本文代码基于Python3.11解释器,除了第一次示例,代码将省略 import re 这个语句
所有示例代码均可以在我的github仓库中的 code.py文件内查看
[我的仓库](PythonLearinig/正则表达式 at main · saopigqwq233/PythonLearinig (github.com))
搞清楚Python正则表达式语法,这一篇就够了
1.Python正则表达式匹配文本模式方法
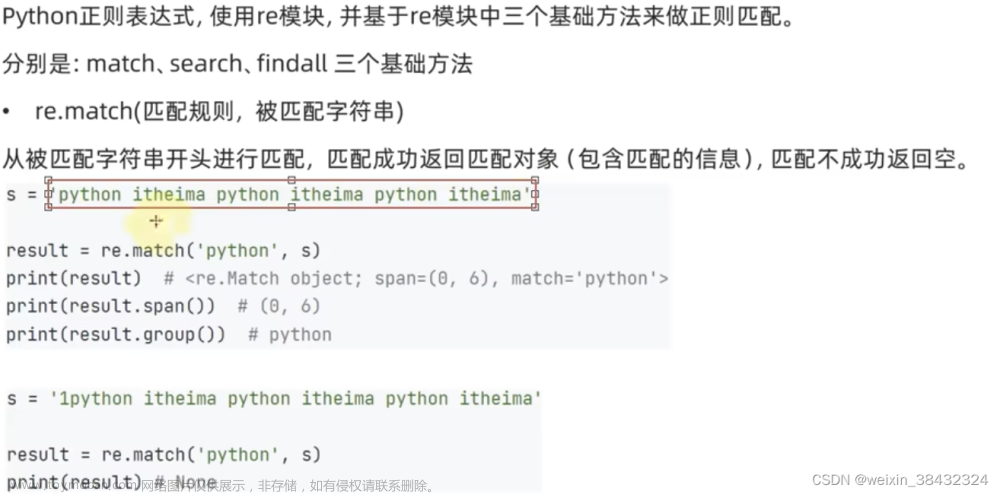
正则表达式是一种快速从文本中匹配对应模式文本的表达式,在Python中所有的正则表达式函数都在模块re中。
其一般使用方法如下:
import re
mo1 = re.compile('Batman') # 先使用re的方法compile,compile的字符串参数便是一个正则表达式
# compile将返回一个一个Regex对象,mo1就是对应正则表达式模式的对象
name1 = mo1.search('My favorite hero is Batman') # 使用mo1对象中search方法,这个方法的字符串参数就是需要被查找的字符串
# 匹配成功,那么将返回一个Match对象给name1,这个对象中有group()方法,它返回与正则表达式匹配的字符串(有些情况不全是字符串,我会在后面作解释)
# 匹配失败,返回None
print(name1.group())
输出结果如下:

2.直接查找模式
2.1直接查找
上面的代码就是直接查找模式,正则表达式字符串是'Batman',则需要在字符串'My favorite hero is Batman',寻找'Batman'
2.2管道匹配多种模式
有时,需要匹配的文本有多种可能,需要不同的正则表达式匹配模式,可以用‘|’这个符号来表示管道匹配,即匹配多种可能
示例如下:
mo2 = re.compile(r'Batman|Superman')
name2 = mo2.search('My favorite hero is Superman')
print(name2.group())
正则表达式是'Batman|Superman',那么在search()的字符串参数中,与之匹配的是'Superman',那么返回的Match对象赋给name2,其方法group()返回’Superman‘
输出结果如下:
2.3管道匹配多种分组模式
如果"我喜欢的英雄可能性有点大",正则表达式需要写成'Batman|Superman|Spiderman'吗?
可以,但可以用简洁的形式'(Bat|Super|Spider)man'
那么我们先看代码:
mo3 = re.compile('(Bat|Super|Spider)man')
name3 = mo3.search('My favorite hero is Spiderman')
print(name3.group())
print(name3.group(0)) # 0默认是整个匹配的字符串
print(name3.group(1)) # 1是匹配的第一个分组
search()进行匹配时,先匹配第一个分组’Bat‘’Super‘’Spider‘中的一个,再匹配’man‘;也可以认为是匹配’Batman‘'Superman''Spiderman'中的一个。
这是运行情况:
需要指出的是,在正则表达式中出现分组时,可以在group中传入参数,参数作为索引,比如在上述代码的group(1),此方法将返回第一个分组,同时,无参数或者参数为0则默认返回整个匹配文本
search()只会返回含有第一个出现的匹配文本的对象
先来看看这段代码:
mo4 = re.compile('(Bat|Super)man')
name4 = mo4.search('I love Superman and Batman')
print(name4.group()) # 只输出第一个出现的Superman
运行结果如下:

这段代码中,可以正则表达式可以匹配的文本有’Superman‘和'Batman'两个,但是name4对象的group方法只返回了第一个出现的'Superman'。
后面会有找到所有匹配文本的方法
3.查找固定类型字符模式
3.1字符类型
| 缩写字符 | 匹配字符 |
|---|---|
| \d | 0~9的数字 |
| \D | 除了0~9的其它字符 |
| \w | 字母,数字,下划线 |
| \W | 除了字符数字下划线 |
| \s | 空格制表换行符 |
| \S | 除了空格制表换行符 |
从上面表格可以看出了,大写字母匹配的字符就是小写字母匹配字符的补集
3.2固定类型模式
使用上面的缩写字符,可以匹配指定类型的字符
如代码:
mo5 = re.compile(r'\d\d\d\d\d\d\d\d\d\d\d')
phone_number1 = mo5.search('我的电话号码是15600000000')
print(phone_number1.group())
r前缀用于表示字符串是一个原始字符串,避免转义。
比如,如果无r前缀,那么字符串中的'\n'将被解释为换行符,但是如果加上r前缀,那么会被解释为''和'n'两个字符。
这在正则表达式使很有效,因为正则表达式是按照两个字符''和'd‘来匹配一个数字型的字符,如果不加前缀r,那么我们需要在正则表达式中这样写'\\d','\'代表'',代码演示如下
mo = re.compile('\\d')
num = mo.search('abcd6ef')
print(num.group())
运行结果如下:

但是需要注意的是,以下几个在正则表达式中有特殊含义的字符即使前面有r,仍然要加转义字符'\'来匹配这些特殊字符
| \ | | | + |
|---|---|---|
| * | ? | ^ |
| $ | { | } |
| ( | ) | . |
| [ | ] |
比如我们知道'()'可以分组,但是想要在文本中匹配这两个字符'('和')'时,即使加了r前缀,也需要''转义
4.分组模式
有时我们需要给查找到的电话号码分段,比如前面的+86前缀,这时,就可以用到分组模式
代码如下:
mo5 = re.compile(r'(\+86)(\d\d\d)(\d\d\d\d)(\d\d\d\d)')
phone_number1 = mo5.search('我的电话号码是+8618900000000')
print('电话号码'+phone_number1.group())
print('前缀'+phone_number1.group(1))))
在书写正则表达式的时候,给前缀+86分了一组,其后按照我的阅读习惯,344数量格式再分了三组
则
| 字符串 | 组索引 |
|---|---|
| +86 | 1 |
| 189 | 2 |
| 0000 | 3 |
| 0000 | 4 |
运行结果是

5.可有可无的分组的模式
不过,我们通常在平时记录电话号码时可能没有+86这个前缀,这时我们书写正则表达式就可以使用后缀’?‘来修饰它前面的分组,表示前面这个分组在匹配文本时可有可无,示例代码如下:
mo6 = re.compile(r'(\+86)?(\d\d\d)(\d\d\d\d)(\d\d\d\d)')
phone_number2 = mo6.search('他输入了+8615600000000到电话框')
phone_number3 = mo6.search('另一个人输入18900000000')
print(phone_number2.group())
print(phone_number3.group())
在这个正则表达式中,我们对(+86)进行可选匹配,匹配结果有'+86',返回字符串会带'+86',反之不带
第一个文本匹配返回对象中会包含返回'+8615600000000'的方法
第二个文本匹配返回对象中会包含返回'18900000000'的方法
运行结果:

6.含有特殊字符的模式
如我们在3.2中对特殊字符的讨论,我们来分析一下下面的代码:
mo7 = re.compile(r'(\(\+\d\d\))(\d\d\d)(\d\d\d\d)(\d\d\d\d)')
phone_number4 = mo7.search('我的电话号码是(+86)15600000000')
print(phone_number4.group())
r'(\(\+\d\d))(\d\d\d)(\d\d\d\d)(\d\d\d\d)'中,前缀r表示后面的字符串是原始字符串
总共分了四组,分别是:
| 模式 | 组索引 |
|---|---|
| (+\d\d) | 1 |
| \d\d\d | 2 |
| \d\d\d\d | 3 |
| \d\d\d\d | 4 |
组1匹配小括号括起来的加号和两个数字
组2匹配三个数字
组3、4匹配四个数字
运行结果是:
7.接收任意个数的字符的模式
被'*'修饰的字符或分组可以匹配0到多次,即在search()的文本中可以不出现也可以出现多次,示例代码如下:
mo8 = re.compile(r'\d*%')
money = mo8.search('本期涨幅有143%')
print(money.group())
money = mo8.search('本期涨幅为?%')
print(money.group())
在第一个正则表达式中,'\d*%'可以匹配'143%',其中'1' '4' '3'都与'\d'匹配
在第二个正则表达式中,'\d*%'可以匹配'%',因为'%'前没有数字类型可以与'\d'匹配
下面是运行结果:
8.接收一个存在的连续字符模式
'+'修饰的字符或分组可以匹配1到多次,即在search()的文本中可以出现一次也可以出现多次,示例代码如下:
mo9 = re.compile(r'\d+')
numbers = mo9.search('第一产业增加值54779亿元')
print(numbers.group())
这个正则表达式中,可以匹配到'54779'这5个数字,其中每个数字型文本都与'\d'匹配
如果没有出现被'+'修饰的字符或者分组,会怎么样呢:
mo9 = re.compile(r'\d+亿元')
numbers = mo9.search('第一产业增加值????亿元')
print(type(numbers))
这里如果我们直接输出numbers.group()返回字符串会报错。马上来解释,现在我们用type()函数测试一下变量numbers的数据类型
运行结果:
可以看到,当没找到时,search()方法返回了'NoneType',无类型,不是一个Match对象,自然是无法通过该变量获得group()方法返回的字符串。
事实上,search()方法在找不到匹配文本时就会返回一个NoneType类型
*和+的区别
| 修饰字符 | 匹配文本出现次数 |
|---|---|
| * | 0到多次 |
| + | 1到多次 |
这意味着*修饰的字符或者分组可以不用出现;
+修饰的字符或者分组必须出现。
9.字符匹配固定次数
'{}'修饰的字符或分组可以按次数匹配
9.1固定次数
如果'{}'括号内只有一个整数,如'\d{3}',表示只匹配3个数字类型字符
代码示例如下:
mo10 = re.compile(r'(\+\d\d)?(\d){11}')
phone_number5 = mo10.search('电话号码是15600000000')
print(phone_number5.group())
这段代码中,正则表达式r'(\+\d\d)?(\d){11}'表示'+\d\d'是可选匹配,可有可无,后面将匹配连续的11个数字类型字符,也就是说'15600000000'将匹配'\d'11次,运行结果如下:
当然,如果被查找的文本中是类似于'+15600000000',到底是'+15'匹配'+\d\d',后面无法匹配11个数字字符,search()返回NoneType;还是'15600000000'匹配'\d{11}'呢?
我们试一试:

可以看到,匹配情况是刚刚描述的后者,即忽略'+',匹配后面的'\d{11}'
9.2次数范围
'{}'内可以用逗号把两个升序整数分开,比如'\d{11,13}',表示可以匹配11到13个数字字符
示例代码如下:
mo11 = re.compile(r'\+?\d{11,13}')
phone_number6 = mo11.search('电话号码是+8615600000000')
print(phone_number6.group())
正则表达式r'\+?\d{11,13}'表示'+'是可选匹配,而'\d{11,13}'将匹配11到13个数字类型字符,在被查找文本当中'+'匹配正则表达式的'\+?','8615600000000'匹配'\d{11,13}'
9.3贪心匹配与非贪心匹配
'{}'默认情况下匹配最多的字符,比如'\d{4,6}',被查找文本是'1234567',那么匹配结果是'123456',如果想要正则表达式匹配最少的字符,需要在'{}'后加上'?'修饰。这里?不再表示可选匹配。
也就是说,正则表达式如果是'\d{4,6}?',那么,匹配结果是'1234',返回最少的字符。
示例代码如下:
# 贪心匹配方式
mo12 = re.compile(r'\d{3,5}')
num1 = mo12.search('数字有34567')
print(num1.group()) # 匹配最多的数字
# 非贪心匹配
mo13 = re.compile(r'\d{3,5}?')
num2 = mo13.search('数字有34567')
print(num2.group()) # 匹配最少的数字
运行结果:

9.4注意
1)’{}‘内不可以出现浮点数,否则会报错
2)'{}'允许'{3,3}'这样的写法,和'{3}'同义
3)'{a,b}',整数a必须不大于b
*查找文本所有的匹配项findall()方法
上述用到的search()方法只能查找到第一个出现的匹配文本项,如何找到全部匹配项呢?
使用Match对象的findall()方法,此方法可以返回匹配结果组成的列表,代码示例如下:
mo14 = re.compile(r'\d{11}')
phone_number7 = mo14.findall('电话号码1:15600000000'
'电话号码2:19100000000'
'电话号码3:18700000000')
print(phone_number7)
我们想要在文本中找到所有和'\d{11}'能匹配的字符,'15600000000'等电话号码都可以和正则表达式匹配,findall()将返回一个包含这些匹配文本的字符串列表
运行结果如下:

与search()不同的是,findall()直接返回一个列表而不是Match对象,所以在上面千万别把print(phone_number7)写成print(phone_number7.group())了。
如果在正则表达式内用了分组,那么会返回元组的列表,元组由分组的字符串组成,这个返回结果不含有在正则表达式中未分组的部分
代码如下:
mo15 = re.compile(r'电话号码\d:(\d{3})(\d{4})(\d{4})')
phone_number8 = mo15.findall('电话号码1:15600000000'
'电话号码2:19100000000'
'电话号码3:18700000000')
print(phone_number8)
这里,我们分别对电话号码 前三位,中间四位,最后四位 分组,那么单个匹配文本会被分成三个字符串,组成一个元组,而这些元组组合成一个列表
运行结果如下:
10.自定义匹配字符类型
10.1匹配指定字符
在正则表达式中使用'[]'可以自己定义匹配字符,比如我想找到一个句子里面所有元音开头的字母
代码示例如下:
mo16 = re.compile(r'\b[aeiouAEIOU]\w*')
vowel_word = mo16.findall('I am obviously angry with you')
print(vowel_word)
这里先介绍一下'\b'这个字符,这个字符将匹配单词的分界,也就是说将从一个单词开始匹配。
在这个字符串文本中,单词有'I' 'am' 'obviously' 'angry' 'with' 'you',
使用自定义匹配字符[aeiouAEIOU]匹配元音开头,'\w*'匹配除了空格,制表符,换行符外的字符。
10.2匹配指定的字符无需加\转义
在前面我们知道正则表达式的特殊字符前仍然需要加上''来转义表示原字符
但是,在指定字符匹配当中,无需加''转义,示例代码如下:
mo17 = re.compile(r'[*?+]+')
special_character = mo17.findall('*+?11*?')
print(special_character)
在这个正则表达式中,特殊字符'*' '?' '+'前并未加''转义,将匹配连续的几个指定字符组成的字符串,被匹配文本中'*+?'和'*?'符合
运行结果如下:
10.3匹指定字符外的字符
在指定匹配字符的前面加上^表示不匹配这些字符
代码如下:
mo18 = re.compile(r'\b[^aeiouAEIOU\n\t ]\w*')
non_vowel_word = mo18.findall('I am obviously angry with you')
print(non_vowel_word)
在这个正则表达式中,'^'表示不匹配元音字符和换行符,制表符和' '空格符。也就是说,这个正则表达式匹配非元音字母开头单词
运行结果如下:
11.^和$在正则表达式中的作用
11.1^的作用
在正则表达式前加上'^',将会怎么匹配呢?我们先看一下代码:
mo19 = re.compile(r'^(name):(\d)+')
name_phone1 = mo19.search('name:15600000000这是信息的格式')
print(name_phone1.group())
name_phone1 = mo19.search('信息的格式是name:15600000000')
print(type(name_phone1))

这里出现两个文本,但是只有第一个可以匹配成功,第二个匹配失败返回NoneType类型,这是为什么呢?是因为'^'在正则表达式开头的作用就是让匹配字符必须从被检查字符串开头开始匹配。第一个开头就是可以匹配的'name:156000000000',而第二个虽然也有这样的字符串,但是并非从开头开始匹配,便不会返回Match对象。
11.2$的作用
你知道我要说什么
mo20 = re.compile(r'(name):(\d)+$')
name_phone2 = mo20.search('信息的格式是name:15600000000')
print(name_phone2.group())
name_phone2 = mo20.search('name:15600000000这是信息的格式')
print(type(name_phone2))
与'^'相反,'$'字符将让正则表达式匹配字符串末尾的文本,比如上面的两个字符串,几乎可以直接推断出可以匹配的是第一个
以下是运行结果:
12.通配字符‘.’,匹配除了换行符的所有字符
正则表达式中,'.'可以匹配一个任意除了换行符的字符。
mo21 = re.compile(r'.at')
words = mo21.findall('The cat in the hat sat on the flat mat')
print(words)
正则表达式将匹配末尾带有'at'的所有字符串,除了'at'位于一行开头这种情况,看看结果吧:

12.1 '.*'匹配所有的字符
通过前面的关于'*'我们知道知道被'*'修饰的正则表达式字符将匹配0到多个。'*'同样可以修饰'.',来达到匹配除了换行符外所有的字符的效果。
而经过'*'修饰的'.'存在贪心匹配和非贪心匹配的情况。非贪心即在'*'后加上'?'
12.1.1贪心匹配(匹配最多的字符串)
mo22 = re.compile(r'names:(.*) phone number:(.*)')
users_info = mo22.findall('names:Mike phone number:15600000000 '
'names:Jack phone number:18100000000 '
'names:John phone number:16200000000 ')
print(users_info)
正则表达式将匹配'names:'开头加上其后的所有字符,直到遇到换行符或者字符串最后为止。
注意我这里的被查找字符串是由空格分开而非换行符,为方便看每行内容我用三个 '' 分开了字符串。
先看看运行结果:
从返回结果来看
1)列表中只含一个元组,说明整个正则表达式只匹配了一个字符串
2)findall返回分组的匹配字符串,从中可以推断出,正则表达式'names:'匹配了被查找字符串的'names:',正则表达式'(.)'匹配了从'Mike'到'John'的所有字符,正则表达式' phone number:'匹配了被查找字符的'phone number:',第二个'(.)'匹配了'16200000000'
12.1.2非贪心匹配(匹配最少的字符串)
在'*'修饰后加上'?'就可以改成非贪心匹配。代码如下:
mo23 = re.compile(r'names:(.*?) phone number:(.*?) ')
users_info = mo23.findall('names:Mike phone number:15600000000 '
'names:Jack phone number:18100000000 '
'names:John phone number:16200000000 ')
print(users_info)
先来看看运行结果:
列表中有三个元组,说明被查找的字符串中有三组字符串和正则表达式匹配成功。
1)第一组匹配:'names:'匹配'names:','(.*?)'匹配'Mike',空格匹配空格,'phone number'匹配'phone number','(.*?)'匹配'15600000000'
2)3)同1)
12.2 '.*'匹配换行符
事实上可以通过向compile()方法传关键字参数就可以让'.*'匹配换行符。
我们先看看不加关键字实参的情况
mo24 = re.compile('.*')
sentences = mo24.search("I can see empty streets.\nBut I can't sleep empty sheets\n")
print(sentences.group())
由于'.'不能匹配换行符,所以文本只能匹配到'I can see empty streets.'
来看看运行结果:
显然我们的判断没错
现在我们将关键字实参re.DOTALL传入compile()方法
mo25 = re.compile('.*', re.DOTALL)
sentences = mo25.search("I can see empty streets.\nBut I can't sleep empty sheets\n")
print(repr(sentences.group()))
print(sentences.group())
容我先解释一下 repr(str)函数的作用,它返回字符串str的原字符串,不进行转义。
在这个正则表达式中,'.*'将匹配所有的字符,那么,search()将要返回的是,包含所有被查找文本字符的对象
我们来看看运行结果:
可以看到,repr()返回的字符串内含有所有被查找文本,包括换行符也被'.'匹配
13.模糊大小写
我们在输入验证码验证自己不是机器人时,往往大小写均可以让自己通过。那么在正则表达式当中,我们也想在匹配时忽略大小写。只需要向compile()方法传入关键字实参re.IGNORECASE即可,速记一下就是ignore case大写并且去空格
mo26 = re.compile(r'england|china|america', re.IGNORECASE)
country_name = mo26.search("THE PEOPLE'S REPUBLIC OF CHINA")
print(country_name.group())
由于大小写模糊,'CHINA'和正则表达式中的'china'匹配
运行结果:
14.更好得书写管理正则表达式
过于复杂的正则表达式将变得难以理解,那么可以通过以下几个方法让正则表达式易理解:
14.1多段 '' 连接
比如我们想在一串文本中找出大陆的电话号码,使用 r'' 分行并写下注释,那么可以通过以下示例代码查找:
mo27 = re.compile(r'(\+86)?' # 大陆电话前缀
r'(\d\d\d)' # 电话前三位
r'(\d\d\d\d)' # 电话中间四位
r'(\d\d\d\d)') # 电话后四位
phone_number9 = mo27.search('电话号码是:15600000000')
print(phone_number9.group())
运行结果:
14.2关键字实参re.VERBOSE
可以使用关键字实参和多行字符串''' ''' 标识,来使正则表达式更易读。
mo28 = re.compile(r'''(\+86)? # 大陆电话前缀
(\d{3}) # 电话前三位
(\d{4}) # 电话中间四位
(\d{4}) # 电话后四位
''', re.VERBOSE)
phone_number10 = mo28.search('电话号码是:15600000000')
print(phone_number10.group())
运行结果:
15.多个关键字实参
如果我们想要正则表达式匹配时模糊大小写,并且让'.'可以匹配到换行符,直接这样写mo = re.compile(r'',re.DOTALL,re.IGNORECASE)
是不被允许的,因为compile()最多只有两个参数。
那么,如何解决呢?
可以在几个关键字实参之间用'|'间隔达到多个关键字实参的效果
mo29 = re.compile(r'nice to meet you,.*',re.DOTALL|re.IGNORECASE)
response = mo29.search('NICE to Meet You,Sir.\nHow can I help you?')
print(repr(response.group()))
print(response.group())
这样,既可以有 模糊大小写的效果,也有让 '.'匹配换行符的效果
运行效果: 文章来源:https://www.toymoban.com/news/detail-421652.html
文章来源:https://www.toymoban.com/news/detail-421652.html
感谢你阅读我的博客,如果你对我的内容有任何的意见、建议或者问题,欢迎在评论区留言,我会尽快回复。如果你发现了我的错误或者疏漏,也请不吝指正,我会及时修改。希望我的博客能对你有所帮助,也期待与你的交流和分享。文章来源地址https://www.toymoban.com/news/detail-421652.html
到了这里,关于搞懂Python正则表达式,这一篇就够了的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!