一般理解
很多人对内存的认识并没有那么透彻。
只知道基本数据类型(值类型)存放在“栈内存”中。引用数据类型(对象类型)存放在“堆内存”中。

内存概念
首先,栈和堆都是JS引擎或JVM虚拟机等运行环境创建的内存模型,由CPU管理控制。
既然是模型,那就是虚构的,是一种对内存的管理方式和模型概念。
当然,这种模型正是我们需要掌握的知识。而真实的物理内存只需要了解一下就行。
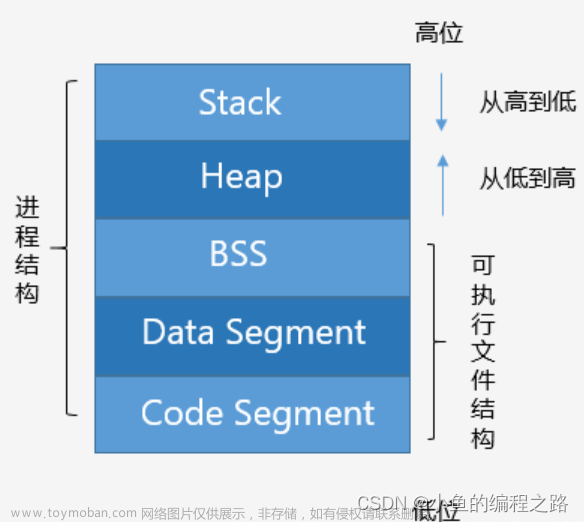
内存模型除了将内存划分为栈内存和堆内存,还有常量池和方法区等。
关于栈(Stack)
“栈”具有线程和“先进后出”的特点,也就是每个栈桢一般会保存下一个栈桢的地址,指向next节点(即指向下一个栈桢),从而手牵手形成类似队列的链式结构。同时先入栈的会先执行,后入栈的会先弹出(执行完销毁)。
线程是CPU最小执行单元,是单一顺序的控制流,每个线程都有自己的调用栈call stack。
栈可以分为CPU的线程栈(在CPU中保存“执行上下文”用于任务调度)和内存的空间栈(在内存中保存变量等资源以供CPU调用执行)。
而我们所说的栈内存一般指的是内存的空间栈。
堆内存(Heap)
是内存中最大的一块内存区域,也是被各个线程共享的内存区域,所有的对象实例(或复杂类型信息)都保存在堆内存中。
栈和堆之间的关系
对象做为引用类型是保存在堆内存中的,但是要通过保存在栈中的指针来访问。
对象可能包含属性和方法,而这些属性和方法中可能包含基本类型的变量。因此,堆内存中的一些变量在声明和调用过程中又会放到栈内存中进行执行。
指针
人们通常把“内存地址”形象地称做“指针”。
栈内存和堆内存都是通过指针找到值(基本数据、对象、函数体等内容)。
CPU为了管理内存而建立的虚拟地址空间(指针页表,Map或表结构),将虚拟地址映射到物理地址。
指针页表
管理内存的Map页表由操作系统按一定规则创建。由虚拟内存的各个用户空间共同维护,不同的进程(应用程序)管理自已独占的用户空间。
每次修改数据,都会更新Map表,记录哪些物理内存空间已经被使用,以及内存数据被调用次数。
每调用一次+1,每回收一次-1。如果没有调用,即调用次数=0,将会被允许修改这块内存空间。
也就是所有内存都不需要删除数据,反正没人用,就相当于空白区域,有新的数据就覆盖写入,然后把这个数据的首地址和末地址更新到页表中,表示已有人使用。
每次电脑重启以后,将重新建立指针页表。
变量
变量名是栈内存指针的别名。
因为可以先声明变量,后赋值。
声明变量是在指针页表里建立变量信息。而赋值才是真正的开辟内存空间。但是为了节省内存,会先在内存中查找有没有相同的值,如果有就把找到的内存地址更新到对应的map页表中,如果没有才会开辟内存空间,写入数据,并将内存地址更新到指针页表中。
所以变量名与值数据是分开存放的。
就因为变量与值是分开两个地方保存,所以才有“栈内存数据共享”这个特性。从而会有不同的变量名指向同一个内存,和相同变量名指向不同的内存等情况。
而保存变量名的内存地址称为指针变量。
指针变量
指针变量是保存在指针页表中的唯一主键。除了指针变量,指针页表还保存了“变量名”、“数据类型”(赋值时根据类型分配栈内存空间大小)、“指针”(值所在的物理内存空间的地址)、“作用域”(复杂的树形结构,与变量的读取和回收相关)等信息。
而这些指针变量又会加载到GO(Global Object 全局对象,也称全局执行上下文)或AO( Activation Object 活动对象,也称函数执行上下文)这两个对象中。
GO和AO统称为VO(变量对象),不过这个概念已过时。在最新ECMA的版本规范中,每一个执行上下文会关联到一个变量环境(Variable Environment,简称VE)
也就是说,内存中的变量、作用域等信息是在程序运行过程中由“执行上下文”(也叫执行环境,即VE)创建和管理的。
执行上下文(Execution Context )
执行上下文是程序代码被编译执行时在CPU和内存中生成的执行环境(即所需要的东西,比如变量对象、作用域链、this指向等等)。
一但创建“执行上下文”就会进入“执行上下文”栈,由线程栈来管理执行顺序。
执行上下文一般分为“全局执行上下文”(只有一个,它是由浏览器创建的,也就是常说的 window 对象)和“函数执行上下文”(当函数执行时,会创建一个称为执行期上下文的内部对象,执行完一次会销毁一次)。
由此可见执行上下文是一个对象,保存在堆内存中,并把指针赋给执行栈。在执行过程中,CPU解析堆内存的数据,根据不同数据类型又创建许多栈和堆引用,从而形成复杂的执行关系或环境。
作用域(scope)
作用域用来确定变量的使用范围,确保变量能否被读取,以及在使用完后及时销毁。在 JS 中作用域分为全局作用域和函数作用域,另外函数作用域可以互相嵌套。
var a = 1
function fn() {
var a = 2
function bar() {
console.log(a)
}
bar()
}
fn()各个作用域的嵌套关系组成一条"作用域链"。例子中 bar 函数的作用域链式 bar -> fn -> 全局。
作用域链主要是进行标识符(变量和函数)的查询,标识符解析就是沿着作用域链一级一级的搜索标识符的过程,而作用域链就是保证对变量和函数的有序访问。
(1)如果自身作用域中声明该变量,则无需使用作用域链。
(2)如果自身作用域中未声明该变量,则需要使用作用域链进行查找。
如果在作用域链中内没有找到变量,则会抛出ReferenceError: xxx is not defined的异常,即引用异常,也就是变量未声明。所有变量都应该先声明再使用(除了有一种未声明,赋值时自动全局的情况,应尽量避免)。
如果找到变量,却未赋值(也就是未分配内存),则变量值会是undefined(未阐明的,未定义的),即未初始化。它与赋值为null不一样。null在内存中值为0000 0000(二进制,占一个字节,对应ASCII码为NULL)。
垃圾回收
当变量赋值为null时,也就是将指针页表中的值地址指向null,表示该变量可以被释放。是否释放或销毁该变量,需要看作用域中是否有其他地方引用了该变量。
变量释放,跟变量的值是否为null并没有直接关系。只是为null的变量会被优先检索和释放。
垃圾回收机制每隔一断时间自动扫描指针页表,检索所有变量,判断被引用的次数,同时在作用域树上查找是否引用了该变量。如果引用标记次数为0,或者通过扫描未找到变量的引用。那该变量就会被释放,即从指针页表中删除。
图解内存模型

共享与独占
方法区、常量池、堆内存是所有进程共享的。
栈内存、程序计数器是每个进程独占的。
计数器和方法区
程序计数器用于存放下一条指令所在单元的地址,CPU通过它读取指令,确保执行顺序。同时,计数器的作用就是对执行的代码进行计数。如果同样的代码多次执行(权重越大),就把它放到方法区,下次不用重复编译解析,直接运行,提高速度。
方法区除了保存编译后的代码,还保存了本地方法,比如Object、Function、Array等V8引擎内置类的new Object()方法、toString()方法等等。
常量池
常量池就是专门存储字符串用的。因为代码执行过程中需要处理大量的字符串,不停创建回收,对内存消耗太大,所以单独划出内存空间来减小内存开销,专区专用,只有一种数据类型,同时提高速度。
所有的变量名都是字符串。因此,变量名都是保存在常量池中的。
用户空间
用户空间是虚拟内存的一部分,是每个进程私有的。
操作系统为每个进程分配一套独立的空间,这样使得每个进程互不干涉。
每个用户空间包含各自的栈内存和程序计数器。
缓存
缓存相当于小块的内存。从大海里找一根针,和从脸盆里找一根针,那肯定是从脸盆里找快一点。
缓存有好多种,一般是指CPU的高速缓存。还有硬盘的缓存、内存的缓存、显卡的缓存等等。
缓存的作用:(提高命中率、降低延迟、降低内存开销)
1、将访问比较频繁的一些数据存储在缓存中。2、临时存储耗时的计算结果。3、专用IO通道,提高读写速度。
数据存储
二进制
计算机所有信息数据都由二进制0和1表示。
bit(位)
内存最小单元是“位”(bit),就像一个开关,要么是0要么是1。
Byte(字节)
内存最基本存储单元是“字节”(byte),一个字节由8位(bit)组成,就像由8个开关表示一组。
它是能表示有意义的字符的基础单元。
ASCII码
通过2^8(256)个“字节”找出对照的ASCII编码,输出我们认识的最基本的字符,比如a、A、1、2、+、-、!、?等等。
ASCII编码中0000 0000(一个字节刚好8位)表示null(空),0011 0000表示0,0011 0001表示1,0011 0010表示2,0100 0001表示A,0100 0010表示B,0110 0001表示a,0110 0010表示b,0010 1011表示+,0100 0000表示@,0010 0101表示% 等等。而计算机中的汉字编码是由ASCII编码扩展而来,用双字节(2 byte、两组开关)表示一个汉字符号。
字节编址
指针页表用一串由0和1组成的数字作为字节的标识,这个过程称之为字节编址。这一串由0和1组成的数字称为字节的地址或字节的指针。
在32位系统中,一个指针由4个字节组成。
在64位系统中,一个指针大小由8个字节组成。
(4个字节,每个字节8位,每位可以有0或1两个值,2^4*8,即2的32次方,结是为4G。)
1bit最多能表示0或1,共2个数(即2^1次方)
2bit最多能表示00或01或10或11,共4个数(即2^2次方)
3bit最多能表示000或001或010或011或100或101或110或111,共8个数(即2^3次方)
以此类推,1Byte=8bit,最多能表示256个数(即2^8次方)。
那4Byte=32bit,最多能表示2^8*4,即2的32次方,就是4G个数据。
而Byte是内存的基本单元,也就是一个单元就是1B。
因此内存用Byte来表示最基本大小而不是bit,所以不能再将4GB内存理解为4G*8b。
因此,32位系统中指针页表最多只能分配4G个指针。总共就4G个编号,超过4G的内存就没有多余编号来指定了。
也就是说,32位系统最大能管理的内存是4GB。
现在知道为什么XP系统明明插上8G、16G甚至更多的内存也只能认到4G内存的原因了吧。
MB和Mb的区别
byte是“字节”的意思,用大写B表示。bit是“位”的意思,用小写b表示。
就问你有没有被宽带的网速欺骗过?100M宽带,你以为下载速度是100MB/s,结果其实是100Mb/s,下载时最大显示12.5MB/s,差了8倍,惊不惊喜?
物理内存结构
硬件内存架构没有区分栈和堆。对于硬件而言,所有的栈和堆都分布在主内存中。部分栈和堆可能有时候会出现在CPU缓存中和CPU内部的寄存器中。栈和堆是由操作系统制定规则,通过虚拟机(如JVM、V8引擎等)动态创建的内存模型的一个抽象概念。
实际上,内存是连续的“字节”单元,由首地址和未地址来确定数据的大小。内存未分配或回收后就会形成空白区域,有些空白区域太小就保存不了大的数据,因此内存需要给数据寻找合适的空白区域来存放。

内存安全漏洞
单机游戏通常可以用“内存修改器”软件来作弊,比如通过多次搜索和修改金钱的数值找到该参数所在的内存地址来修改金钱。
因此内存在计算机中是共享的,也就是不同的软件程序可以访问和修改同一块内存数据。
比如我们在内存中查找"123"这个数据,会找到0x00400000,0x037F0000,0x052E0000,0x07061E68等几十上百个指针。这些指针不是物理内存的指针,而是程序参数(即变量名)的指针。
如果确认0x052E0000就是保存金钱的指针,它在指针页表里对应的变量名是menoy,值是123对应的内存指针,现在我们修改为9999,操作系统的内存读写机制就会寻找或创建9999的内存地址,然后更新到指针页表的0x052E0000指针变量中。
图解内存数据区
我们读取或修改变量就是CPU和内存等计算机硬件根据“执行上下文”对内存进行寻址和修改的过程。
我以前对内存错误的理解存储方式:

我原先以为内存数据就像http请求一样,会有请求头和请求体。以为每个内存数据的前半段保存指针,后半段保存具体值数据。
而物理内存正确的存储方式应该是下图所示:

1、指针0001H等同于0x0001,都是16进制表示方式 。
十六进制(Hexadecimal,简写为H)用数字0-9和字母a-f(或其大写A-F)表示0到15,计算方法是逢16进1。
2、内存本身不存在指针。指针是虚拟的,是操作系统对内存字节的编号方式。将编号保存到对照表中就形成所谓的指针,即内存地址。
内存只是字节单元,也就是一组一组开关,每一组开关表示的数值可以不断在改变。内存地址是操作系统对每一个字节的编号。
内存中每个字节的值可以改变,但是指针即地址序号不会变。
因为内存中可能需要多个字节才能表示一个数据,因此才有首地址和末地址的说法。末地址减去首地址所得到的字节个数,就是数据的大小(或叫长度)。
比如一个内存数据的首地址为3001H,未地址为7000H,它能表示多少存储空间?7000H-3001H+1=4000H(十六进制)=16384(十进制)=16K字节,即该数据的大小为16KB。
3、如果4个字节的内存,却赋值给它8个字节的值,写入数据的时候就会发现空间不够,从而抛出“内存溢出”的异常。
内存溢出
内存溢出是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory。
比如内存用完了或者申请了一个int,但给它存了double才能存下的数,那就会内存溢出。
什么情况会导致栈内存溢出?
(1)栈帧过多导致栈内存溢出。比如方法的递归调用,没有设置一个正确的结束条件,不断调用自己,每次调用都会分配一个栈帧,导致栈内存溢出。
(2)栈帧过大导致内存溢出。就像前面说的用int空间去存double的值。
内存泄露
内存泄露是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
比如,栈内存指向堆内存的地址丢失,导致无法及时回收。
内存特点
1、栈内存特点
数据一执行完毕,变量会立即释放,节约内存空间。
优势:存取速度比堆要快,仅次于直接位于CPU中的寄存器。
缺点:存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。
2、堆内存特点
堆内存中所有的实体都有内存地址值,内存释放靠垃圾回收机制不定时的收取。
堆的优势:可以动态地分配内存大小。
缺点:由于要在运行时动态分配内存,存取速度较慢。
3、栈内存的数据共享:
栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义:
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找栈中是否有3这个值,如果没找到,就将3存放进来,然后将a指向3。接着处理int b = 3;在创建完b的引用变量后,因为在栈中已经有3这个值,便将b直接指向3。这样,就出现了a与b同时均指向3的情况。文章来源:https://www.toymoban.com/news/detail-422848.html
这时,如果再令a=4;那么编译器会重新搜索栈中是否有4值,如果没有,则将4存放进来,并令a指向4;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。文章来源地址https://www.toymoban.com/news/detail-422848.html
到了这里,关于秒懂 栈内存和堆内存(深入底层)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!