部的“Next>”按钮,进入下一步的设置。

四、为项目添加需要用到的JAR包
进入下一步的设置以后,会出现如图界面

需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,会弹出下图界面。

在该界面中,上面的一排目录按钮(即“usr”、“local”、“hadoop”、“share”、“hadoop”、“mapreduce”和“lib”),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)"/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar;
(2)/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.7.1.jar和haoop-hdfs-nfs-2.7.1.jar;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
比如,如果要把“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar添加到当前的Java工程中,可以在界面中点击目录按钮,进入到common目录,然后,界面会显示出common目录下的所有内容。

请在界面中用鼠标点击选中hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar,然后点击界面右下角的“确定”按钮,就可以把这两个JAR包增加到当前Java工程中,出现的界面如图示。

从这个界面中可以看出,hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar已经被添加到当前Java工程中。然后,按照类似的操作方法,可以再次点击“Add External JARs…”按钮,把剩余的其他JAR包都添加进来。需要注意的是,当需要选中某个目录下的所有JAR包时,可以使用“Ctrl+A”组合键进行全选操作。全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程HDFSExample的创建。

五、编写Java应用程序代码
下面编写一个Java应用程序,用来检测HDFS中是否存在一个文件。
在Eclipse工作界面左侧的“Package Explorer”面板中,找到刚才创建好的工程名称“HDFSExample”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New->Class”菜单。

在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“HDFSFileIfExist”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮。

可以看出,Eclipse自动创建了一个名为“HDFSFileIfExist.java”的源代码文件,请在该文件中输入以下代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSFileIfExist {
public static void main(String[] args){
try{
String fileName = "test";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName))){
System.out.println("文件存在");
}else{
System.out.println("文件不存在");
}
}catch (Exception e){
e.printStackTrace();
}
}
}该程序用来测试HDFS中是否存在一个文件,其中有一行代码:
String fileName = "test"这行代码给出了需要被检测的文件名称是“test”,没有给出路径全称,表示是采用了相对路径,实际上就是测试当前登录Linux系统的用户hadoop,在HDFS中对应的用户目录下是否存在test文件,也就是测试HDFS中的“/user/hadoop/”目录下是否存在test文件。
编译运行:
在开始编译运行程序之前,请一定确保Hadoop已经启动运行,如果还没有启动,需要打开一个Linux终端,输入以下命令启动Hadoop:
cd /usr/local/hadoop
./sbin/start-dfs.shRun As Java Application运行程序
由于目前HDFS的“/user/hadoop”目录下还没有test文件,因此,程序运行结果是“文件不存在”。同时,“Console”面板中还会显示一些类似“log4j:WARN…”的警告信息,可以不用理会。
 文章来源:https://www.toymoban.com/news/detail-420776.html
文章来源:https://www.toymoban.com/news/detail-420776.html
总结
本文参考林子雨老师Hadoop课程以及大数据技术原理与应用 第三章 分布式文件系统HDFS 学习指南,完成了自己的HDFS练习。文章来源地址https://www.toymoban.com/news/detail-420776.html
到了这里,关于分布式文件系统HDFS之利用Java API与HDFS进行交互的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!