目录
开发环境
数据描述
功能需求
数据准备
数据清洗
用户行为分析
找出有价值的用户
开发环境
Hadoop+Hive+Spark+HBase
启动Hadoop:start-all.sh
启动zookeeper:zkServer.sh start
启动Hive:
nohup hiveserver2 1>/dev/null 2>&1 &
beeline -u jdbc:hive2://192.168.152.192:10000
启动Hbase:
start-hbase.sh
hbase shell
启动Spark:spark-shell
数据描述
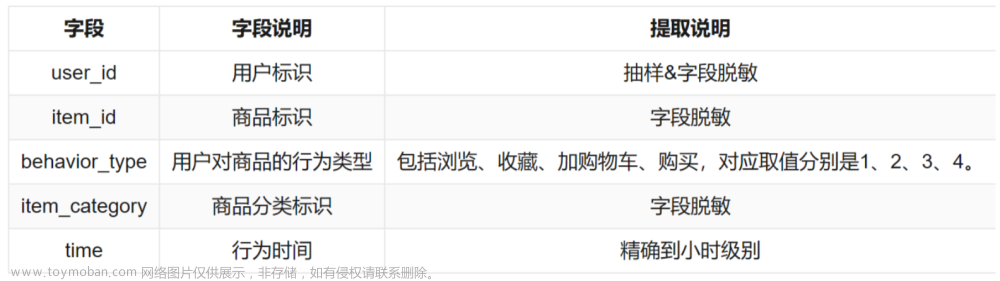
数据描述 UserBehavior 是阿里巴巴提供的一个淘宝用户行为数据集。本数据集包含了 2017-09-11 至 2017-12-03 之间有行为的约 5458 位随机用户的所有行为(行为包括点击、购买、加 购、喜欢)。数据集的每一行表示一条用户行为,由用户 ID、商品 ID、商品类目 ID、 行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下具体字段 说明如下:

功能需求
数据准备
请在 HDFS 中创建目录/data/userbehavior,并将 UserBehavior.csv 文件传到该目录。通过 HDFS 命令查询出文档有多少行数据。
hdfs dfs -mkdir -p /data/userbehavior
hdfs dfs -put ./UserBehavior.csv /data/userbehavior
hdfs dfs -cat /data/userbehavior/UserBehavior.csv | wc -l
数据清洗
①请在 Hive 中创建数据库 exam
create database exam;②请在 exam 数据库中创建外部表 userbehavior,并将 HDFS 数据映射到表中
create external table userbehavior
(
user_id int,
item_id int,
category_id int,
behavior_type string,
`time` bigint
)
row format delimited fields terminated by ',' stored as textfile location '/data/userbehavior/';③请在 HBase 中创建命名空间 exam,并在命名空间 exam 创建 userbehavior 表,包含一个列簇 info
hbase(main):007:0> create_namespace 'exam'
hbase(main):008:0> create 'exam:userbehavior','info'④请在 Hive 中创建外部表 userbehavior_hbase,并映射到 HBase 中,并将数 据加载到 HBase 中
create external table if not exists userbehavior_hbase(
user_id int,
item_id int,
category_id int,
behavior_type string,
time bigint
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping"=":key,info:item_id,info:category_id,info:behavior_type,info:time")
tblproperties ("hbase.table.name"="exam:userbehavior");
//开始映射
insert into userbehavior_hbase select * from userbehavior;
⑤请在 exam 数据库中创建内部分区表 userbehavior_partitioned(按照日期进行分区), 并通过查询 userbehavior 表将时间戳格式化为”年-月-日 时将数据插 入至 userbehavior_partitioned 表中,例如下图

//设置分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
//创建分区表
create table userbehavoir_partitioned(
user_id int,
item_id int,
category_id int,
behavior_type string,
time string
)
partitioned by (dt string)stored as orc ;
//按格式插入分区表中
insert into userbehavoir_partitioned partition (dt)
select user_id,item_id,category_id,behavior_type,
from_unixtime(time,"YYYY-MM-dd HH:mm:ss") as time,
from_unixtime(time,"YYYY-MM-dd")as dt
from userbehavior;
show partitions userbehavoir_partitioned;
select * from userbehavoir_partitioned;用户行为分析
请使用 Spark,加载 HDFS 文件系统 UserBehavior.csv 文件,并分别使用 RDD 完成以下 分析。 统计 uv 值(一共有多少用户访问淘宝)
scala> val fileRdd=sc.textFile("/data/userbehavior")
//数据进行处理
scala> val userbehaviorRdd=fileRdd.map(x=>x.split(",")).filter(x=>x.length==5)
//统计不重复的个数
scala> userbehaviorRdd.map(x=>x(0)).distinct.count
res8: Long = 5458 分别统计浏览行为为点击,收藏,加入购物车,购买的总数量
scala> userbehaviorRdd.map(x=>(x(3),1)).reduceByKey(_+_).collect.foreach(println)
(cart,30888)
(buy,11508)
(pv,503881)
(fav,15017)找出有价值的用户
使用 SparkSQL 统计用户最近购买时间。以 2017-12-03 为当前日期,计算时间范围 为一个月,计算用户最近购买时间,时间的区间为 0-30 天,将其分为 5 档,0-6 天,7-12 4 天,13-18 天,19-24 天,25-30 天分别对应评分 4 到 0文章来源:https://www.toymoban.com/news/detail-421862.html
scala> spark.sql("""
| select
| t1.user_id,
| ( case when t1.diff between 0 and 6 then 4
| when t1.diff between 7 and 12 then 3
| when t1.diff between 13 and 18 then 2
| when t1.diff between 19 and 24 then 1
| when t1.diff between 25 and 30 then 0
| else null end
| ) level
| from
| (select user_id, datediff('2017-12-03',max(dt)) as diff, max(dt) as maxNum
| from exam.userbehavior_partitioned where dt>'2017-11-03' and behavior_type='buy'
| group by user_id) t1
| """).show使用 SparkSQL 统计用户的消费频率。以 2017-12-03 为当前日期,计算时间范围为 一个月,计算用户的消费次数,用户中消费次数从低到高为 1-161 次,将其分为 5 档,1-32,33-64,65-96,97-128,129-161 分别对应评分 0文章来源地址https://www.toymoban.com/news/detail-421862.html
scala> spark.sql("""
| with
| t1 as (select user_id, count(user_id) num
| from exam.userbehavior_partitioned
| where dt between '2017-11-03' and '2017-12-03'
| and behavior_type='buy'
| group by user_id)
| select t1.user_id,
| (
| case when t1.num between 1 and 32 then 0
| when t1.num between 33 and 64 then 1
| when t1.num between 65 and 96 then 2
| when t1.num between 97 and 128 then 3
| when t1.num between 129 and 161 then 4
| else null end
| ) level
| from t1
| """).show
到了这里,关于大数据实战 --- 淘宝用户行为数据分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!