目录
1.前言
2.什么是canal
3.canal能做什么
4.如何搭建canal
4.1首先有一个MySQL服务器
4.2 准备canal
1.下载
2.解压
3.修改配置文件
4.启动canal
5.Java创建客户端,监听canalServer(官网推荐方式)
1.创建SpringBoot项目
略过…
2.导入canal客户端包
3.导入测试Main方法
6.Java创建客户端,GitHub推荐三方工具
1.创建SpringBoot项目
2.导入依赖
3.导入Bean代码
4.启动项目
7.canal-adapter同步数据
7.1.安装adapter客户端
7.2 解压到纯英文 路径,中文会报错
7.3配置application.yml
7.4mysql-》mysql需要修改 rdb配置文件
7.5全量同步
7.6多表同步
8.报错解决
8.1 canal服务端
8.1.1:找不到表
8.2 adapter客户端
8.2.1: dir not exist (找不到目录)
8.2.2: Did not matched any columns to update(没有任何一列可以更新)
8.2.3: 全量更新执行ETL命令报错 Task not fund 解决方案见 (canal数据同步7.5(全量同步)
1.前言
我们都知道一个系统最重要的是数据,数据是保存在数据库里。但是很多时候不单止要保存在数据库中,还要同步保存到Elastic Search、HBase、Redis等等。
这时我注意到阿里开源的框架Canal,他可以很方便地同步数据库的增量数据到其他的存储应用。所以在这里总结一下,分享给各位读者参考~
2.什么是canal
我们先看官网的介绍:
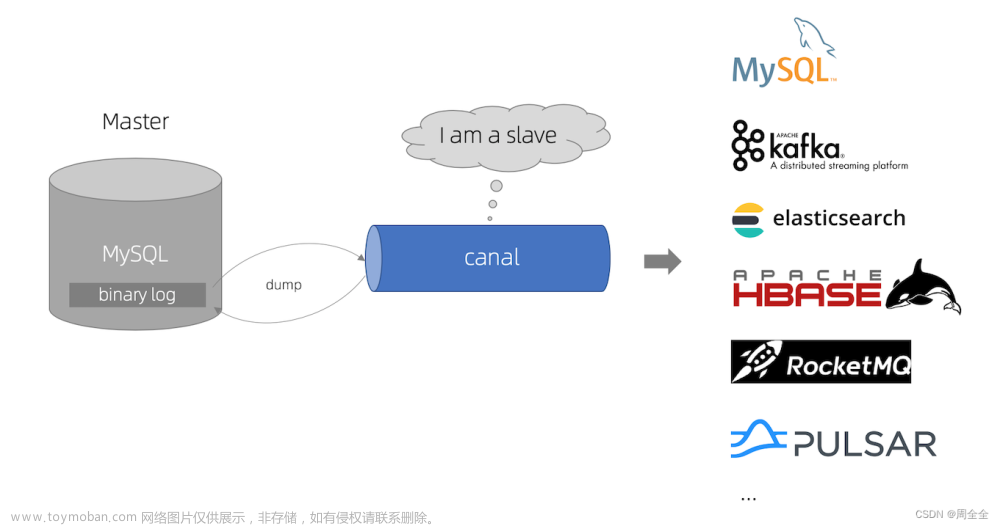
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
这句介绍有几个关键字:增量日志,增量数据订阅和消费。
这里我们可以简单地把canal理解为一个用来同步增量数据的一个工具。
canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
3.canal能做什么
与其问canal能做什么,不如说数据同步有什么作用。
但是canal的数据同步不是全量的,而是增量。基于binary log增量订阅和消费,canal可以做:
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护
- 业务cache(缓存)刷新
- 带业务逻辑的增量数据处理
4.如何搭建canal
4.1首先有一个MySQL服务器
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
我的Linux服务器安装的MySQL服务器是5.7版本。
MySQL的安装这里就不演示了,比较简单,网上也有很多教程。
然后在MySQL中需要创建一个用户,并授权:
-- 使用命令登录:mysql -u root -p -- 创建用户 用户名:canal 密码:Canal@123456 create user 'canal'@'%' identified by 'Canal@123456'; -- 授权 *.*表示所有库 grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%' identified by 'Canal@123456';
下一步在MySQL配置文件my.cnf设置如下信息:
[mysqld] # 打开binlog log-bin=mysql-bin # 选择ROW(行)模式 binlog-format=ROW # 配置MySQL replaction需要定义,不要和canal的slaveId重复 server_id=1
4.2 准备canal
1.下载
 去官网下载页面进行下载:https://github.com/alibaba/canal/releases
去官网下载页面进行下载:https://github.com/alibaba/canal/releases
2.解压

3.修改配置文件

需要配置以下参数:
| #canal读取mysql的binlog文件是把自己伪装成一个slava ,所以需要配置一个id,这个id不能和mysql配置的id相同 canal.instance.mysql.slaveId=9 #要监听的mysql的地址 canal.instance.master.address=127.0.0.1:3306 #mysql 数据解析关注的表,Perl正则表达式. #多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\) #常见例子: #1. 所有表:.* or .*\\..* #2. canal schema下所有表:canal\\..* #3. canal下的以canal打头的表:canal\\.canal.* #4. canal schema下的一张表:canal.test1 #5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔) #默认监听的数据库的名称,也可以不配置这个 canal.instance.defaultDatabaseName=test #黑名单 canal.instance.filter.black.regex=mysql\\.slave_.* #白名单 canal.instance.filter.regex=.*\\..* |
4.启动canal

- 查看配置,是否有报错

5.Java创建客户端,监听canalServer(官网推荐方式)
1.创建SpringBoot项目
略过…
2.导入canal客户端包
| <dependency> |
3.导入测试Main方法
| import com.alibaba.otter.canal.client.CanalConnector; import com.alibaba.otter.canal.client.CanalConnectors; import com.alibaba.otter.canal.common.utils.AddressUtils; import com.alibaba.otter.canal.protocol.CanalEntry.Column; import com.alibaba.otter.canal.protocol.CanalEntry.Entry; import com.alibaba.otter.canal.protocol.CanalEntry.EntryType; import com.alibaba.otter.canal.protocol.CanalEntry.EventType; import com.alibaba.otter.canal.protocol.CanalEntry.RowChange; import com.alibaba.otter.canal.protocol.CanalEntry.RowData; import com.alibaba.otter.canal.protocol.Message; import java.net.InetSocketAddress; import java.util.List; public class ClientSample { public static void main(String args[]) { // 创建链接 CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(), 11111), "example", "", ""); int batchSize = 1000; int emptyCount = 0; try { connector.connect(); connector.subscribe(".*\\..*"); connector.rollback(); int totalEmtryCount = 1200; while (emptyCount < totalEmtryCount) { Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据 long batchId = message.getId(); int size = message.getEntries().size(); if (batchId == -1 || size == 0) { emptyCount++; System.out.println("empty count : " + emptyCount); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } else { emptyCount = 0; // System.out.printf("message[batchId=%s,size=%s] \n", batchId, size); printEntry(message.getEntries()); } connector.ack(batchId); // 提交确认 // connector.rollback(batchId); // 处理失败, 回滚数据 } System.out.println("empty too many times, exit"); } finally { connector.disconnect(); } } private static void printEntry( List<Entry> entrys) { for (Entry entry : entrys) { if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) { continue; } RowChange rowChage = null; try { rowChage = RowChange.parseFrom(entry.getStoreValue()); } catch (Exception e) { throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e); } EventType eventType = rowChage.getEventType(); System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType)); for (RowData rowData : rowChage.getRowDatasList()) { if (eventType == EventType.DELETE) { printColumn(rowData.getBeforeColumnsList()); } else if (eventType == EventType.INSERT) { printColumn(rowData.getAfterColumnsList()); } else { System.out.println("-------> before"); printColumn(rowData.getBeforeColumnsList()); System.out.println("-------> after"); printColumn(rowData.getAfterColumnsList()); } } } } private static void printColumn( List<Column> columns) { for (Column column : columns) { System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated()); } } } |
6.Java创建客户端,GitHub推荐三方工具
1.创建SpringBoot项目
省略..
2.导入依赖
| <!--第三方 GitHub 开源工具 --> |
3.导入Bean代码
| import com.brs.canalclient.domain.School; |
4.启动项目
省略..
7.canal-adapter同步数据
详细配置教学:https://blog.csdn.net/zcl111/article/details/119868846
7.1.安装adapter客户端
https://github.com/alibaba/canal/releases
|
|

7.2 解压到纯英文 路径,中文会报错
7.3配置application.yml
|
|

-
-
-
- 修改标记的4个地方:
-
-
| #↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ adapter适配器基础配置 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ server: port: 8081 # spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 default-property-inclusion: non_null
#↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ canal服务端地址 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ canal.conf: # kafka rocketMQ mode: tcp canalServerHost: 127.0.0.1:11111 # 2.canalService 地址 # zookeeperHosts: slave1:2181 # mqServers: 127.0.0.1:9092 #or rocketmq # flatMessage: true batchSize: 500 syncBatchSize: 1000 retries: 0 timeout: accessKey: secretKey: #↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ canal监控的数据源 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ srcDataSources: source1: # 3.监控地址 url: jdbc:mysql://localhost:3306/test?useUnicode=true username: root password: 123456yts
#↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ 数据去处时适配器配置。可以配置多个,并发执行。每个适配器都有个对应的instance。 ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
canalAdapters: # 同步数据的目标数据源配置 - instance: example # canal instance Name or mq topic name #canalServer的实例名称,或者mq交换机类型 groups: # 消费组其一的ID - groupId: g1 # 消费者 group_01 下的多个数据去处 适配器。 outerAdapters: # 组内的适配器是串行处理。如果其中一个异常,会导致下面的的适配器不能执行。 - name: rdb # 适配器类型。即目前支持的通过SPI加载的适配器。从 plugin文件夹中读取的。 key: adapterTestKey1 # 适配器key。具体适配器yml中配置 outerAdapterKey引用。 properties: # 4.目标地址 jdbc.driverClassName: com.mysql.jdbc.Driver jdbc.url: jdbc:mysql://localhost:3307/test?useUnicode=true jdbc.username: root jdbc.password: 123456yts
|
7.4mysql-》mysql需要修改 rdb配置文件
|
|

| dataSourceKey: source1 ##canal adapter配置的数据源 destination: example #canal实例名称,对应application.yml中的instance groupId: g1 #对应哪个outerAdapter的消费组 outerAdapterKey: adapterTestKey1 #application.yml 中配置的Key concurrent: true #是否并行同步 dbMapping: #上下游数据映射 #mirrorDb: true #同步数据库DDL语句create-drop-alert,同步DDL必须配置这个 database: test #上游数据库名称 table: school #上游数据库中的表名称 targetTable: test.school #下游目标数据库+表名称 用 . 号连接 targetPk: #目标主键 primaryKey 映射 id: id #ID映射 #mapAll: true # 是否整表映射, 要求源表和目标表字段名一模一样 (如果targetColumns也配置了映射,则以targetColumns配置为准) # 注意 这段表述“以targetColumns配置为准”。这个并不是说只同步 targetColumns配置的属性。而是说一样要同步 源表的所有属性。 # 但是考虑到目标表的属性名称可能不完全一致,有区别的属性名称可以通过targetColumns来配置映射关系,没有配置的默认属性默认都是相同。 # 如果只需要同步部分源表的属性到目标表中,这里应该设置false targetColumns: #2. 这也是映射,如果和上面 mapAll 同时开启,targetColumns优先级更高 # 字段映射, 格式: 目标表字段: 源表字段, 如果字段名一样源表字段名可不填 # 注意数据源的 to: from 前面是数据要同步到的地方,后面是数据来源的 id: school_name: name etlCondition: "where c_time>={}" commitBatch: 3000 # 批量提交的大小 |
7.5全量同步
1.上面讲解的都是增量同步的方式
增量同步其实很简单,只用发送一条etl 请求就可以了
http://127.0.0.1:8081/etl/rdb/adapterTestKey1/mytest_user.yml
|
|

标记①:这里是动态配置的,如果CanalAdapter的配置文件中
| 配置了①标记出的key在etl的连接中就要加上这个eky |

图1标记②:这个是同步的类型,我们现在执行的是mysql->mysql 所以是rdb
7.6多表同步
1.思路:
每一张表的同步在canal-adapter里面多需要一个适配器
2.配置适配器
在application.yml 中配置
|
|

3.使用适配器
适配器的使用,就是指定从哪里同步到哪里了
|
|

修改复制的hobby_user.yml内容
|
|

4.配置好了直接重启 adapter服务
如果要全量同步,就通过每张表配置适配器时候指定的outerAdapterKey 来同步
8.报错解决
8.1 canal服务端
8.1.1:找不到表
| Caused by: java.io.IOException: ErrorPacket [errorNumber=1146, fieldCount=-1, message=Table 'xzw.BASE TABLE' doesn't exist, sqlState=42S02, sqlStateMarker=#] with command: show create table `xzw`.`t_1`;show create table `xzw`.`BASE TABLE`; at com.alibaba.otter.canal.parse.driver.mysql.MysqlQueryExecutor.queryMulti(MysqlQueryExecutor.java:109) ~[canal.parse.driver-1.1.6.jar:na] at com.alibaba.otter.canal.parse.inbound.mysql.MysqlConnection.queryMulti(MysqlConnection.java:111) ~[canal.parse-1.1.6.jar:na] at com.alibaba.otter.canal.parse.inbound.mysql.tsdb.DatabaseTableMeta.dumpTableMeta(DatabaseTableMeta.java:233) ~[canal.parse-1.1.6.jar:na] at com.alibaba.otter.canal.parse.inbound.mysql.tsdb.DatabaseTableMeta.rollback(DatabaseTableMeta.java:174) ~[canal.parse-1.1.6.jar:na] at com.alibaba.otter.canal.parse.inbound.mysql.AbstractMysqlEventParser.processTableMeta(AbstractMysqlEventParser.java:142) ~[canal.parse-1.1.6.jar:na] at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$1.run(AbstractEventParser.java:197) ~[canal.parse-1.1.6.jar:na] at java.lang.Thread.run(Thread.java:750) [na:1.8.0_331] |
配置 canal.instance.filter.black.regex=.*\\.BASE.* 解决
文档:https://github.com/alibaba/canal/issues/4219
8.2 adapter客户端
8.2.1: dir not exist (找不到目录)
1.解决方案:adapter目录不能存放在有中文路径的文件里文章来源:https://www.toymoban.com/news/detail-421151.html
8.2.2: Did not matched any columns to update(没有任何一列可以更新)
1.解决方案:数据库字段名特殊符号_ 下划线识别不了文章来源地址https://www.toymoban.com/news/detail-421151.html
8.2.3: 全量更新执行ETL命令报错 Task not fund 解决方案见 (canal数据同步7.5(全量同步)
到了这里,关于Alibaba Canal数据同步 mysql->mysql的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!