一、Quartz
1. Quartz 概述
Quartz 是一个开源的作业调度框架(job scheduler),几乎可以集成到任何 Java 应用程序中,从最小的独立应用程序到最大的电子商务系统。Quartz 可用于创建简单或复杂的调度来执行数十个、数百个甚至数万个作业;其任务被定义为标准 Java 组件的作业,这些组件几乎可以执行您编写的任何程序。Quartz Scheduler 包含许多企业级功能,例如对 JTA 事务和集群的支持。
总结:Quartz 它是一个开源的作业调度框架,用来做定时任务的,使用的时候只需设置好触发时间规则cron,以及相应的任务Job即可。
Quartz官网地址:http://www.quartz-scheduler.org/
Quartz文档地址:https://www.quartz-scheduler.org/documentation/quartz-2.2.2/index.html

maven依赖坐标:
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz-jobs</artifactId>
<version>2.2.1</version>
</dependency>
整合springboot的启动依赖:
<!-- quartz -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
2. SpringBoot整合Quartz
cron在线生成器:https://qqe2.com/dev/cron
1、创建一个springboot工程

2、引入quartz启动依赖
<dependencies>
<!-- quartz任务调度 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
</dependencies>
3、创建一个Job类(任务类)
package com.baidou.job;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.quartz.QuartzJobBean;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.Date;
/**
* 任务类 Job
*
* @author 白豆五
* @version 2023/04/18
* @since JDK8
*/
@Configuration
@Component
@EnableScheduling
public class HelloJob extends QuartzJobBean {
/**
* 执行定时任务的逻辑
*
* @param jobExecutionContext
* @throws JobExecutionException
*/
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// 编写具体的定时任务逻辑
System.out.println("hello job exec~ "+ LocalDateTime.now());
}
}
4、创建一个配置类,定义任务和触发器
package com.baidou.config;
import com.baidou.job.HelloJob;
import org.quartz.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 定时任务配置类
*
* @author 白豆五
* @version 2023/04/18
* @since JDK8
*/
@Configuration
public class QuartzConfig {
// 工作任务
@Bean
public JobDetail jobDetail() {
// 指定任务描述具体的实现类
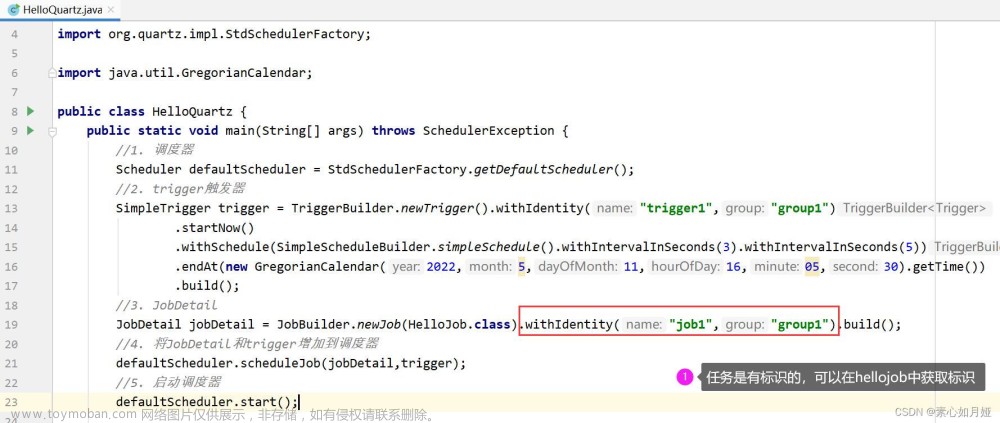
return JobBuilder.newJob(HelloJob.class)
// 指定任务的名称
.withIdentity("HelloJob")
// 任务描述
.withDescription("任务描述:测试输出一句话")
// 每次任务执行后进行存储
.storeDurably()
.build();
}
// 触发器
@Bean
public Trigger trigger() {
//创建触发器
return TriggerBuilder.newTrigger()
// 绑定上述的工作任务
.forJob(jobDetail())
// 每隔 5 秒执行一次 job
// .withSchedule(CronScheduleBuilder.cronSchedule("0/5 * * * * ?"))
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))
.build();
}
}
5、启动服务测试
从日志可以看到Quartz默认采用的是 RAMJobStore,就是将相关的任务信息保存在内存里,当应用重启后,定时任务信息就会丢失,那么我们能不能将这些信息持久化到数据库或硬盘中呢?
3. 切换数据库方式存储任务信息
1、导入数据库相关依赖
<dependencies>
<!-- quartz任务调度 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<!--mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
</dependencies>
2、执行jar包提供的sql脚本

#
# In your Quartz properties file, you'll need to set
# org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#
#
# By: Ron Cordell - roncordell
# I didn't see this anywhere, so I thought I'd post it here. This is the script from Quartz to create the tables in a MySQL database, modified to use INNODB instead of MYISAM.
CREATE DATABASE quartz_demo DEFAULT CHARSET utf8;
USE quartz_demo;
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
CREATE TABLE QRTZ_JOB_DETAILS(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(190) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_SIMPLE_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_CRON_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
CRON_EXPRESSION VARCHAR(120) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_SIMPROP_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
STR_PROP_1 VARCHAR(512) NULL,
STR_PROP_2 VARCHAR(512) NULL,
STR_PROP_3 VARCHAR(512) NULL,
INT_PROP_1 INT NULL,
INT_PROP_2 INT NULL,
LONG_PROP_1 BIGINT NULL,
LONG_PROP_2 BIGINT NULL,
DEC_PROP_1 NUMERIC(13,4) NULL,
DEC_PROP_2 NUMERIC(13,4) NULL,
BOOL_PROP_1 VARCHAR(1) NULL,
BOOL_PROP_2 VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_BLOB_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
INDEX (SCHED_NAME,TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_CALENDARS (
SCHED_NAME VARCHAR(120) NOT NULL,
CALENDAR_NAME VARCHAR(190) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME))
ENGINE=InnoDB;
CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
CREATE TABLE QRTZ_FIRED_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
INSTANCE_NAME VARCHAR(190) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(190) NULL,
JOB_GROUP VARCHAR(190) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID))
ENGINE=InnoDB;
CREATE TABLE QRTZ_SCHEDULER_STATE (
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(190) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME))
ENGINE=InnoDB;
CREATE TABLE QRTZ_LOCKS (
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (SCHED_NAME,LOCK_NAME))
ENGINE=InnoDB;
CREATE INDEX IDX_QRTZ_J_REQ_RECOVERY ON QRTZ_JOB_DETAILS(SCHED_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_J_GRP ON QRTZ_JOB_DETAILS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_J ON QRTZ_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_JG ON QRTZ_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_C ON QRTZ_TRIGGERS(SCHED_NAME,CALENDAR_NAME);
CREATE INDEX IDX_QRTZ_T_G ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_T_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_G_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NEXT_FIRE_TIME ON QRTZ_TRIGGERS(SCHED_NAME,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE_GRP ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_FT_TRIG_INST_NAME ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME);
CREATE INDEX IDX_QRTZ_FT_INST_JOB_REQ_RCVRY ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_FT_J_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_JG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_T_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_FT_TG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
commit;

3、在yml中配置quartz参数
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/quartz_demo?autoReconnect=true&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
# qyartz任务配置
quartz:
# 将quartz持久化方式修改为jdbc(默认是内存存储)
job-store-type: jdbc
#相关属性配置
properties:
org:
quartz:
scheduler:
# 实例名称
instanceName: clusteredScheduler
# 实例节点ID自动生成
instanceId: AUTO
jobStore:
#存储方式使用JobStoreTX,也就是数据库
class: org.quartz.impl.jdbcjobstore.JobStoreTX
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_ # 表的前缀
isClustered: false # true开启集群配置
clusterCheckinInterval: 2000 # 设置集群检测间隔为20s
useProperties: false
threadPool:
class: org.quartz.simpl.SimpleThreadPool
threadCount: 10
threadPriority: 5
threadsInheritContextClassLoaderOfInitializingThread: true
4、重启应用测试

ok,quartz已经成功切换数据库持久化方式了,此时数据库表中也有对应任务信息插入了。

二、SpringTask
SpringTask:是Spring3.0以后自带的定时任务工具,可以把它看成一个轻量级的Quartz,使用起来也非常简单,它不需要额外导包,只需导入spring包即可。
SpringTask快速入门:
1、创建springboot工程,在启动类上开启定时任务

package com.baidou;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
@EnableScheduling //开启定时任务
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
2、创建定时任务类
package com.baidou.job;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
/**
* 定时任务类 (基于SpringTask)
*
* @author 白豆五
* @version 2023/04/18
* @since JDK8
*/
@Slf4j
@Component
public class ScheduleTask {
// 每隔5秒执行一次job
@Scheduled(cron = "0/5 * * * * ?") // 指定cron表达式规则
public void createStatisticsByDay() {
// 写具体的定时任务逻辑
log.warn("************************定时任务执行了...");
}
/*
// cron设置执行规则(也叫七域表达式)
// 测试代码
@Scheduled(cron = "0/5 * * * * ? ") // 每隔5秒钟执行一次
public void createStatisticsByDay() {
log.warn("************************定时任务执行了...");
}*/
}
3、启动测试

三、XXL-JOB

XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。(美团大神徐雪里创作)

官网地址:www.xuxueli.com
项目地址:https://gitee.com/xuxueli0323/xxl-job
笔记:https://my.oschina.net/uwith/blog/3055522
同类产品有:
- TBSchedule:淘宝推出,多年未更新,文档缺失严重,缺少维护;
- Elastic-job:当当网借鉴TBSchedule并基于quartz.二次开发的弹性分布式任务调度系统;
- Saturn:唯品会开源的一个分布式任务调度平台,基于Elastic-job;
1. xxl-job-admin环境搭建
1、克隆代码
git clone git@gitee.com:xuxueli0323/xxl-job.git
2、执行sql脚本(xxl-job源码提供)

CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;

3、修改xxl-job-admin/application.properties数据库配置、邮箱账号密码

### web
server.port=8080
server.servlet.context-path=/xxl-job-admin
### actuator
management.server.servlet.context-path=/actuator
management.health.mail.enabled=false
### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.resources.static-locations=classpath:/static/
### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.##########
### mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
spring.datasource.hikari.validation-timeout=1000
### xxl-job, email
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=xxx@qq.com
spring.mail.from=xxx@qq.com
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en")
xxl.job.i18n=zh_CN
## xxl-job, triggerpool max size
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### xxl-job, log retention days
xxl.job.logretentiondays=30
4、修改logback.xml文件

<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="true" scanPeriod="1 seconds">
<contextName>logback</contextName>
<property name="log.path" value="./data/logs/xxl-job/xxl-job-admin.log"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}.%d{yyyy-MM-dd}.zip</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n
</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="file"/>
</root>
</configuration>
5、启动xxl-job-admin项目,测试访问:http://localhost:8080/xxl-admin-job

用户名和密码:admin 123456

ok,到这里xxl-job管理后台环境就配置成功了。
2. SpringBoot整合XXL-Job
1、创建springboot工程(2.4.5版本)
2、导入xxl-job和web依赖坐标:
<dependencies>
<!--xxl调度器使用-->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
<!--springmvc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
3、创建一个logback.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="true" scanPeriod="1 seconds">
<contextName>logback</contextName>
<property name="log.path" value="./data/logs/xxl-job/app.log"/>
<!--控制台输出-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!--文件输出-->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}.%d{yyyy-MM-dd}.zip</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n
</pattern>
</encoder>
</appender>
<!--日志级别-->
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="file"/>
</root>
</configuration>
4、配置application.properties
# 项目端口
server.port=8081
#log config
logging.config=classpath:logback.xml
###调度中心部署地址,多个配置之间逗号分隔 "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
###执行器token,非空时启用 xxl-job, access token
xxl.job.accessToken=default_token #令牌要与xxl-admin保持一致
###执行器app名称, 要和控制台那边配置一样的名称,不然注册不上去
xxl.job.executor.appname=xxljob-demo
###[选填]执行器注册:优先使用该配置作为注册地址,为空时使用内嵌服务”IP:PORT”作为注册地址。
##从而更灵活的支持容器类型执行器动态IP和动态端口映射问题。
xxl.job.executor.address=
###[选填]执行器ip:默认为空表示自动获取IP(即springboot容器的ip和端口,可以自动获取,也可以指定),多网卡时可手动配置指定ip,该ip不会绑定host仅作为通讯使用
xxl.job.executor.ip=
###[选填]执行器端口号:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
###执行器日志文件存储路径,需要对该路径拥有读写权限;为空则使用默认路径
xxl.job.executor.logpath=./data/logs/xxl-job/executor
###执行器日志保存天数
xxl.job.executor.logretentiondays=30
5、创建一个配置类,读取xxl-job相关配置,并注册xxljob执行器的bean
package com.baidou.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* XXL-JOB配置类
* @author 白豆五
* @version 2023/04/19
* @since JDK8
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
// 读取配置文件内容
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
// 注册XXLJOB执行器Bean
// @Bean(initMethod = "start",destroyMethod = "destroy") // 旧版的写法
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
// 封装数据
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
6、编写job类
package com.baidou.job;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import groovy.util.logging.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
/**
* XxlJob任务类(Bean模式)
*
* 开发步骤:
* 1、在Spring Bean实例中,开发Job方法,方式格式要求为 "public ReturnT<String> execute(String param)"
* 2、为Job方法添加注解 "@XxlJob(value="自定义JobHandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。
* 3、执行日志:需要通过 "XxlJobLogger.log" 打印执行日志;
*
* @author 白豆五
* @version 2023/04/19
* @since JDK8
*/
@Component
@Slf4j
public class MyJobHandler {
private static Logger logger = LoggerFactory.getLogger(MyJobHandler.class);
/**
* 定义job方法
* @param param
* @return
*/
@XxlJob(value = "demoJobHandler" ,init = "init",destroy = "destroy")
public ReturnT<String> execute(String param){
logger.info("MyJobHandler execute 任务触发成功:"+ LocalDateTime.now());
return ReturnT.SUCCESS; //200
}
// 初始方法
public void init(){
logger.info("init 方法调用成功");
}
// 销毁方法
public void destroy(){
logger.info("destroy 方法调用成功");
}
}
7、启动服务

8、进入到xxl-job-admin平台进行配置:http://localhost:8080/xxl-admin-job
8.1、添加一个执行器:


执行器添加成功后会在页面显示:

8.2、添加一个任务管理器

执行器:选择刚才新创建的执行器
任务描述:根据业务填写
路由策略:用默认的,详细说明参考:https://blog.csdn.net/qq_21046665/article/details/124695064
调度类型:CRON
cron: 设置执行规则,每5秒执行一次
运行模式:bean模式
JobHandler:就是job方法上,@XxlJob注解的value属性值

任务添加成功后会在页面显示:

9、重启demo服务后,面板上就会显示具体执行器的机器地址,就表示注册成功了

10、开启刚才创建的定时任务

11、查看调用日志和控制台日志

 文章来源:https://www.toymoban.com/news/detail-421374.html
文章来源:https://www.toymoban.com/news/detail-421374.html
完结撒花🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺🌺文章来源地址https://www.toymoban.com/news/detail-421374.html
到了这里,关于定时任务框架快速入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!