如何使用 Python 爬虫抓取动态网页数据
随着 Web 技术的不断发展,越来越多的网站采用了动态网页技术,这使得传统的静态网页爬虫变得无能为力。本文将介绍如何使用 Python 爬虫抓取动态网页数据,包括分析动态网页、模拟用户行为、使用 Selenium 等技术。
分析动态网页
在进行动态网页爬取之前,我们需要先了解动态网页和静态网页的区别。通常,静态网页的内容是在服务器上生成的,而动态网页的内容是通过 JavaScript 程序在客户端(浏览器)中动态生成的。因此,传统的静态网页爬虫无法获取动态网页中的数据。
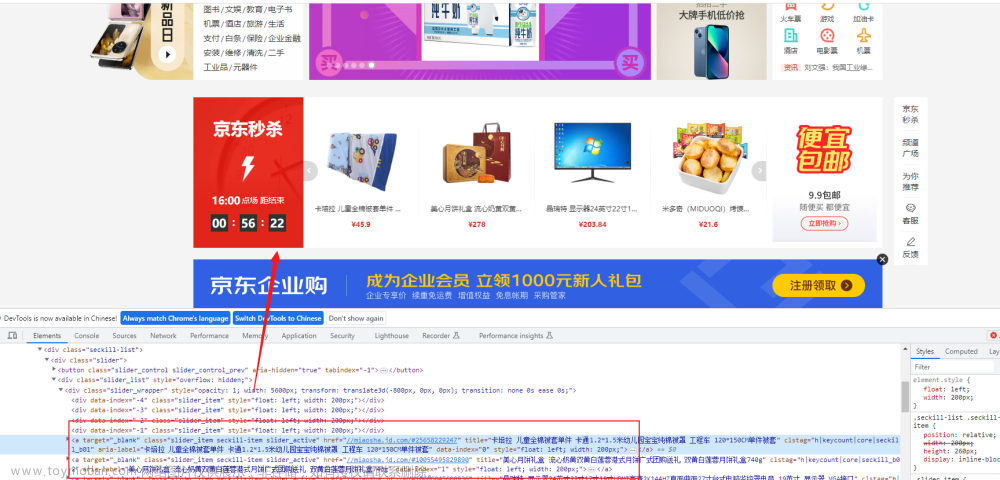
为了获取动态网页中的数据,我们需要先分析动态网页的构成。我们可以通过 Chrome 开发者工具来分析动态网页的结构,其中包括 HTML 代码、CSS 样式和 JavaScript 代码等。在 Chrome 中打开需要爬取的网页,然后按下 F12 键即可打开开发者工具。在开发者工具中,我们可以查看网页的源代码、样式和 JavaScript 程序,从而分析动态网页的结构。
模拟用户行为
在进行动态网页爬取之前,我们还需要模拟用户行为。通常,用户在浏览网页时会进行一些操作,比如点击按钮、输入文本、下拉列表等。这些操作会触发 JavaScript 程序,在客户端中动态生成数据。为了获取动态网页中的数据,我们需要模拟这些用户行为。
我们可以通过抓包工具(如 Wireshark)来获取用户行为信息,然后使用 Requests 库模拟用户行为。Requests 是 Python 中的一个 HTTP 客户端库,它可以向服务器发送 HTTP 请求,并接收服务器的响应。通过使用 Requests 库,我们可以轻松地模拟用户行为,从而获取动态网页中的数据。
使用 Selenium 技术
在某些情况下,使用 Requests 库无法获取动态网页中的数据。这时,我们可以使用 Selenium 技术。Selenium 是一个自动化测试工具,它可以模拟用户在浏览器中的行为,包括点击、输入、滚动等操作。Selenium 还可以将浏览器驱动程序嵌入到 Python 程序中,从而实现自动化网页爬取。
使用 Selenium 进行动态网页爬取的步骤如下:
1.安装 Selenium 和浏览器驱动程序。
2.启动浏览器驱动程序。可以使用 ChromeDriver 或 GeckoDriver 等浏览器驱动程序,具体使用哪种取决于所使用的浏览器。启动浏览器驱动程序的代码如下:
from selenium import webdriver
# 启动 Chrome 浏览器
driver = webdriver.Chrome()
3.打开需要爬取的网页。使用 get() 方法可以打开指定的网页,例如:
# 打开网页
driver.get('https://www.example.com')
4.模拟用户操作。使用 find_element_by_*() 等方法可以定位网页中的元素,并模拟用户操作。例如,使用 find_element_by_id() 方法可以通过元素的 ID 定位元素:
# 定位文本框
input_element = driver.find_element_by_id('q')
# 输入关键字
input_element.send_keys('Python')
5.获取网页源代码。使用 page_source 属性可以获取网页的源代码:
# 获取网页源代码
html = driver.page_source
6.关闭浏览器。使用 quit() 方法可以关闭浏览器:
# 关闭浏览器
driver.quit()
通过上述步骤,我们可以使用 Python 和 Selenium 技术轻松地爬取动态网页中的数据。文章来源:https://www.toymoban.com/news/detail-423161.html
总结
本文介绍了如何使用 Python 爬虫抓取动态网页数据,包括分析动态网页、模拟用户行为、使用 Selenium 等技术。通过本文的介绍,读者可以了解到如何使用 Python 爬虫来获取动态网页中的数据,并可以在实际应用中灵活运用这些技术。文章来源地址https://www.toymoban.com/news/detail-423161.html
到了这里,关于如何使用 Python 爬虫抓取动态网页数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!