基于之前的AI主播的的学习基础 基于Wav2Lip的AI主播 和 基于Wav2Lip+GFPGAN的高清版AI主播,这次尝试一下VideoRetalking生成效果。
总体来说,面部处理效果要好于Wav2Lip,而且速度相对于Wav2Lip+GFPGAN也提升很多,也支持自由旋转角度,但是如果不修改源码的情况下,视频的部分截取稍微有点问题。
这个训练图片还好,如果是做视频的话还是比较吃GPU资源的 16G显存是个起步配置。
准备工作
从github上下载源码,下载完毕之后下载模型 SadTalker v0.0.1 Release Note。
模型分这么多种类,如果使用哪个模型将该文件夹下的内容复制到 checkpoints 中。
环境配置
首先要自己配置好 GPU 的 Pytorch 环境。如果不会的话看这里。
Win10+Python3.9+GPU版pytorch环境搭建最简流程
配置环境之后需要基于 Anaconda 环境,环境不会安装看这里。
Python初学者在不同系统上安装Python的保姆级指引
创建虚拟环境
为了不必要的麻烦,在你的虚拟环境下创建 python3.7.1 其他版本多少都有些问题,不好解决,必须保持网络畅通否则安装不成功。
conda create -n Wav2Lip python=3.6
激活虚拟环境
这里是我的路径,修改成你自己的。
conda create -n SadTalker python=3.8
conda activate SadTalker
pip安装匹配版本
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install ffmpy Cmake boost dlib-bin # [dlib-bin is much faster than dlib installation] conda install dlib
pip install -r requirements.txt
这里需要安装 gfpgan,一般安装方法有点难受可能不会成功,直接自己在python的包的文件夹下克隆好了进行安装吧。
git clone https://github.com/TencentARC/GFPGAN.git
python setup.py install
关于 pytorch 如果你不会配置的话看这里。
Win10+Python3.9+GPU版pytorch环境搭建最简流程
模型预测对口型
这里测试了几次之后才发现 Wav2Lip 是根据声音的波形对齐口型的,并不是我开始认为的按照表达的文字模式。
必要的数据准备
事先还要准备好背景图片和音频文件,这里分别放置原始的图片,音频以及视频文件。


图片、视频预测
代码格式。
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--batch_size <default equals 2, a larger run faster> \
--expression_scale <default is 1.0, a larger value will make the motion stronger> \
--result_dir <a file to store results> \
--enhancer <default is None, you can choose gfpgan or RestoreFormer>
常用命令。
python inference.py --driven_audio input/audio/kimk_7s_raw.mp3 --source_image input/video/kimk_7s_raw.mp4 --result_dir output/ --enhancer gfpgan
参数说明
--driven_audio:输入的音频文件路径。
--source_image:输入的图像文件路径,支持音频文件和视频MP4格式。
--checkpoint_dir:模型存放路径。
--result_dir:数据导出路径。
--pose_style:输入的姿势,0-45可选。
--batch_size:数值越大消耗越大,速度越快。
--expression_scale:运动性更强,这个不要动,人物会很鬼畜。
--camera_yaw:摄像机偏航度。
--camera_pitch:摄像机俯仰角度。
--camera_roll:摄像机滚转程度
--enhancer:高清模型,选择gfpgan或RestoreFormer
--cpu:是使用,无视吧。
有趣的操作
可以提供过摄像机角度的参数进行旋转操作。
Stable Diffusion 使用方法
手动在SD中安装拓展包。
https://github.com/Winfredy/SadTalker

这里显示安装已经完成。
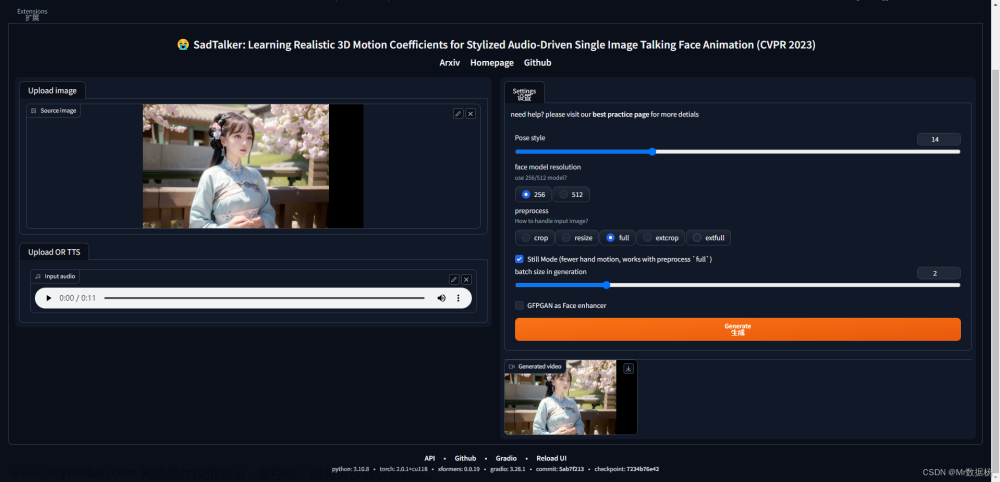
在你的sd文件夹下将之前下载好的模型 checkpoints 目录复制到该SD目录下扩展的 SadTalker 目录下即可,红色的文件必须是压缩包解压缩后的状态。

重启你的SD之后会出现对应的选项卡,无脑操作即可。 文章来源:https://www.toymoban.com/news/detail-422118.html
文章来源:https://www.toymoban.com/news/detail-422118.html
【分享】SadTalker
百度网盘
夸克网盘 提取码:Av5Z文章来源地址https://www.toymoban.com/news/detail-422118.html
到了这里,关于基于SadTalker的AI主播,Stable Diffusion也可用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!