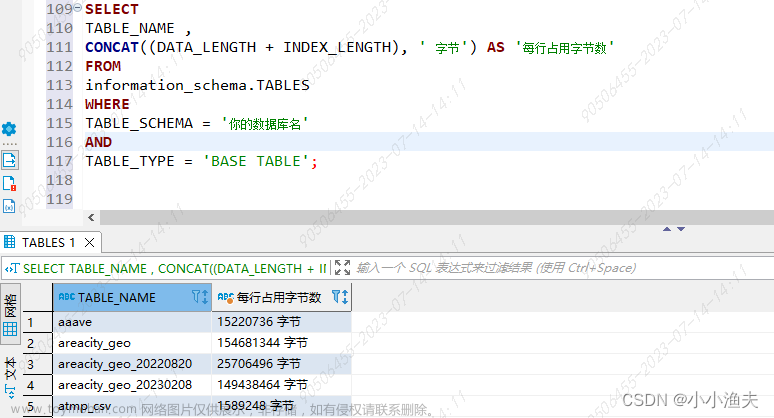
索引所占空间的增长确实会对MySQL数据库的写入性能和查询性能造成影响,这主要是由于索引数据过多时会导致磁盘I/O操作变得非常频繁,从而使性能下降。为此,可以采取以下几种方式来减缓这种影响:
文章来源:https://www.toymoban.com/news/detail-422337.html
1. 限制索引的大小:可以考虑为索引指定大小限制,在存储时仅存储指定大小内的数据。例如,在创建索引时可以使用“INDEX col_name(length)”的语法,其中length表示应该存储的字符数。这样,索引的大小将被限制在指定大小内,从而有助于减少索引数据的空间占用。
2. 使用前缀索引:前缀索引是指仅对列值的一个前缀创建索引,而不是对整个列值进行索引。通过使用前缀索引,可以将索引的大小降低到原本的一半或更少。但是需要注意,这样做可能会影响查询性能,因为通常只能匹配前缀长度相同的数据,而不是完整的列值。
3. 压缩存储引擎:MySQL支持使用压缩存储引擎来减少存储索引所需的空间。例如,可以使用InnoDB存储引擎的压缩功能来减少索引数据的物理磁盘空间。
MySQL提供了多种压缩存储引擎选项,例如InnoDB压缩表和MyISAM压缩表等。其中,InnoDB压缩表是最常用的一种压缩存储引擎。下面是使用InnoDB压缩表进行压缩的方法: 1. 首先,需要确认InnoDB存储引擎已经被启用和配置。可以通过MySQL配置文件(my.cnf)中的以下设置来启用和配置InnoDB存储引擎: [mysqld] # 启用InnoDB存储引擎 default-storage-engine = innodb # 开启InnoDB文件的独立表空间,支持InnoDB的压缩功能 innodb_file_per_table = on 以上设置会启用默认存储引擎为InnoDB,并开启InnoDB表的独立表空间,以支持InnoDB存储引擎的压缩功能。 1. 创建一个InnoDB压缩表: CREATE TABLE my_compressed_table ( col1 INT, col2 VARCHAR(100), col3 TEXT ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8; 在创建表时,需要指定ROW_FORMAT=COMPRESSED选项以启用压缩功能,并指定KEY_BLOCK_SIZE选项以设置索引的块大小。这些设置都会影响表和索引的空间和性能。 1. 将现有的InnoDB表转换为压缩表: ALTER TABLE my_table ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8; 以上就是使用InnoDB压缩表进行压缩的基本方法。需要注意的是,使用压缩功能通常会增加CPU的负载,因此需要仔细评估存储空间和压缩效果之间的折衷,并进行相应的配置优化。
4. 调整数据类型:如果索引占用的空间过大,可以考虑调整数据类型以减少所需的空间。例如,如果使用了INT类型来存储数据,但实际上只有很少的数据,可以考虑使用TINYINT或SMALLINT等更小的数据类型。同样,如果使用了VARCHAR等可变长度数据类型,可以考虑将列值转换为定长数据类型来减少索引大小。
总之,虽然索引所占空间的增长会影响MySQL数据库的性能,但通过一些优化技术可以减轻影响并提高数据库的性能。具体如何处理,需要根据实际情况进行分析和调整。文章来源地址https://www.toymoban.com/news/detail-422337.html
到了这里,关于Mysql中如果建立了索引,索引所占的空间随着数据量增长而变大,这样无论写入还是查询,性能都会有所下降,怎么处理?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!