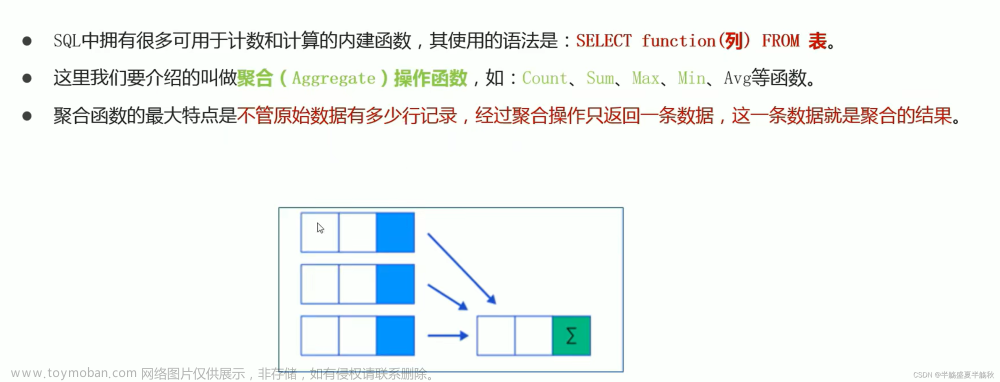
在分析或者处理大规模数据时,由于数据量较大时,一般只能随机抽样一部分的数据来分析,那么如何进行随机抽样呢?
下面有几种方法,目前常用的是distribute by rand() sort by rand() limit n
- order by rand() : order by 是全局的,比较耗时, 只有一个reduce,是真正的随机
select * from test_user_info_log order by rand() limit 10;
- sort by rand() : 提供了单个reducer内的排序,不保证整体有序,不是真正的随机
select * from test_user_info_log sort by rand() limit 10;
- distribute by rand() sort by rand() 是真正的随机抽样
select * from test_user_info_log
distribute by rand()
sort by rand()
limit 10;
可以保证数据在map端和reduce端都是随机分布的,是进行了2次随机,这个时候可以做到真正的随机
4) cluster by rand() 也是真正的随机
等价与distribute by rand() sort by rand() 也是真正的随机,并且仅随机一次,速度会比方法3快
select * from test_user_info_log
cluster by rand()
limit 10;
- 分层抽样-分层抽个数
分层抽样有两种,一种是分层抽个数,一种是分层抽比例
下面的case是每种类型的用户抽样3个文章来源:https://www.toymoban.com/news/detail-422007.html
select
*
from (
select
buyer_id,user_type,
row_number() over(partition by user_type order by rand() ) as rn
from
di.ba_ad_new_cate_fsp_byr where pt='2021-12-01'
) tmp
where rn<=3;
- 分层抽比例
例如:下面的case是每种类型的用户抽样50%的数据
select
*
from (
select
buyer_id,user_type,
row_number() over(partition by user_type order by rand() ) as rn
from
di.ba_ad_new_cate_fsp_byr where pt='2021-12-01'
) tmp
where pmod(rn,2) = 0;
- 如果数据量比较少,也可以用takeSample(false, 500)的方法来抽样
spark.sql(s"select distinct buyer_id, order_id from order_info ")
.rdd.takeSample(false, 500)
通过对takeSample采样分析发现,他是利用我们要取的数据量,和总的数据量计算出一个概率,然后再利用这个概率去进行二项分布抽样或者是泊松抽样。所以说不管是sample方法,还是takeSample方法,底层抽样的原理都是一样的,都是通过概率进行抽样的。
原理是将数据拉回到driver后返回成数组的形式,而不是rdd了文章来源地址https://www.toymoban.com/news/detail-422007.html
- tablesample 对一个表中的数据按行数或者比例抽样
select * from temp.order_test tablesample(1 percent) --按照hive表的数据量比例抽样数据, n是百分比
select * from temp.order_test tablesample(3 rows) --指定抽样数据的行数,n随机抽样n行
到了这里,关于hive 随机抽样 distribute by rand() sort by rand() limit n的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!