📝个人主页:@Sherry的成长之路
🏠学习社区:Sherry的成长之路(个人社区)
📖专栏链接:数据结构
🎯长路漫漫浩浩,万事皆有期待
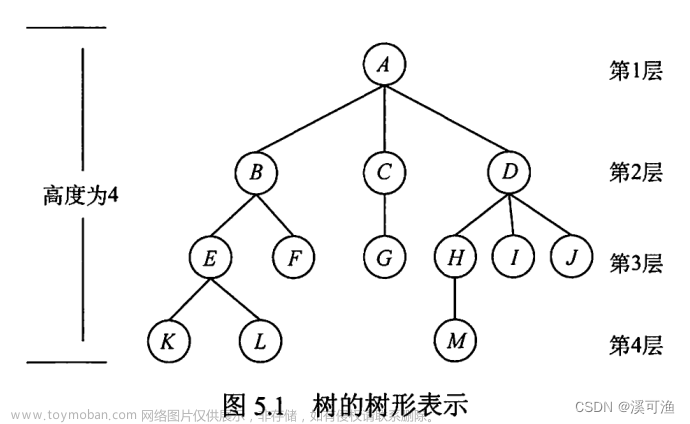
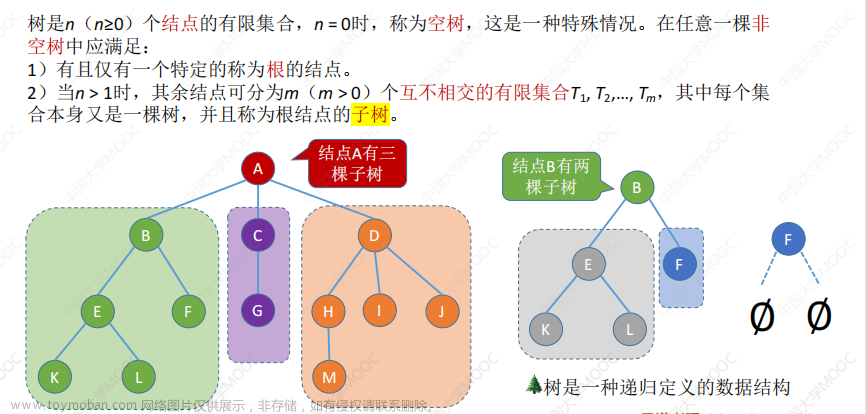
1. 二叉树顺序结构
普通二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储。
注意 操作系统和数据结构中都有栈和堆的概念,这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
2.堆
2.1 堆的概念及结构
2.1.1 概念
堆分为小根堆和大根堆,根节点始终小于子节点称为小根堆,相反根节点始终大于子节点则称为大根堆。换句话说,将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
▶ 大(根)堆,树中所有父亲都大于或者等于孩子,且大堆的根是最大值;
▶ 小(根)堆,树中所有父亲都小于或者等于孩子,且小堆的根是最小值;
2.1.2 堆的性质
▶ 堆中某个节点的值总是不大于或不小于其父节点的值;
▶ 堆总是一棵完全二叉树;
2.2 堆的概念选择题
1、下列关键字序列为堆的是( )
A. 100, 60, 70, 50, 32, 65
B. 60, 70, 65, 50, 32, 100
C. 65, 100, 70, 32, 50, 60
D. 70, 65, 100, 32, 50, 60
E. 32, 50, 100, 70, 65, 60
F. 50, 100, 70, 65, 60, 32
- 分析:根据堆的概念分析,A 选项为大根堆;

2、已知小根堆为 8, 15, 10, 21, 34, 16, 12,删除关键字 8 之后需重建堆,在此过程中,关键字之间的比较次数是( )
A. 1
B. 2
C. 3
D. 4
- 分析:此题考查的是建堆的过程,所以选择 C 选项

3、一组记录排序码为 (5 11 7 2 3 17),则利用堆排序方法建立的初始堆为( )
A. (11 5 7 2 3 17)
B. (11 5 7 2 17 3)
C. (17 11 7 2 3 5)
D. (17 11 7 5 3 2)
E. (17 7 11 3 5 2)
F. (17 7 11 3 2 5)
- 分析:此题考查的是堆排序建堆的过程,根据下面堆排序的过程分析,选择 C 选项

4、、注,请理解下面堆应用的知识再做。最小堆 [0, 3, 2, 5, 7, 4, 6, 8],在删除堆顶元素0之后,其结果是( )
A. [3,2,5,7,4,6,8]
B. [2,3,5,7,4,6,8]
C. [2,3,4,5,7,8,6]
D. [2,3,4,5,6,7,8]
- 分析:此题考查的是 Pop 堆顶后,重新建堆的变化,所以选择 C 选项

2.3 堆的实现
1、堆向下调整算法
向下调整算法有一个前提:左右子树必须是一个堆 (包括大堆和小堆),才能调整。
现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根节点开始的向下调整算法可以把它调整成一个小堆。
1.1 建堆
有一个随机值的数组,把它理解成完全二叉树,并模拟成堆 (大堆/小堆)
int array[] = {27, 15, 19, 18, 28, 34, 65, 49, 25, 37}
观察这组数据
根下面的左右子树都是小根堆,其实堆向下调整算法就是针对这种特殊数据结构
1.1.1针对于这种类型的数据应该怎么调堆
思路:从根开始与左右孩子比较,如果孩子比父亲小,则两两交换位置,再继续往下调,直到左右孩子都比父亲大或者调到叶子
1.1.2 如果不满足左右子树是堆,怎么调整?
int array[] = {27, 37, 28, 18, 19, 34, 65, 25, 49, 15}
根的左右子树 37、28 都不满足:这里的想法就是先让左右子树先满足;而对于左右子树 37、28 来说又需要让 37 先满足;这样依此类推直至满足堆的条件。那干脆就从倒数的第一棵树,也就是倒数的第一个非叶子节点开始调整
关于堆的实现我们使用标准模块化开发格式进行研究:
Heap.h:存放函数声明、包含其他头文件、定义宏。
Heap.c:书写函数定义,书写函数实现。
test.c:书写程序整体执行逻辑。
①.堆的初始化:
堆的初始化与队列相同,首先判断传入指针非空后,将其置空,并将数据置零即可。
//1、对于HeapCreate函数,结构体不是外面传进来的,而是在函数内部自己malloc空间,再创建的
/*
HP* HeapCreate(HPDataType* a, int n)
{}
*/
//2、对于HeapInit函数,在外面定义一个结构体,把结构体的地址传进来
void HeapInit(HP* php, HPDataType* a, int n)
{
assert(php);
//malloc空间(当前数组大小一样的空间)
php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);
if (php->a == NULL)
{
printf("malloc fail\n");
exit(-1);
}
//使用数组初始化
memcpy(php->a, a, sizeof(HPDataType) * n);
php->size = n;
php->capacity = n;
//建堆
int i = 0;
for (i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(php->a, n, i);
}
}
②.堆的插入(向上调整算法):
因为堆的存储在物理层面上数组,但是在逻辑层面上二叉树。并且由于只有小根堆和大根堆,所以在插入数据之后要想保证其仍然是堆,就需要进行适当的调整。
插入时从尾部插入,而是否为堆取决于子节点和父节点的关系,若为小根堆则子节点要比父节点要大,否则就需要交换子节点和父节点,大根堆则相反。而这种调整方式就叫做向上调整算法。
执行操作前需进行非空判断,防止堆空指针进行操作。
插入前判断空间是否足以用于此次扩容,若不足则进行扩容,直至满足插入条件后堪称插入操作,这个接口的功能实现也与队列的处理方式基本相同。
与队列的不同点在于,为了保证插入后仍然是堆,需要在插入后使用向上调整算法进行适当的调整。
//向上调整算法:
//除了child的数据,前面的数构成堆
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
//parent>=0 感觉有问题 但可以使用
{
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//堆插入:
void HeapPush(HP* php, HPDataType x)
{
assert(php);
//空间不够,增容
if (php->size == php->capacity)
{
HPDataType* temp = (HPDataType*)realloc(php->a, php->capacity * 2 * sizeof(HPDataType));
if (temp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
else
{
php->a = temp;
}
php->capacity *= 2;
}
//将x放在最后
php->a[php->size] = x;
php->size++;
//向上调整
AdjustUp(php->a, php->size - 1);
}
③.堆的删除(向下调整算法):
堆删除的实质是删除堆顶元素,如果我们直接删除堆顶的元素,再将数据挪动,就会破坏堆的结构,所以这种方法并不可取;于是我们这里采用将堆顶的数据与最后一个数据交换,再删除最后一个数据的方法,这样就实现了堆顶数据的删除。接着我们再调整一下堆顶数据的位置即可。
在这里选择的调整方法是:将根节点与它的孩子中的较小值交换,然后再将交换后的节点作为父节点继续与它的子节点交换,直到该节点小于它的子节点,或者成为叶节点。
注意 使用这个方法有一个前提:根节点的两个子树也得是堆才行。而这种方法就叫做向下调整算法。
执行操作前需进行非空判断,防止对空指针进行操作。
删除过程同样与队列近乎一致,不同点是在删除过后为了保证删除堆顶数据后仍为堆,于是需要使用向下调整算法对删除后的结果进行适当的处理。
//向下调整算法:
//左右子树都是大堆或小堆
void AdjustDown(HPDataType* arr, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
//选出左右孩子中大的那一个
if (child + 1 < n && arr[child] < arr[child + 1])//防止越界 右孩子存在
//child + 1 < n 放左边 先检查
{
child++;//右孩子>左孩子 ++
}
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else//父亲大于孩子 不用交换了
{
break;
}
}
}
//堆顶数据删除:
void HeapPop(HP* php)
{
assert(php);
//没有数据删除就报错
assert(!HeapEmpty(php));
//交换首尾
Swap(&php->a[0], &php->a[php->size-1]);
php->size--;
//向下调整
AdjustDown(php->a, php->size, 0);
}
HPDataType HeapTop(HP* php)
{
assert(php);
//没有数据获取就报错
assert(!HeapEmpty(php));
return php->a[0];
}
int HeapSize(HP* php)
{
assert(php);
return php->size;
}
测试删除接口功能实现:
④.取堆顶数据:
取堆顶数据操作与队列完全相同
HPDataType HeapTop(HP* php)
{
assert(php);
//没有数据获取就报错
assert(!HeapEmpty(php));
return php->a[0];
}
⑤.堆中数据个数:
查看堆中的数据个数操作很简单,在判断传入指针非空后,直接返回 p->size 的值,即堆中保存的数据数量即可。
int HeapSize(HP* php)
{
assert(php);
return php->size;
}
⑥.堆的判空:
堆的判空操作与队列完全相同
//堆数据判空:
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
⑦.堆的销毁:
堆的销毁与队列相同
void HeapDestroy(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
}
⑦.堆的打印:
void HeapPrint(HP* php)
{
assert(php);
int i = 0;
for (i = 0; i < php->size; i++)
{
printf("%d ", php->a[i]);
}
printf("\n");
}
2.4 堆的代码实现
注意
▶ 堆的初始化一般是使用数组进行初始化的
▶ 堆的插入数据不分头插、尾插,将数据插入后,原来堆的属性不变
先放在数组的最后一个位置,再向上调整
▶ 堆的删除数据删除的是堆顶的数据,将数据删除后,原来堆的属性不变
为了效率,将第一个和最后一个元素交换,再减容,然后再调整
Heap.h 用于函数的声明
#pragma once
//头
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<string.h>
#include<stdbool.h>
typedef int HPDataType;
//C++ -> priority_queue 在C++里用的是优先级队列,其底层就是一个堆
//大堆
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;
//函数的声明
//交换
void Swap(HPDataType* px, HPDataType* py);
//向下调整
void AdjustDown(HPDataType* arr, int n, int parent);
//向上调整
void AdjustUp(HPDataType* a, int child);
//使用数组进行初始化
void HeapInit(HP* php, HPDataType* a, int n);
//回收空间
void HeapDestroy(HP* php);
//插入x,保持它继续是堆
void HeapPush(HP* php, HPDataType x);
//删除堆顶的数据,保持它继续是堆
void HeapPop(HP* php);
//获取堆顶的数据,也就是最值
HPDataType HeapTop(HP* php);
//判空
bool HeapEmpty(HP* php);
//堆的数据个数
int HeapSize(HP* php);
//输出
void HeapPrint(HP* php);
Heap.c 用于函数的定义
#include"Heap.h"
void Swap(HPDataType* px, HPDataType* py)
{
HPDataType temp = *px;
*px = *py;
*py = temp;
}
//左右子树都是大堆或小堆
void AdjustDown(HPDataType* arr, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
//选出左右孩子中大的那一个
if (child + 1 < n && arr[child] < arr[child + 1])//防止越界 右孩子存在
//child + 1 < n 放左边 先检查
{
child++;//右孩子>左孩子 ++
}
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else//父亲大于孩子 不用交换了
{
break;
}
}
}
//除了child的数据,前面的数构成堆
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
//parent>=0 感觉有问题 但可以使用
{
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void HeapPrint(HP* php)
{
assert(php);
int i = 0;
for (i = 0; i < php->size; i++)
{
printf("%d ", php->a[i]);
}
printf("\n");
}
//1、对于HeapCreate函数,结构体不是外面传进来的,而是在函数内部自己malloc空间,再创建的
/*
HP* HeapCreate(HPDataType* a, int n)
{}
*/
//2、对于HeapInit函数,在外面定义一个结构体,把结构体的地址传进来
void HeapInit(HP* php, HPDataType* a, int n)
{
assert(php);
//malloc空间(当前数组大小一样的空间)
php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);
if (php->a == NULL)
{
printf("malloc fail\n");
exit(-1);
}
//使用数组初始化
memcpy(php->a, a, sizeof(HPDataType) * n);
php->size = n;
php->capacity = n;
//建堆
int i = 0;
for (i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(php->a, n, i);
}
}
void HeapDestroy(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
}
bool HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
void HeapPush(HP* php, HPDataType x)
{
assert(php);
//空间不够,增容
if (php->size == php->capacity)
{
HPDataType* temp = (HPDataType*)realloc(php->a, php->capacity * 2 * sizeof(HPDataType));
if (temp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
else
{
php->a = temp;
}
php->capacity *= 2;
}
//将x放在最后
php->a[php->size] = x;
php->size++;
//向上调整
AdjustUp(php->a, php->size - 1);
}
void HeapPop(HP* php)
{
assert(php);
//没有数据删除就报错
assert(!HeapEmpty(php));
//交换首尾
Swap(&php->a[0], &php->a[php->size-1]);
php->size--;
//向下调整
AdjustDown(php->a, php->size, 0);
}
HPDataType HeapTop(HP* php)
{
assert(php);
//没有数据获取就报错
assert(!HeapEmpty(php));
return php->a[0];
}
int HeapSize(HP* php)
{
assert(php);
return php->size;
}
Test.c 用于测试函数
#include"Heap.h"
void TestHeap()
{
int arr[] = { 27, 37, 28, 18, 19, 34, 65, 25, 49, 15 };
HP hp;
HeapInit(&hp, arr, sizeof(arr)/sizeof(arr[0]));
HeapPrint(&hp);
HeapPush(&hp, 18);
HeapPrint(&hp);
HeapPush(&hp, 98);
HeapPrint(&hp);
printf("\n\n");
//将堆这数据结构实现好后,我们就可以利用这些接口实现排序
while(!HeapEmpty(&hp))
{
printf("%d ", HeapTop(&hp));
HeapPop(&hp);
}
printf("\n");
}
int main()
{
TestHeap();
return 0;
}
3.总结:
今天我们认识并学习了二叉树顺序结构的相关概念,并且对堆的概念及结构也有了一定的了解。还对二叉树顺序存储的实例——堆的各接口功能进行了实现。下一篇博客我们将从堆的时间复杂度详解以及堆的应用—堆排序、TOP - K问题进一步介绍堆。希望我的文章和讲解能对大家的学习提供一些帮助。
当然,本文仍有许多不足之处,欢迎各位小伙伴们随时私信交流、批评指正!我们下期见~文章来源:https://www.toymoban.com/news/detail-423240.html
 文章来源地址https://www.toymoban.com/news/detail-423240.html
文章来源地址https://www.toymoban.com/news/detail-423240.html
到了这里,关于【树与二叉树】二叉树顺序结构实现以及堆的概念及结构--详解介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!