写在前面
本系列文章索引以及一些默认好的条件在 传送门
默认使用master节点并用root用户登录终端进行操作
文章难免会有点小bug,如果有显而易见的错误,比如没有创建文件夹时就已经开始在该文件夹下操作,还请读者自行创建~
step1 下载并解压HBase
官网下载地址
博主因为课程需要以及版本问题,下载的版本为2.0.5
请注意版本兼容性问题,具体适配情况如下图:![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-1.png)
因为Hadoop为3.1.1,所以说HBase下载2.0.5是支持的![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-2.png)
该版本下载地址
下载完成后,将该文件放置在/usr/local/下
老样子,将该文件解压到该目录下并重命名
cd /usr/local
tar -zxvf hbase-2.0.5-bin.tar.gz
mv /usr/local/hbase-2.0.5 /usr/local/hbase
step2 环境变量的配置
修改~/.bashrc文件vim ~/.bashrc
加入下面的几行:
export HBASE_HOME=/usr/local/hbase
export PATH=$HBASE_HOME/bin:$PATH
export PATH=$HBASE_HOME/lib:$PATH
source一下让使其生效source ~/.bashrc
查看HBase版本以确实环境变量是否得体:![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-3.png)
出现版本号之后则说明环境变量设置的没问题
但是在第一次处理的时候,博主遇到了连个重复的jar包,还是有关日志文件的slf4j,如下图:![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-4.png)
在这种情况下,我们需要删除一个,博主删除的是第一个:rm -rf /usr/local/hbase/lib/slf4j-log4j12<Tab补全>
step3 配置文件修改
1. hbase-env.sh修改
跳到/usr/local/hbase/conf下,命令:cd /usr/local/hbase/conf
修改hbase-env.sh,命令vim hbase-env.sh
加入:
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop
export HBASE_MANAGES_ZK=false
根据自己的JDK版本进行添加,切勿盲目CV![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-5.png)
2. hbase-site.xml 修改
cd /usr/local/hbase/confvim hbase-site.xml
加入:
<property><name>hbase.cluster.distributed</name> <value>true</value>
</property>
<property>
<name>hbase.rootdir</name><value>hdfs://master315:9000/hbase</value>
</property>
<property><name>hbase.zookeeper.quorum</name>
<value>master315,slave01-315,slave02-315</value>
<description>The directory shared by RegionServers. </description>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
</property>
切勿盲目CV,一定看好自己的版本和名字并放到configuration标签之下
请注意:
要用HDFS为Hbase提供存储空间,
定义hbase.rootdir参数时HDFS文件系统的主机名和端口号必须与Hadoop的配置文件core-site.xml中fs.default.name参数的配置一致
3. regionservers 修改
cd /usr/local/hbase/conf/vim regionservers
在master节点加入:
记得删除原本的localhost![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-6.png)
name1
name2
.
.
.
namen
4. backup-masters修改
这个是指出备份主机是谁,我们设为slave01
则编辑加入:cd /usr/local/hbase/conf/vim backup-masters
slave01
根据自己实际情况来看,切勿盲目CV
step4 传递到其他节点
将master节点下配置好的文件全部分发到slave1和slave2节点
命令:
scp -r /usr/local/hbase name1:/usr/local/
scp -r /usr/local/hbase name2:/usr/local/
.
.
.
scp -r /usr/local/hbase namen:/usr/local/
然后将配置好的环境变量的文件~/.bashrc也手动修改或者是传送到其他节点:
scp -r ~/.bashrc name1:~
scp -r ~/.bashrc name2:~
.
.
.
scp -r ~/.bashrc namen:~
记得source一下使其生效
即在各个节点(除了master): source ~/.bashrc
step5 启动备份(可选)
因为这块在后续用不到,所以说可以选择性跳过
cd /usr/local/hbase/bin/
./local-master-backup.sh start 2 3 5
其中2,3,5为偏移量,master其中一个默认端口为16010,那么偏移后就是16012
step6 启动RegionServers(可选)
因为这块在后续用不到,所以说可以选择性跳过
cd /usr/local/hbase/bin/
./local-regionservers.sh start 2 3 5
这里的2,3,5也是偏移量
step7 启动HBase
一定要记住这条常用的命令:
启动HBase集群: start-hbase.sh
关闭HBase集群: stop-hbase.sh
启动后在浏览器查看HBase集群的运行情况:
一定要注意,如果说操作了上面的偏移端口号的操作,要将下面地址的端口号+2master:16010
然后就可以看到:![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-7.png)
![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-8.png)
上图可以看到我们设置的备份主机为slave01
可以缩刷新几下
如果你的这个界面转瞬即逝或者是说昙花一现并出现服务器错误server error500,并且日志文件(/usr/local/hbase/logs下)显示空指针异常的话,肯定是某个配置文件有误(别问,问就是因为这里卡了一晚上,这不得点个赞?)
step8 进入hbase shell
在这一步中,我们需要进入hbase shell 查看具体是否安装完成
在命令行中,我们输入:hbase shell
进入之后,我们打上version查看版本status查看基本状态![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-9.png)
发现一个active master 一个备份master,三个服务器,一个死掉的(博主稍后刷新会恢复,不必在意)
如果说你的status展示没有active master并报错,请检查每部的配置文件是否按照自己的需求和实际情况更改
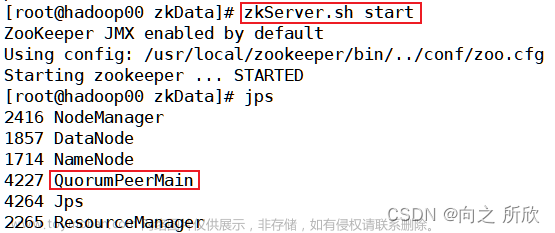
step9 jps进程查看
master:![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-10.png)
slave01:![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-11.png)
slave02:![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-12.png)
到此该有的进程每个节点都有了~
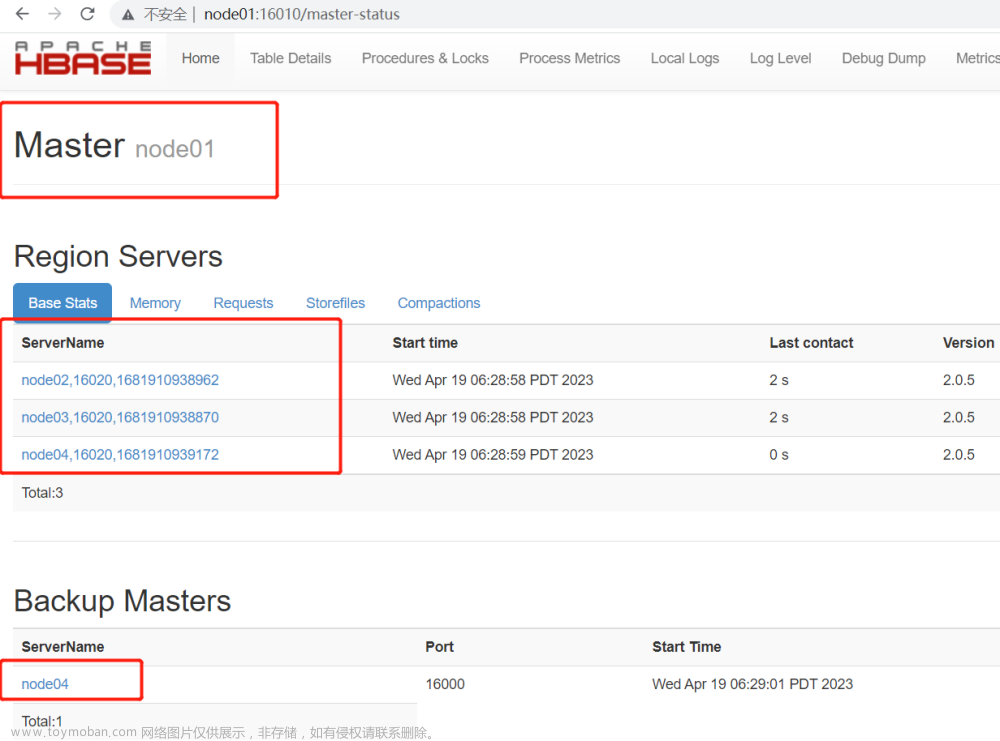
step10 集群测试
在web浏览器输入:master:16010
如果出现:
![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-13.png)
则说明集群配置成功~
HBase完结撒花~文章来源:https://www.toymoban.com/news/detail-423005.html
到此,HBase安装结束
如有问题可以 留言 or 私信 or q_2649432030![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-14.gif)
![HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建](https://imgs.yssmx.com/Uploads/2023/04/423005-15.png) 文章来源地址https://www.toymoban.com/news/detail-423005.html
文章来源地址https://www.toymoban.com/news/detail-423005.html
到了这里,关于HBase集群搭建记录 | 云计算[CentOS7] | HBase完全分布式集群搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![Zookeeper集群搭建记录 | 云计算[CentOS7] | Zookeeper集群搭建](https://imgs.yssmx.com/Uploads/2024/02/428662-1.png)
![Spark集群搭建记录 | 云计算[CentOS7] | Scala Maven项目访问Spark(local模式)实现单词计数](https://imgs.yssmx.com/Uploads/2024/02/451069-1.png)


![云计算集群搭建记录[Hadoop|Zookeeper|Hbase|Spark | Docker |OpenStack]更新索引 |动态更新](https://imgs.yssmx.com/Uploads/2024/01/412630-1.png)