实时同步是 ChunJun 的⼀个重要特性,指在数据同步过程中,数据源与⽬标系统之间的数据传输和更新⼏乎在同⼀时间进⾏。
在实时同步场景中我们更加关注源端,当源系统中的数据发⽣变化时,这些变化会⽴即传输并应⽤到⽬标系统,以保证两个系统中的数据保持⼀致。这个特性需要作业运⾏过程中 source 插件不间断地频繁访问源端。在⽣产场景下,对于这类⻓时间运⾏、资源可预估、需要稳定性的作业,我们推荐使⽤ perjob 模式部署。
插件⽀持 JSON 脚本和 SQL 脚本两种配置⽅式,具体的参数配置请参考「ChunJun连接器文档」:https://sourl.cn/vxq6Zp
本文将为大家介绍如何使用 ChunJun 实时同步,以及 ChunJun ⽀持的 RDB 实时采集插件的特性、采集逻辑及其原理,帮助大家更好地理解 ChunJun 与实时同步。
如何使用 ChunJun 实时同步
为了让⼤家能更深⼊了解如何使⽤ ChunJun 做实时同步,我们假设有这样⼀个场景:⼀个电商⽹站希望将其订单数据从 MySQL 数据库实时同步到 HBase 数据库,以便于后续的数据分析和处理。
在这个场景中,我们将使⽤ Kafka 作为中间消息队列,以实现 MySQL 和 HBase 之间的数据同步。这样做的好处是 MySQL 表中变更可以实时同步到 HBase 结果表中,⽽不⽤担⼼历史数据被修改后 HBase 表未被同步。
如果在⼤家的实际应用场景中,不关⼼历史数据是否变更(或者历史数据根本不会变更),且业务表有⼀个递增的主键,那么可以参考本⽂之后的 JDBC-Polling 模式⼀节的内容。
· 数据源组件的部署以及 ChunJun 的部署这⾥不做详细描述
· 案例中的脚本均以 SQL 脚本为例,JSON 脚本也能实现相同功能,但在参数名上可能存在出⼊,使⽤ JSON 的同学可以参考上文 「ChunJun 连接器」⽂档中的参数介绍
采集 MySQL 数据到 Kafka
● 数据准备
⾸先,我们在 Kafka 中创建⼀个名为 order_dml 的 topic,然后在 MySQL 中创建⼀个订单表,并插⼊⼀些测试数据。创建表的 SQL 语句如下:
-- 创建⼀个名为ecommerce_db的数据库,⽤于存储电商⽹站的数据
CREATE DATABASE IF NOT EXISTS ecommerce_db;
USE ecommerce_db;
-- 创建⼀个名为orders的表,⽤于存储订单信息
CREATE TABLE IF NOT EXISTS orders (
id INT AUTO_INCREMENT PRIMARY KEY, -- ⾃增主键
order_id VARCHAR(50) NOT NULL, -- 订单编号,不能为空
user_id INT NOT NULL, -- ⽤户ID,不能为空
product_id INT NOT NULL, -- 产品ID,不能为空
quantity INT NOT NULL, -- 订购数量,不能为空
order_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP -- 订单⽇期,默认值为当前时间
戳,不能为空
);
-- 插⼊⼀些测试数据到orders表
INSERT INTO orders (order_id, user_id, product_id, quantity)
VALUES ('ORD123', 1, 101, 2),
('ORD124', 2, 102, 1),
('ORD125', 3, 103, 3),
('ORD126', 1, 104, 1),
('ORD127', 2, 105, 5);
● 使用 Binlog 插件采集数据到 Kafka
为了表示数据的变化类型和更好地处理数据变化,实时采集插件一般会用 RowData(Flink 内部数据结构)中的 RowKind 记录⽇志中的数据事件(insert、delete 等)类型,binlog 插件也⼀样。而当数据被打到 Kafka 中时,RowKind 信息应该怎么处理呢?
这⾥我们就需要⽤到 upsert-kafka-x,upsert-kafka-x 会识别 RowKind。对各类时间的处理逻辑如下:
• insert 数据:序列化后直接打⼊
• delete 数据:只写 key,value 置为 null
• update 数据:分为⼀条 delete 数据和 insert 数据处理,即先根据主键删除原本的数据,再写⼊ update 后的数据
在下⼀步中我们再解释如何将 Kafka 中的数据还原到 HBase 或者其他⽀持 upsert 语义的数据库中,接下来我们来编写 SQL 脚本,实现 MySQL 数据实时采集到 Kafka 中的功能,示例如下:
CREATE TABLE binlog_source (
id int,
order_id STRING,
user_id INT,
product_id int,
quantity int,
order_date TIMESTAMP(3)
) WITH (
'connector' = 'binlog-x',
'username' = 'root',
'password' = 'root',
'cat' = 'insert,delete,update',
'url' = 'jdbc:mysql://localhost:3306/ecommerce_db?useSSL=false',
'host' = 'localhost',
'port' = '3306',
'table' = 'ecommerce_db.orders',
'timestamp-format.standard' = 'SQL',
'scan.parallelism' = '1'
);
CREATE TABLE kafka_sink (
id int,
order_id STRING,
user_id INT,
product_id int,
quantity int,
order_date TIMESTAMP(3),PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka-x',
'topic' = 'orders',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'json',
'value.format' = 'json',
'value.fields-include' = 'ALL',
'sink.parallelism' = '1'
);
insert into
kafka_sink
select
*
from
binlog_source u;
还原 Kafka 中的数据到 HBase
上述步骤中,我们通过 binlog-x 和 upsert-kafka-x,将 MySQL 中的数据实时采集到了 Kafka 中。解铃还须系铃⼈,我们可以通过 upsert-kafka-x 再去将 Kafka 中的数据解析成带有 upsert 语义的数据。
upsert-kafka-x 作为 source 插件时,会判断 Kafka 中数据的 value 是否为 null,如果 value 为 null 则标记这条数据的 RowKind 为 DELETE,否则将数据的 ROWKIND 标记为 INSERT。
ChunJun的 hbase-x 插件⽬前已经具备了 upsert 语句的能⼒,使⽤ hbase-x 即可将 Kafka 中的数据还原到 hbase中。接下来是 SQL 脚本示例,为了⽅便在 HBase 中查看数据结果,我们将 int 数据 cast 为 string 类型:
CREATE TABLE kafka_source (
id int,
order_id STRING,
user_id INT,
product_id INT,
quantity INT,
order_date TIMESTAMP(3),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka-x',
'topic' = 'orders',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'test_group',
'key.format' = 'json',
'value.format' = 'json',
'scan.parallelism' = '1'
);
CREATE TABLE hbase_sink(
rowkey STRING, order_info ROW < order_id STRING,
user_id STRING,
product_id STRING,
quantity STRING,
order_date STRING >,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH(
-- 这⾥以hbase14为例,如果hbase版本是2.x,我们可以使⽤hbase2-x插件代替
'connector' = 'hbase14-x',
'zookeeper.quorum' = 'localhost:2181',
'zookeeper.znode.parent' = '/hbase',
'table-name' = 'ecommerce_db:orders',
'sink.parallelism' = '1'
);
INSERT INTO
hbase_sink
SELECT
cast(id as STRING),
ROW(
cast(order_id as STRING),
cast(user_id as STRING),
cast(product_id as STRING),
cast(quantity as STRING),
cast(order_date as STRING)
)
FROM
kafka_source
Tips:如果我们不需要 Kafka 中间件,也可以使⽤ binlog-x 插件直接对接 hbase-x 插件。
ChunJun 支持的 RDB 实时采集插件
本节主要介绍 ChunJun 的 RDB 实时采集插件的特性、采集逻辑及其原理。
ChunJun 的 RDB 实时采集可以实时监视数据库中的更改,并在发⽣更改时读取数据变化,例如插⼊、更新和删除操作。使⽤ ChunJun 实时采集,我们可以实时获取有关数据库中更改的信息,从⽽能够及时响应这些更改,如此便可以帮助我们更好地管理和利⽤ RDB 数据库中的数据。
并且 ChunJun 提供了故障恢复和断点续传功能来确保数据的完整性。ChunJun 实时采集类插件的⼤致实现步骤如下:
· 连接数据库,确认读取点位,读取点位可以理解为⼀个 offset,如 Binlog 中,指⽇志的⽂件名和⽂件的 position 信息
· 根据读取点位开始读取 redolog,获取其中关于数据变更相关的操作记录
· 根据 tableName、操作事件(如insert、delete、update)等过滤信息过滤出需要的 log ⽇志
· 解析 log ⽇志,解析后的事件信息包括表名、数据库名、操作类型(插⼊、更新或删除)和变更的数据⾏等
· 将解析出来的数据会加⼯为 ChunJun 内部统⼀的 DdlRowData 供下游使⽤
ChunJun ⽬前已⽀持的实时采集 Connector 有:binlog(mysql)、oceanbasecdc、oraclelogminer、sqlservercdc。
Binlog 简介
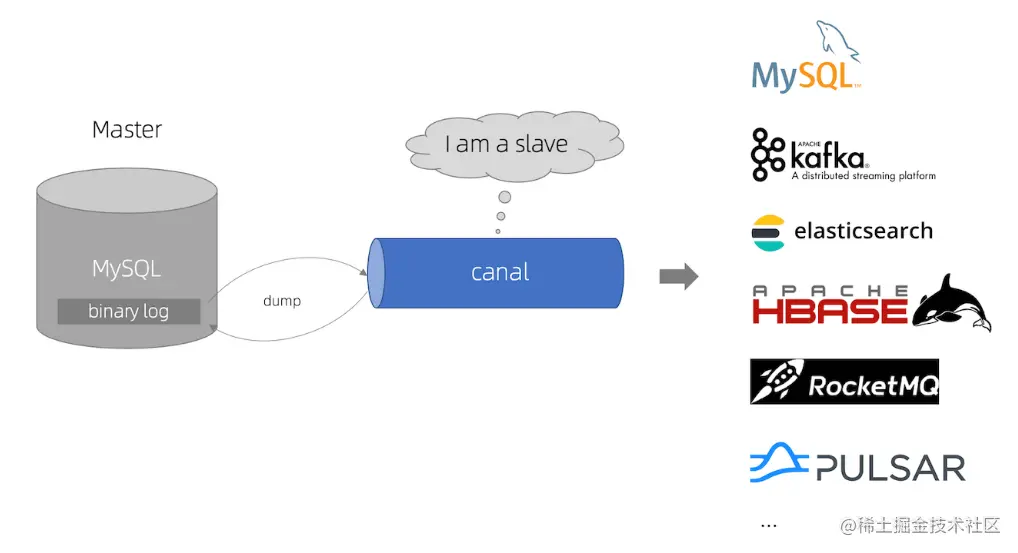
ChunJun binlog 插件的主要功能是读取 MySQL 的⼆进制⽇志(binlog)⽂件。这些⽂件记录了所有对数据的更改操作,如插⼊、更新和删除等。⽬前,该插件依赖 Canal 组件来读取 MySQL 的 binlog ⽂件。
核⼼操作步骤如下:
• 确认读取点位:在 binlog 插件中,我们可以在脚本的 start 字段中直接指定 journal-name(binlog ⽂件名)和 position(⽂件的特定位置)
• 读取binlog:binlog 插件将⾃身伪装成 MySQL 的 Slave 节点,向 MySQL Master 发送请求,要求将 binlog ⽂件的数据流发送给它
• 故障恢复和断点续传:故障时,插件会记录当前的 binlog 位置信息,从 checkpoint/savepoint 恢复后,我们可以从上次记录的位置继续读取 binlog ⽂件,确保数据变化的完整性
使⽤ binlog 所需的权限在「binlog插件使⽤⽂档」中有详细说明,链接如下:
https://sourl.cn/mvae9m
OracleLogminer 简介
Logminer 插件借助 Oracle 提供的 Logminer ⼯具通过读取视图的⽅式获取 Oracle redolog 中的信息。
核⼼操作步骤如下:
01 定位需读取起始点位(start_scn)
⽬前 logminer ⽀持四种策略指定 StartScn:
· all:从 Oracle 数据库中最早的归档⽇志组开始采集(不建议使⽤)
· current:任务运⾏时的 SCN 号
· time:指定时间点对应的 SCN 号
· scn:直接指定 SCN 号
02 定位需要读取的结束点位(end_scn)
插件根据 start_scn 和 maxLogFileSize(默认5G)获取可加载的 redolog ⽂件列表,end_scn 取这个⽂件列表中最⼤的 scn 值。
03 加载 redo ⽇志到 Logminer
通过⼀个存储过程,将 scn 区间范围内的 redolog 加载到 Logminer ⾥。
04 从视图中读取数据
以 scn > ? 作为 where 条件直接查询 v$logmnr_contents 视图内的信息即可获取 redolog 中的数据。
05 重复1-4步骤,实现不断的读取
如标题。
06 故障恢复和断点续传
在发⽣故障时,插件会保存当前消费的 scn 号,重启时从上次的 scn 号开始读取,确保数据完整性。
• 关于该插件原理的详细介绍请参⻅「Oracle Logminer 实现原理说明⽂档」:
https://sourl.cn/6vqz4b
• 使⽤lominer插件的前提条件详⻅「Oracle配置LogMiner」:
https://sourl.cn/eteyZY
SqlServerCDC 简介
SqlServerCDC 插件依赖 SQL Server 的 CDC Agent 服务提供的视图获取 redolog 中的信息。
核⼼操作步骤如下:
01 定位需读取起始点位(from_lsn)
⽬前 SqlserverCDC 仅⽀持直接配置 lsn 号,如果 lsn 号未配置,则取数据库中当前最⼤的 lsn 号为 from_lsn。
02 定位需要读取的结束点位(to_lsn)
SqlserverCDC 插件定期地(可通过 pollInterval 参数指定)获取数据库中的最⼤ lsn 为 end_lsn。
03 从视图中读取数据
查询 Agent 服务提供的视图中 lsn 区间范围内的数据,过滤出需要监听的表及事件类型。
04 重复1-3步骤,实现不断的读取
如标题。
05 故障恢复和断点续传
在发⽣故障时,插件会保存当前消费的 lsn 号。重启时从上次的 lsn 号开始读取,确保数据完整性。
• 关于该插件原理的详细介绍请参⻅「Sqlserver CDC 实现原理说明⽂档」:
https://sourl.cn/5pQvEM
• 配置 SqlServer CDC Agent 服务详⻅「Sqlserver 配置 CDC ⽂档」:
https://sourl.cn/h5nd8j
OceanBaseCDC 简介
OceanBase 是蚂蚁集团开源的⼀款分布式关系型数据库,它使⽤⼆进制⽇志(binlog)记录数据变更。OceanBaseCDC 的实现依赖于 OceanBase 提供的 LogProxy 服务,LogProxy 提供了基于发布-订阅模型的服务,允许使⽤ OceanBase 的 logclient 订阅特定的 binlog 数据流。
OceanBaseCDC 启动⼀个 Listener 线程。当 logclient 连接到 LogProxy 后,Listener 会订阅经过数据过滤的 binlog,然后将其添加到内部维护的列表中。当收到 COMMIT 信息后,Listener 会将⽇志变更信息传递给⼀个阻塞队列,由主线程消费并将其转换为 ChunJun 内部的 DdlRowData,最终发送到下游。
JDBC-Polling 模式读
JDBC 插件的 polling 读取模式是基于 SQL 语句做数据读取的,相对于基于重做⽇志的实时采集成本更低,但 jdbc 插件做实时同步对业务场景有更⾼的要求:
· 有⼀个数值类型或者时间类型的递增主键
· 不更新历史数据或者不关⼼历史数据是否更新,仅关⼼新数据的获取
实现原理简介
• 设置递增的业务主键作为 polling 模式依赖的增量键
• 在增量读取的过程中,实时记录 increColumn 对应的值(state),作为下⼀次数据读取的起始点位
• 当⼀批数据读取完后,间隔⼀段时间之后依据 state 读取下⼀批数据
polling 依赖部分增量同步的逻辑,关于增量同步的更多介绍可以点击:
https://sourl.cn/UC8n6K
如何配置⼀个 jdbc-polling 作业
先介绍⼀下开启 polling 模式需要关注的配置项:

以 MySQL 为例,假设我们有⼀个存储订单信息的历史表,且订单的 order_id 是递增的,我们希望定期地获取这张表的新增数据。
CREATE TABLE order.realtime_order_archive (
order_id INT PRIMARY KEY COMMENT '订单唯⼀标识',
customer_id INT COMMENT '客户唯⼀标识',
product_id INT COMMENT '产品唯⼀标识',
order_date TIMESTAMP COMMENT '订单⽇期和时间',
payment_method VARCHAR(255) COMMENT '⽀付⽅式(信⽤卡、⽀付宝、微信⽀付等)',
shipping_method VARCHAR(255) COMMENT '配送⽅式(顺丰速运、圆通速递等)',
shipping_address VARCHAR(255) COMMENT '配送地址',
order_total DECIMAL(10,2) COMMENT '订单总⾦额',
discount DECIMAL(10,2) COMMENT '折扣⾦额',
order_status VARCHAR(255) COMMENT '订单状态(已完成、已取消等)'
);
我们可以这样配置 json 脚本的 reader 信息。
"name": "mysqlreader",
"parameter": {
"column" : [
"*" //这⾥假设我们读取所有字段,可以填写‘*’
],
"increColumn": "id",
"polling": true,
"pollingInterval": 3000,
"username": "username",
"password": "password",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://ip:3306/liuliu?useSSL=false"
],
"schema":"order",
"table": [
"realtime_order_archive" ]
}
]
}
}
《数栈产品白皮书》:https://fs80.cn/cw0iw1
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky文章来源:https://www.toymoban.com/news/detail-423678.html
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack文章来源地址https://www.toymoban.com/news/detail-423678.html
到了这里,关于技术干货|如何利用 ChunJun 实现数据实时同步?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!