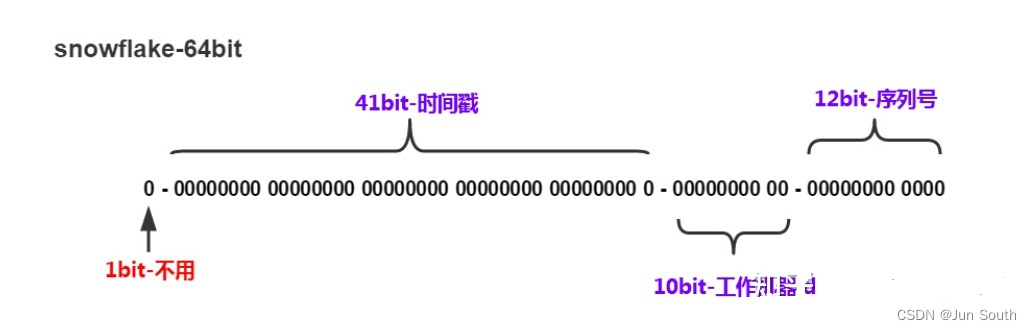
项目中使用的是hutool工具类库提供的雪花算法生成id方式,版本使用的是5.3.1
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.3.1</version>
</dependency>
雪花算法生成id方式提供了getSnowflake(workerId,datacenterId)获取单例的Snowflake对象,并对生成id的方法nextId()进行了synchronized加锁处理。
IdUtil
public static Snowflake getSnowflake(long workerId, long datacenterId) {
return Singleton.get(Snowflake.class, workerId, datacenterId);
}
Snowflake
public synchronized long nextId() {
long timestamp = genTime();
if (timestamp < lastTimestamp) {
// 如果服务器时间有问题(时钟后退) 报错。
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) | (dataCenterId << dataCenterIdShift) | (workerId << workerIdShift) | sequence;
}
项目中使用雪花算法
IdUtils
public class IdUtils {
private static final Snowflake SNOWFLAKE = IdUtil.getSnowflake(1, 1);
public static Long getNextId() {
return SNOWFLAKE.nextId();
}
}
举例controller
UserController
@Slf4j
@RestController
@RequestMapping("/id")
public class UserController {
@Autowired
private IUserService userService;
@GetMapping("/next")
public Long next() {
Long id = IdUtils.getNextId();
User user = new User().setId(id);
boolean save = userService.save(user);
if (save) {
return id;
}
return 0L;
}
}
线上环境报例如:BatchUpdateException: Duplicate entry ‘1531683498452185090’ for key ‘PRIMARY’ 插入主键冲突问题。
分析代码,定位到雪花算法生成id时出现了问题
首先排除时钟回退的情况,因为在5.3.1版本如果服务器时间有问题(时钟后退) 直接报错。
1单机
排除单机情况下出现id重复问题,SNOWFLAKE 是单例的,并且生成id的方法被synchronized修饰。
2集群环境下
需要手动设置dataCenterId 和 workerId值,不同机器相同时间戳要想保证生成的id不重复,那么dataCenterId 和workerId的组合必须是唯一的
private static final Snowflake SNOWFLAKE = IdUtil.getSnowflake(workerId , dataCenterId );
Mybatis-Plus v3.4.2 雪花算法实现类 Sequence,提供了两种构造方法:无参构造,自动生成 dataCenterId 和 workerId;有参构造,创建 Sequence 时明确指定标识位
Hutool v5.7.9 参照了 Mybatis-Plus dataCenterId 和 workerId 生成方案,提供了默认实现
一起看下 Sequence 的创建默认无参构造,如何生成 dataCenterId 和 workerId
public static long getDataCenterId(long maxDatacenterId) {
long id = 1L;
final byte[] mac = NetUtil.getLocalHardwareAddress();
if (null != mac) {
id = ((0x000000FF & (long) mac[mac.length - 2])
| (0x0000FF00 & (((long) mac[mac.length - 1]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
return id;
}
入参 maxDatacenterId 是一个固定值,代表数据中心 ID 最大值,默认值 31
为什么最大值要是 31?因为 5bit 的二进制最大是 11111,对应十进制数值 31
获取 dataCenterId 时存在两种情况,一种是网络接口为空,默认取 1L;另一种不为空,通过 Mac 地址获取 dataCenterId
可以得知,dataCenterId 的取值与 Mac 地址有关
接下来再看看 workerId
public static long getWorkerId(long datacenterId, long maxWorkerId) {
final StringBuilder mpid = new StringBuilder();
mpid.append(datacenterId);
try {
mpid.append(RuntimeUtil.getPid());
} catch (UtilException igonre) {
//ignore
}
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
入参 maxWorkderId 也是一个固定值,代表工作机器 ID 最大值,默认值 31;datacenterId 取自上述的 getDatacenterId 方法
name 变量值为 PID@IP,所以 name 需要根据 @ 分割并获取下标 0,得到 PID
通过 MAC + PID 的 hashcode 获取16个低位,进行运算,最终得到 workerId
分配标识位
Mybatis-Plus 标识位的获取依赖 Mac 地址和进程 PID,虽然能做到尽量不重复,但仍有小几率
当然了我们也可以自己实现生成workerId、datacenterId的策略
如下,但并未测试过
@Configuration
public class SnowFlakeIdConfig {
@Bean
public SnowFlakeIdUtil propertyConfigurer() {
return new SnowFlakeIdUtil(getWorkId(), getDataCenterId(), 10);
}
/**
* workId使用IP生成
* @return workId
*/
private static Long getWorkId() {
try {
String hostAddress = Inet4Address.getLocalHost().getHostAddress();
int[] ints = StringUtils.toCodePoints(hostAddress);
int sums = 0;
for (int b : ints) {
sums = sums + b;
}
return (long) (sums % 32);
}
catch (UnknownHostException e) {
// 失败就随机
return RandomUtils.nextLong(0, 31);
}
}
/**
* dataCenterId使用hostName生成
* @return dataCenterId
*/
private static Long getDataCenterId() {
try {
String hostName = SystemUtils.getHostName();
int[] ints = StringUtils.toCodePoints(hostName);
int sums = 0;
for (int i: ints) {
sums = sums + i;
}
return (long) (sums % 32);
}
catch (Exception e) {
// 失败就随机
return RandomUtils.nextLong(0, 31);
}
}
}
很显然这些方法都依赖于获取ip 等信息,比如ip并非连续,甚至获取不到ip等信息时,还是有可能出现id重复问题
3docker容器
就比如在docker容器中,一般ip都是随机的,并且未经过设置还无法获得ip信息。
docker容器和宿主机环境是隔离的,但是可以在启动docker容器时将宿主机的主机名以环境变量的形式传入,代码在容器中获取该值即可。
这里采用另一种方法,我们可以手动设置workid生成规则,并存到redis中。
这里只设置了workId,保证workId和dataCenterId的组合不重复就可以。
workId的生成是系统每次启动,第一次获取Snowflake 对象时才会进行,
public class IdUtils {
private static StringRedisTemplate stringRedisTemplate = ApplicationContextHolder.getBean(StringRedisTemplate.class);
private static String SNOWFLAKE_WORKID = "snowflake:workid";
private static final Snowflake SNOWFLAKE = IdUtil.getSnowflake(getWorkerId(SNOWFLAKE_WORKID), 1);
public static Long getNextId() {
return SNOWFLAKE.nextId();
}
/**
* 容器环境生成workid 并redis缓存
* @param key
* @return
*/
public static Long getWorkerId(String key) {
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("redis/redis_worker_id.lua")));
redisScript.setResultType(Long.class);
return stringRedisTemplate.execute(redisScript, Collections.singletonList(key));
}
}
ApplicationContext对象的获取 ,解决使用注解获取不到bean的问题
@Component
public class ApplicationContextHolder implements ApplicationContextAware {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
ApplicationContextHolder.applicationContext = applicationContext;
}
/**
* 全局的applicationContext对象
* @return applicationContext
*/
public static ApplicationContext getApplicationContext() {
return applicationContext;
}
@SuppressWarnings("unchecked")
public static <T> T getBean(String beanName) {
return (T) applicationContext.getBean(beanName);
}
public static <T> T getBean(Class<T> clazz) {
return applicationContext.getBean(clazz);
}
}
lua脚本 redis_worker_id.lua
workId初始为0 ,每次获取后+1,知道获取到31后重置为0
为什么上限是31呢,因为workId默认占5bit
local isExist = redis.call('exists', KEYS[1])
if isExist == 1
then
local workerId = redis.call('get', KEYS[1])
workerId = (workerId + 1) % 31
redis.call('set', KEYS[1], workerId)
return workerId
else
redis.call('set', KEYS[1], 0)
return 0
end
测试
使用nginx 端口8080
location /api {
default_type application/json;
#internal;
keepalive_timeout 30s;
keepalive_requests 1000;
#支持keep-alive
proxy_http_version 1.1;
rewrite /api(/.*) $1 break;
proxy_pass_request_headers on;
#more_clear_input_headers Accept-Encoding;
proxy_next_upstream error timeout;
#proxy_pass http://127.0.0.1:8081;
proxy_pass http://backend;
}
}
upstream backend {
server 127.0.0.1:8081 max_fails=5 fail_timeout=10s weight=1;
server 127.0.0.1:8082 max_fails=5 fail_timeout=10s weight=1;
}
代理访问8081、8082两个项目
将自己的项目端口号设置为8081,并复制Copy Configuration ,VM options设置
-Dserver.port=8082
这样启动nginx8080,项目8081、8082
然后使用Jmeter进行压测,比如1000个线程 循环10次进行插入数据库
访问路径
不再出现id重复问题

参考
https://blog.csdn.net/weixin_36586120/article/details/118018414文章来源:https://www.toymoban.com/news/detail-422534.html
https://www.cnblogs.com/hzzjj/p/15117771.html
https://blog.csdn.net/nickDaDa/article/details/89357667文章来源地址https://www.toymoban.com/news/detail-422534.html
到了这里,关于线上使用雪花算法生成id重复问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!