实验报告
实 验(三)
题 目 优化
专 业 人工智能(未来技术)
学 号 7203610716
班 级 20WJ102
学 生 孙铭蔚
指 导 教 师 刘宏伟
实 验 地 点 G712
实 验 日 期 2022.04.16
计算学部
目 录
第1章 实验基本信息....................................... - 3 -
1.1 实验目的................................................... - 3 -
1.2 实验环境与工具............................................. - 3 -
1.2.1 硬件环境............................................... - 3 -
1.2.2 软件环境............................................... - 3 -
1.2.3 开发工具............................................... - 3 -
1.3 实验预习................................................... - 3 -
第2章 实验预习........................................... - 4 -
2.1 程序优化的十大方法(5分).................................. - 4 -
2.2性能优化的方法概述(5分).................................. - 4 -
2.3 Linux下性能测试的方法(5分)............................... - 4 -
2.4 Windows下性能测试的方法(5分).............................. - 4 -
第3章 性能优化的方法..................................... - 5 -
第4章 性能优化实践....................................... - 7 -
第5章 总结.............................................. - 8 -
5.1 请总结本次实验的收获....................................... - 8 -
5.2 请给出对本次实验内容的建议................................. - 8 -
参考文献................................................. - 9 -
第1章 实验基本信息
1.1 实验目的
-
- 理解程序优化的10个维度
- 熟练利用工具进行程序的性能评价、瓶颈定位
- 掌握多种程序性能优化的方法
- 熟练应用软件、硬件等底层技术优化程序性能
1.2 实验环境与工具
1.2.1 硬件环境
硬件1概览:
型号名称: MacBook Air
型号标识符: MacBookAir10,1
芯片: Apple M1
核总数: 8(4性能和4能效)
内存: 8 GB
系统固件版本: 7429.81.3
操作系统加载程序版本: 7429.81.3
序列号(系统): C02H479LQ6L5
硬件UUID: B9297F28-81B7-5DB0-8760-89063F63E0E5
预置UDID: 00008103-001205960108801E
激活锁状态: 已启用
硬件2概览:
64 位操作系统, 基于 x64 的处理器
AMD Ryzen 7 4800H with Radeon Graphics 2.90 GHz
LAPTOP-CSSCDDGT
1.2.2 软件环境
Windows下Visual Studio 2020以上64位
Windows下Perf、VS的性能探测器
Ubuntu下oprofiler、gprof
1.2.3 开发工具
Visual Studio 2022 64位;vs code 64位
1.3 实验预习
了解实验的目的、实验环境与软硬件工具、实验操作步骤,复习与实验有关的理论知识。性能测试准确性的文献查找,我了解到,流水线、超线程、超标量、向量、多核、GPU、多级CACHE、编译优化Ox、多进程、多线程等多种因素对程序性能均有综合影响。
第2章 实验预习
总分20分
2.1 程序优化的十大方法(5分)
- 优化性能
- 减少空间占用,减少运行内存
- 美化UI界面
- 更加正确
- 增加程序可靠性
- 增加可移植性
- 有更强大功能
- 使用方便
- 更加符合编程规范和接口规范
- 更加易懂,加注释、模块化
2.2性能优化的方法概述(5分)
1.一般有用的优化
2.面向编译器的优化
3.面向超标量CPU的优化
4.面向向量CPU的优化
5. CMOVxx等指令
6. 嵌入式汇编
7.面向编译器的优化
8.面向存储器的优化:
9.内存作为逻辑磁盘
10.多进程优化
11.文件访问优化:带Cache的文件访问
12.并行计算:多线程优化
13.网络计算优化
14.GPU编程、算法优化
15.超级计算
2.3 Linux下性能测试的方法(5分)
- linux下使用Oprofile等工具
- 使用自己构造的函数测出程序运行时间,进而测试性能
2.4 Windows下性能测试的方法(5分)
1.在visual studio中使用调试工具:性能探测器:CPU、RAM、GPU
2.使用自己构造的函数测出程序运行时间,进而测试性能
第3章 性能优化的方法
总分20分
逐条论述性能优化方法名称、原理、实现方案(至少10条)
3.1
1.一般有用的优化
代码移动
复杂指令简化
公共子表达式
2.面向编译器的优化:障碍
函数副作用
内存别名
3.面向超标量CPU的优化
流水线、超线程、多功能部件、分支预测投机执行、乱序执行、多核:分离的循环展开!
只有保持能够执行该操作的所有功能单元的流水线都是满的,程序才能达到这个操作的吞吐量界限
4.面向向量CPU的优化:MMX/SSE/AVR
5. CMOVxx等指令
代替test/cmp+jxx
6. 嵌入式汇编
7.面向编译器的优化
Ox:0 1 2 3 g
8.面向存储器的优化:Cache无处不在
重新排列提高空间局部性
分块提高时间局部性
9.内存作为逻辑磁盘:内存够用的前提下。
10.多进程优化
fork,每个进程负责各自的工作任务,通过mmap共享内存或磁盘等进行交互。
11.文件访问优化:带Cache的文件访问
12.并行计算:多线程优化:第12章
13.网络计算优化:第11章、分布式计算、云计算
14.GPU编程、算法优化
15.超级计算
第4章 性能优化实践
总分60分
4.1 原始程序及说明(10分)
void putong(long img[1922][1082])
{
for(int j = 1; j < 1081; j++)
{
for (int i = 1; i < 1921;i++)
{
/* code */
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) / 4;
}
}
}程序的功能:
源程序功能是对给定的数组模拟图像平滑算法,对数组的值进行更改
流程:任一点的颜色值为其上下左右4个点颜色的平均值,即:img[i][j] = ( img[i-1][j] + img[i+1][j] +img[i][j-1] + img[i][j+1] ) /4。
程序可能瓶颈:
1、这个程序不符合空间局部性
2、这个程序使用了占用时钟周期较长的除法
3、这个程序没有充分利用CPU,即流水线不是总处于满的状态,具有数据相关性。由于循环减少了分支预测失败的可能性,同时增加了循环体内语句并发执行的可能性,我们考虑使用循环展开对代码优化。
4.2 优化后的程序及说明(20分)
至少包含面向CPU、Cache的两种优化策略(20分),额外每增加1种优化方法加5分至第4章满分。
面向CPU(循环展开):
void cpu(long img[1922][1082])//循环展开
{
int i;
long bef1,aft1,bef2,aft2;
long B[1082];
for (i = 0;i < 1082;i++) {
B[i] = img[0][i];
}
for(int j=1;j<1080;j+=8)
{
for(int i=1;i<1921;i++)
{
bef1=img[i][j+1];
aft1=img[i][j+2];
bef2=img[i][j+5];
aft2=img[i][j+6];
img[i][j]=(B[j]+img[i+1][j]+img[i][j-1]+bef1)/4;
img[i][j+1]=(B[j+1]+img[i+1][j+1]+aft1+img[i][j])/4;
img[i][j+2]=(B[j+2]+img[i+1][j+2]+bef1+img[i][j+3])/4;
img[i][j+3]=(B[j+3]+img[i+1][j+3]+aft1+img[i][j+4])/4;
img[i][j+4]=(B[j+4]+img[i+1][j+4]+img[i][j+3]+bef2)/4;
img[i][j+5]=(B[j+5]+img[i+1][j+5]+aft2+img[i][j+4])/4;
img[i][j+6]=(B[j+6]+img[i+1][j+6]+bef2+img[i][j+7])/4;
img[i][j+7]=(B[j+7]+img[i+1][j+7]+aft2+img[i][j+8])/4;
B[j] = img[i][j];
B[j + 1] = img[i][j+1];
B[j + 2] = img[i][j+2];
B[j + 3] = img[i][j+3];
B[j+4] = img[i][j+4];
B[j + 5] = img[i][j+5];
B[j + 6] = img[i][j+6];
B[j + 7] = img[i][j+7];
}
}
}说明:
显然流水线只要流起来可以大大提高CPU的工作效率,我们在循环的时候,每次可以使用更多变量参与运算,能使流水线更好地流。于是。我首先讲边缘数据存储到数组B中。在主循环中,我设置的步长为8,我定义4个变量aft1和bef1,aft2和bef2,分别存储8个原数据的第3、2、7、6个,每次循环更新img数组后,更新B数组。
这样可以使硬件能让流水线很好地运作,即使在少数情况下也只牺牲一点效率。
面向Cache1(符合空间局部性):
void cache(long img[1922][1082])
{
for(int i = 1; i < 1921;i++)
{
for (int j = 1; j < 1081; j++)
{
/* code */
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) /4;
}
}
}说明:
由于数组在电脑中按行进行存储,根据上课讲过的命中和不命中的知识,通过书中知识可以知道,对于数组来说,一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,这是因为指令通常是顺序存放、顺序执行的,数据也一般是以向量、数组、表等形式簇聚存储的。如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。如果其访问顺序和存储顺序一致,程序性能会提升很多。
面向Cache2(按行进行分块):
void fenkuai_cpu_row(long img[1922][1082])
{
int i, j, k, kk=4, jj=4;
int bsize = 4;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int en = 1921; /* Amount that fits evenly into blocks */
for (jj = 1; jj < en; jj += bsize)
{
for (i = jj; i < jj + bsize; i++)
{
for (j = 1; j < 1081; j++)
{
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) / 4;
}
}
}
}说明:
根据csapp中所述,有一种有趣的技术叫做分块,它可以改善内部循环的时间局部性。分块的一般思想是将程序中的数据结构组织成称为块的大块。(在这里,“块”指的是应用程序级的数据块,而不是缓存块。)程序是结构化的,它将一个数据块加载到L1缓存中,对该数据块执行所有需要的读写操作,然后丢弃该数据块,加载下一个数据块,以此类推。与用于改进空间局部性的简单循环转换不同,阻塞使代码更难阅读和理解。由于这个原因,它最适合优化编译器或频繁执行的库例程。利用上述原理,我将数据按列分块,我默认一个块中有4个数据,进行试验后发现性能提升不少。
面向Cache3(按列进行分块):
void fenkuai_cpu_col(long img[1922][1082])
{
int i, j, k, kk=4, jj=4;
int bsize = 4;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int en = 1081; /* Amount that fits evenly into blocks */
for (jj = 1; jj < en; jj += bsize)
{
for (i = 1; i < 1921; i++)
{
for (j = jj; j < jj + bsize; j++)
{
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) / 4;
}
}
}
}
说明:
根据csapp中所述,有一种有趣的技术叫做分块,它可以改善内部循环的时间局部性。分块的一般思想是将程序中的数据结构组织成称为块的大块。(在这里,“块”指的是应用程序级的数据块,而不是缓存块。)程序是结构化的,它将一个数据块加载到L1缓存中,对该数据块执行所有需要的读写操作,然后丢弃该数据块,加载下一个数据块,以此类推。与用于改进空间局部性的简单循环转换不同,阻塞使代码更难阅读和理解。由于这个原因,它最适合优化编译器或频繁执行的库例程。利用上述原理,我将数据按列分块,我默认一个块中有4个数据,进行试验后发现性能提升不少。
面向Cache4(按正方形进行分块):
void fenkuai_cpu_row4(long img[1922][1082])
{
int i, j, k, kk = 4, jj = 4;
int bsize = 4;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int M = 1081, N = 1921;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int en = 1921; /* Amount that fits evenly into blocks */
for (int ii = 1; ii < N; ii += bsize)
{
for (int jj = 1; jj < M; jj += bsize)
{
for (int i = ii; i < ((ii + bsize) > N ? N : ii + bsize); i++)
{
for (int j = jj; j < ((jj + bsize) > M ? M : jj + bsize); j++)
{
img[i][j] = (img[i - 1][j] + img[i + 1][j] + img[i][j - 1] + img[i][j + 1]) / 4;
}
}
}
}
}
一般的优化方法(除法变成移位操作):
void cache1(long img[1922][1082])
{
for(int j = 1; j < 1081; j++)
{
for (int i = 1; i < 1921;i++)
{
/* code */
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) >> 2;
}
}
}
说明:
由于从效率上看,使用移位指令有更高的效率,因为移位指令占2个机器周期,而乘除法指令占4个机器周期。从硬件上看,移位对硬件更容易实现,所以会用移位,左移一位就乘2,右移一位处以2,这种乘除法考虑移位实现会更快。
整合所有方法:
void success(long img[1922][1082])
{
int i;
long bef,aft;
long B[1082];
for (i = 0;i < 1082;i++) {
B[i] = img[0][i];//存储边界值
}
for(int i=1;i<1921;i++)
{
for(int j=1;j<1081;j+=4)
{
bef=img[i][j+1];
aft=img[i][j+2];
img[i][j]=(B[j]+img[i+1][j]+img[i][j-1]+bef)>>2;
img[i][j+1]=(B[j+1]+img[i+1][j+1]+aft+img[i][j])>>2;
img[i][j+2]=(B[j+2]+img[i+1][j+2]+bef+img[i][j+3])>>2;
img[i][j+3]=(B[j+3]+img[i+1][j+3]+aft+img[i][j+4])>>2;
B[j] = img[i][j];
B[j + 1] = img[i][j+1];
B[j + 2] = img[i][j+2];
B[j + 3] = img[i][j+3];
}
}
}4.3 优化前后的性能测试(10分)
测试方法:
使用C语言中的库函数测量程序开始到结束的时间,对各个优化方法的时间进行比较,而且我每次运算后打印指定位置数据,发现均相同,证明程序没出错。
测试结果:
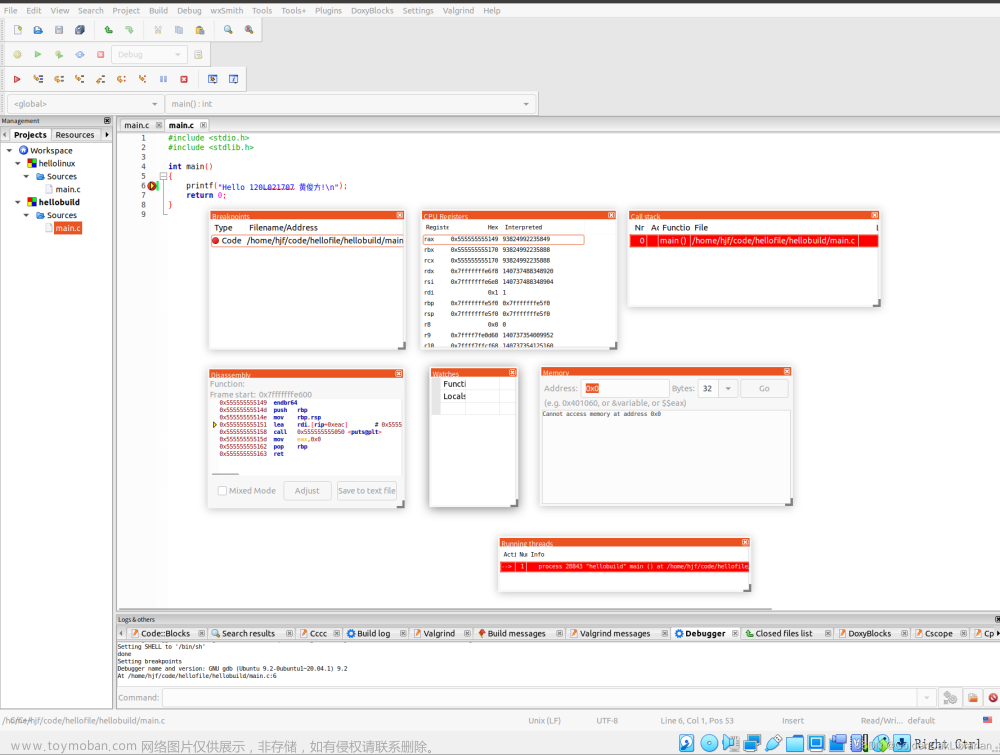
图1性能测试截图
从测试结果可以看到,我采用的优化方法确实提高了程序性能,减少了程序运行时间。
整理所有运行时间如下表:
表1:性能测试结果
| 采用方法描述 |
运行时间(s) |
| (初始状态,没有进行任何优化,局部性很差) |
0.86 |
| after (一般有用的优化,除法变为移位操作) |
0.55 |
| after cache(空间局部性) |
0.78 |
| after cpu(循环展开8) |
0.46 |
| (整合所有非分块的优化方案) |
0.42 |
| 按列对矩阵进行分块(cache) |
0.80 |
| 按行对矩阵进行分块(cache) |
0.77 |
| 按列对矩阵进行分块+除法变成移位 |
0.52 |
| 按行对矩阵进行分块+除法变成移位 |
0.47 |
| 分成4*4的块(cache) |
0.42 |
4.4 结合自己计算机的硬件参数,分析优化后程序的各个参数选择依据。(15分)
我选择结合自己计算机的硬件参数,分析优化后程序的各个参数选择依据。
首先我查看了自己电脑的L1、L2、L3缓存大小,如下图所示:
对分块进行优化:
程序如下:
void fenkuai_cpu_row128(long img[1922][1082])
{
int bsize = 128;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int en = 1081; /* Amount that fits evenly into blocks */
int M = 1081, N = 1921;
for (int jj = 1; jj < M; jj += bsize)
{
for (int ii = 1; ii < N; ii += bsize)
{
for (int j = jj; j < ((jj + bsize) > M ? M : jj + bsize); j++)
{
for (int i = ii; i < ((ii + bsize) > N ? N : ii + bsize); i++)
{
img[i][j] = (img[i - 1][j] + img[i + 1][j] + img[i][j - 1] + img[i][j + 1]) / 4;
}
}
}
}
} 以下为程序运行结果:
说明:Cache的层次,一般有L1, L2, L3 (L是level的意思)的cache。通常来说L1,L2是集成 在CPU里面的(可以称之为On-chip cache),而L3是放在CPU外面(可以称之为Off-chip cache)。当然这个不是绝对的,不同CPU的做法可能会不太一样。这里面应该还需要加上 register,虽然register不是cache,但是把数据放到register里面是能够提高性能的。可以使用减少D-cache miss的数量,增加有效的数据访问的数量。这个要比I-cache优化难一些。由于我的L1高速缓存大小为512KB,8核,所以一个核为64KB,由于long数据类型是8个字节。每个分块的大小为128*128, 所以每个块的miss次数是128。这样总的miss率就是1*1922*1081/(4*128),如果分成4*4的块,不命中率就会很高,经过实验分成更大的块,实验效果不好,根据我电脑的参数,选择128*128的块比选择其他参数效果更好。
对循环展开优化:
void success(long img[1922][1082])
{
int i;
long bef,aft;
long B[1082];
for (i = 0;i < 1082;i++) {
B[i] = img[0][i];//瀛樺偍杈圭晫鍊?
}
for(int i=1;i<1921;i++)
{
for(int j=1;j<1081;j+=4)
{
bef=img[i][j+1];
aft=img[i][j+2];
img[i][j]=(B[j]+img[i+1][j]+img[i][j-1]+bef)/4;
img[i][j+1]=(B[j+1]+img[i+1][j+1]+aft+img[i][j])/4;
img[i][j+2]=(B[j+2]+img[i+1][j+2]+bef+img[i][j+3])/4;
img[i][j+3]=(B[j+3]+img[i+1][j+3]+aft+img[i][j+4])/4;
B[j] = img[i][j];
B[j + 1] = img[i][j+1];
B[j + 2] = img[i][j+2];
B[j + 3] = img[i][j+3];
}
}
}以下为运行结果:
说明:一个规律应当是被普遍认同的,那就是循环展开的程度越高,循环执行开销所占的比例就会越小。可是,根据实验结果,循环展开4次的结果确实好于循环展开8次的结果,经过分析,可能是由于循环展开8次初始化过多变量,导致程序性能提升效果比循环展开4次的效果差。
4.5 还可以采取的进一步的优化方案(5分)
正因为线程是调度的最小单位,控制好线程,也就相当于控制好了计算资源。
多线程与异步计算的关系密切,一般可以使用异步计算的,都可以用多线程来实现,而多线程加速也依赖于异步计算,利用多线程来并行处理多个任务,提高计算资源的利用率,也可以对我们的程序进行优化,从而提升程序性能。
程序代码如下,可以直接运行调试:
#include "stdio.h"
#include<time.h>
#include "math.h"
long img[1922][1082];
// void timecmp(long img[1922][1082])
void test (long img[1922][1082])
{
// printf("\n");
for(int k=0;k<1900;k+=500)
{
printf("%ld\t",img[k][1000]);
}
printf("\n");
}
void putong(long img[1922][1082])
{
for(int j = 1; j < 1081; j++)
{
for (int i = 1; i < 1921;i++)
{
/* code */
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) / 4;
}
}
}
void cache1(long img[1922][1082])
{
for(int j = 1; j < 1081; j++)
{
for (int i = 1; i < 1921;i++)
{
/* code */
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) >> 2;
}
}
}
void cache(long img[1922][1082])
{
for(int i = 1; i < 1921;i++)
{
for (int j = 1; j < 1081; j++)
{
/* code */
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) /4;
}
}
}
void cpu(long img[1922][1082])//循环展开
{
int i;
long bef,aft;
long B[1082];
for (i = 0;i < 1082;i++) {
B[i] = img[0][i];//存储边界值
}
for(int j=1;j<1080;j+=4)
{
for(int i=1;i<1921;i++)
{
bef=img[i][j+1];
aft=img[i][j+2];
img[i][j]=(B[j]+img[i+1][j]+img[i][j-1]+bef)/4;
img[i][j+1]=(B[j+1]+img[i+1][j+1]+aft+img[i][j])/4;
img[i][j+2]=(B[j+2]+img[i+1][j+2]+bef+img[i][j+3])/4;
img[i][j+3]=(B[j+3]+img[i+1][j+3]+aft+img[i][j+4])/4;
B[j] = img[i][j];
B[j + 1] = img[i][j+1];
B[j + 2] = img[i][j+2];
B[j + 3] = img[i][j+3];
}
}
}
void fenkuai_cpu_row(long img[1922][1082])
{
int i, j, k, kk=4, jj=4;
int bsize = 4;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int en = 1921; /* Amount that fits evenly into blocks */
for (jj = 1; jj < en; jj += bsize)
{
for (i = jj; i < jj + bsize; i++)
{
for (j = 1; j < 1081; j++)
{
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) /4;
}
}
}
}
void fenkuai_cpu_row_yi(long img[1922][1082])
{
int i, j, k, kk=4, jj=4;
int bsize = 4;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int en = 1921; /* Amount that fits evenly into blocks */
for (jj = 1; jj < en; jj += bsize)
{
for (i = jj; i < jj + bsize; i++)
{
for (j = 1; j < 1081; j++)
{
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) >>2;
}
}
}
}
void fenkuai_cpu_col(long img[1922][1082])
{
int i, j, k, kk=4, jj=4;
int bsize = 4;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int en = 1081; /* Amount that fits evenly into blocks */
for (jj = 1; jj < en; jj += bsize)
{
for (i = 1; i < 1921; i++)
{
for (j = jj; j < jj + bsize; j++)
{
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) /4;
}
}
}
}
void fenkuai_cpu_col_yi(long img[1922][1082])
{
int i, j, k, kk=4, jj=4;
int bsize = 4;
// int en = bsize * (1922/bsize); /* Amount that fits evenly into blocks */
int en = 1081; /* Amount that fits evenly into blocks */
for (jj = 1; jj < en; jj += bsize)
{
for (i = 1; i < 1921; i++)
{
for (j = jj; j < jj + bsize; j++)
{
img[i][j] = (img[i-1][j] + img[i+1][j]+img[i][j-1] + img[i][j+1] ) >>2;
}
}
}
}
void success(long img[1922][1082])
{
int i;
long bef,aft;
long B[1082];
for (i = 0;i < 1082;i++) {
B[i] = img[0][i];//存储边界值
}
for(int i=1;i<1921;i++)
{
for(int j=1;j<1081;j+=4)
{
bef=img[i][j+1];
aft=img[i][j+2];
img[i][j]=(B[j]+img[i+1][j]+img[i][j-1]+bef)>>2;
img[i][j+1]=(B[j+1]+img[i+1][j+1]+aft+img[i][j])>>2;
img[i][j+2]=(B[j+2]+img[i+1][j+2]+bef+img[i][j+3])>>2;
img[i][j+3]=(B[j+3]+img[i+1][j+3]+aft+img[i][j+4])>>2;
B[j] = img[i][j];
B[j + 1] = img[i][j+1];
B[j + 2] = img[i][j+2];
B[j + 3] = img[i][j+3];
}
}
}
int main ()
{
printf("startle!\n");
int i = 0;
for(int i=0;i<1922;i++)
{
for (int j = 0; j < 1082; j++)
{
/* code */
img[i][j]= i+j;
}
}
clock_t start_t = clock();
for(i=0;i<50;i++)
putong(img);
clock_t end_t = clock();
test(img);
double sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("(初始状态,没有进行任何优化,局部性很差)cost time: %f(s)\n",sum_time);
start_t = clock();
for(i=0;i<50;i++)
cache1(img);
end_t = clock();
test(img);
sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("after (一般有用的优化,除法变为移位操作)cost time: %f(s)\n",sum_time);
start_t = clock();
for(i=0;i<50;i++)
cache(img);
end_t = clock();
test(img);
sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("after cache(空间局部性) cost time: %f(s)\n",sum_time);
start_t = clock();
for(i=0;i<50;i++)
cpu(img);
end_t = clock();
test(img);
sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("after cpu(循环展开) cost time: %f(s)\n",sum_time);
start_t = clock();
for(i=0;i<50;i++)
success(img);
end_t = clock();
test(img);
sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("(整合所有非分块的优化方案)cost time: %f(s)\n",sum_time);
start_t = clock();
for(i=0;i<50;i++)
fenkuai_cpu_col(img);
end_t = clock();
test(img);
sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("(分块col)cost time: %f(s)\n",sum_time);
start_t = clock();
for(i=0;i<50;i++)
fenkuai_cpu_row(img);
end_t = clock();
test(img);
sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("(分块row)cost time: %f(s)\n",sum_time);
start_t = clock();
for(i=0;i<50;i++)
fenkuai_cpu_col_yi(img);
end_t = clock();
test(img);
sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("(分块col+移位)cost time: %f(s)\n",sum_time);
start_t = clock();
for(i=0;i<50;i++)
fenkuai_cpu_row_yi(img);
end_t = clock();
test(img);
sum_time=((double)(end_t-start_t))/CLOCKS_PER_SEC;
printf("(分块row+移位)cost time: %f(s)\n",sum_time);
}第5章 总结
5.1 请总结本次实验的收获
- 实验了很多优化方案,对老师课上内容理解更透彻
- 解决啦以前对程序性能的疑惑,即为什么时间复杂度高的程序运行有时候更快
- 掌握时间函数使用方法
- 提升数学思维,锻炼编程能力
- 了解了图像平滑算法
- 总的来说,这个实验收获还是很多的。尤其是对miss次数的定量分析,让我很受益。之前学习算法之类的,只会大概估计一下复杂度的等级,完全定量地对程序分析对我来说还是比较少。在其他方面,如怎样写出对缓存友好的代码,也有不少收获。
5.2 请给出对本次实验内容的建议
实验内容很好,就是某些问题描述不清,例如4.4题,没有给出操作实例,可能导致很多学生不知道从何做起,希望能改进这一点,其余做的都很好。
注:本章为酌情加分项。
参考文献
为完成本次实验你翻阅的书籍与网站等
[1] 林来兴. 空间控制技术[M]. 北京:中国宇航出版社,1992:25-42.
[2] 辛希孟. 信息技术与信息服务国际研讨会论文集:A集[C]. 北京:中国科学出版社,1999.
[3] 赵耀东. 新时代的工业工程师[M/OL]. 台北:天下文化出版社,1998 [1998-09-26]. http://www.ie.nthu.edu.tw/info/ie.newie.htm(Big5).
[4] 谌颖. 空间交会控制理论与方法研究[D]. 哈尔滨:哈尔滨工业大学,1992:8-13.
[5] KANAMORI H. Shaking Without Quaking[J]. Science,1998,279(5359):2063-2064.文章来源:https://www.toymoban.com/news/detail-423831.html
[6] CHRISTINE M. Plant Physiology: Plant Biology in the Genome Era[J/OL]. Science,1998,281:331-332[1998-09-23]. http://www.sciencemag.org/cgi/ collection/anatmorp.文章来源地址https://www.toymoban.com/news/detail-423831.html
到了这里,关于哈工大csapp-LAB3程序优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!