一个文件若小于128mb,并不会占用128mb
在从节点的 /data/hadoop_repo/dfs/data/current/BP-300951849-192.168.70.128-1637467565154/current/finalized/subdir0/subdir0:
$hadoop.tmp.dir$
blk_... 的文件就是一个个block文件 _后面的数字就是block id
关于副本: 有多少个从节点,就可以有多少个副本,一般默认3个 在availability中可以体现文章来源:https://www.toymoban.com/news/detail-420816.html
节点上存储的文件信息(block块存放在哪个节点)只有datanode自己知道,
故每次启动的时候,datanode都有扫描一遍节点,将存储的文件信息(当前节点上所有block块信息)传送给namenode(这个关系每次重启都会动态加载)
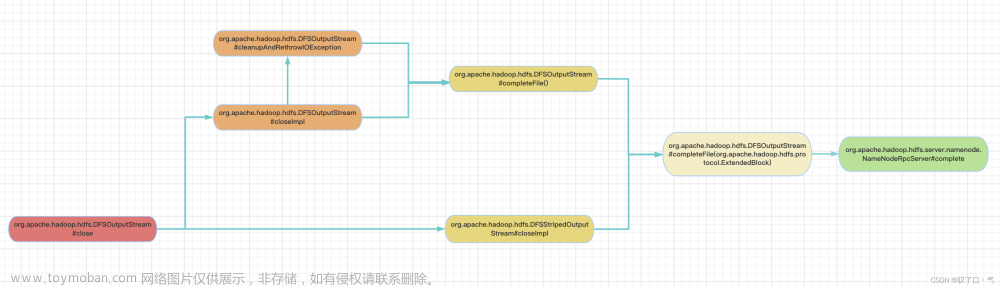
fsimage 中保存了 文件和block块 之间的映射信息
namenode节点中维护着两类信息:
1 block 与文件的信息(fsimage,edits)namenode启动时会将元数据信息(每个文件占用150字节)加载到内存
2 block块与 datanode对应的关系 datanode启动时会上报当前节点 与block之间映射关系 给namenode文章来源地址https://www.toymoban.com/news/detail-420816.html
到了这里,关于hdfs-datanode的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!