一.selenium
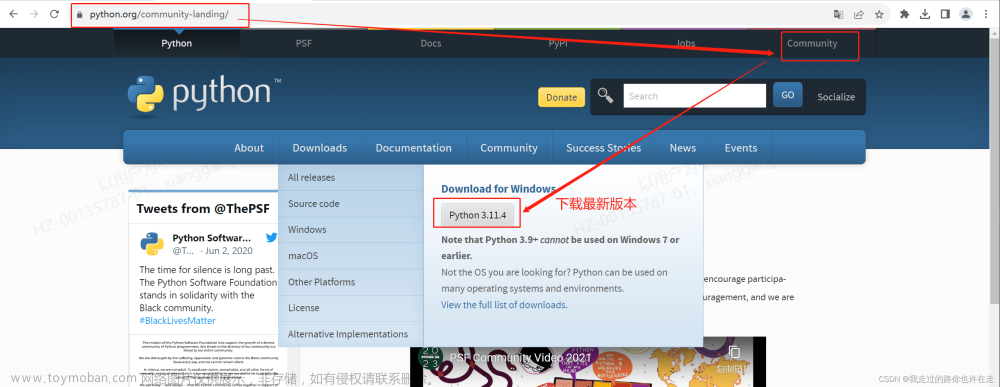
selenium官方网站
- selenium ide 录制工具。 火狐/google/edge插件
- selenium webdriver 结合代码来编写自动化用例。提供很多在浏览器上的操作的api,本文主要记录此项的学习过程
- selenium grid 分布式。火狐/google/edge上同时运行。把所有用例拆分到多设备上运行,运行效率更高,更快。
二.环境准备。(以Chrome为例)
1.查看电脑的浏览器版本

下载谷歌驱动,解压至python安装目录下


2.安装python环境,这个就不多说了
安装selenium库
pip3 install -U selenium. #已装过的加 -u可以更新三、浏览器操作
# 写段代码,打开浏览器,访问百度
# 1、导入selenium
from selenium import webdriver
# 2、打开浏览器。开始与浏览器会话。会去启动chromedriver程序
driver = webdriver.Chrome()
# 3、访问百度
driver.get("http://www.baidu.com")#到这运行弹出百度后自动退出。也可能存在部分windows系统版本没自动退
# 4、浏览器最大化
driver.maximize_window()
# 5、网页刷新操作
driver.refresh()
# 再访问一个页面. 新增了一个窗口
driver.get('https://blog.csdn.net/m0_52310579')
time.sleep(2)
# 6、在有历史访问记录情况下,返回上一次访问的页面。
driver.back()
time.sleep(2)
# 7、在有历史访问记录情况下,访问下一页。
driver.forward()
# 关闭当前窗口。存在多个窗口时,仅关闭当前窗口。存在一个窗口时关闭窗口但不会关驱动程序
driver.close()
# 关闭整个浏览器会话,关闭驱动程序。
driver.quit()
四、了解html构成
html快速了解
html的内容表达:
<起始标签名 属性名=值 属性名=值 属性名=值> 文本内容 </结束标签名> 标签名也叫做元素名
元素的特征:标签名/元素类别、属性、文本内容
通用属性
id: 在这个html当中是唯一的。 id有可能是变动的。
class: 在html当中并不是唯一的。class值可以有多个,用空格隔开。
name: 在html当中并不是唯一的,概率比较高,根据元素的功能业务取的名字。
style: 样式。display: none; visibility: hidden; -- 隐藏不可见
script元素不要考虑用它定位
元素与元素之间的关系: 树形结构 - 兄弟姐妹节点、父节点、先辈节点、子孙后代节点
五、元素定位
目的:希望在整个html中,快速的找到要操作的元素,尽量只匹配到1个
传统八大定位.
第一类:只根据一个特征来定位 >>>很难根据一个特征来定位,可以组合
id 元素的id属性
name 元素的name属性
class_name 元素的class属性
tag_name 元素的标签名
针对a元素:
link_text a元素的文本精准匹配
partial_link_text a元素的文本部分匹配
第二类:万能定位
xpath(相对定位):
css_selector(选择器,难度大需要有前端基础先了解): 参考CSS
五、xpath相对定位
绝对定位:太长,依赖于路径和位置,而且可能页面会发生变动,不稳定。不考虑此方法
相对定位:相对于根结点,相对于上一个节点,只要符合条件的元素
方法1. //元素标签名[@属性名=值] (不变动的属性,不会因为用户的操作发生改变 )

方法2.//元素标签名[text()=值] (还是那个元素,可以换成文本定位)

方法3.and or 组合定位
//元素标签名[text()=值 and @属性名=值 and @属性名=值]
//元素标签名[text()=值 or @属性名=值 or @属性名=值]
方法4.contains(@属性,值) 属性值部分包含 contains(text(),值) 文本内容部分包含
//元素标签名[text()=值 and contains(@属性,值)]
如图:已连续活跃0天,这个0是可变的,所以用contains部分包含“已连续活跃”即可定位

===================以上4种只利用了元素本身的特征来定位=====================
============以下2种利用元素之间的层级关系+元素本身的特征共同来定位============
方法5.按照html页面的顺序,从上往下定位。//.....//.....//......

图文中,想定位那个110文本的元素,根本定位不到,因为110是可变的,所以定位它的父节点 ,再通过//定位父节点下的子节点
//div[@class="stu-num"] 定位父节点
//p 定位子节点
方法6.轴定位。 通过兄弟找,通过后代元素找长辈元素
parent 父节点
ancestor 包括父节点在内的,先辈节点
preceding-sibling 同级的哥哥元素
following-sibling 同级的弟弟元素
已找到的元素与要找的元素之间的关系
语法://已经找到的元素/轴定位名称::标签名[...]

//p[text()="课程人数"]/preceding-sibling::p
六、查找元素
找元素:
find_element(定位策略, 定位表达式) # 只查找匹配表达式的第一个元素,返回元素对象
find_elements(定位策略, 定位表达式) # 查找匹配表达式的所有元素,返回列表,列表的成员是元素对象。
元素的操作:
1、输入操作 ele.send_keys() 可以输入多个值,也可以输入Keys类里的按键
2、点击操作 ele.click()
3、清除输入框的内容 ele.clear()
4、获取元素文本 -- ele.text
5、获取元素的属性值 -- ele.get_attribute(属性名)
from selenium.webdriver.common.by import By #导By类,选择定位策略
from selenium.webdriver.common.keys import Keys #导Keys类,用于除26英文字母和数字之外的操作
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://testingpai.com/")
#查找输入框
ele = driver.find_element(By.XPATH, '//input[@placeholder="Search TestingPai via Bing"]')
#对输入框进行输入并点击回车
ele.send_keys("selenium",Keys.ENTER)
time.sleep(7)
driver.quit()七、面试题:selenium有哪些等待方式?隐性等待与显性等待的区别??
在页面进行一系列操作的时候,是会有页面内容进行更新的。。
要等待更新的内容呈现以后,再进行操作
所以我们需要适当的等待
time.sleep() 强制等待,等固定时间,不管元素什么时候出现。不够智能
智能等待:隐性等待、显性等待
给一个等待上限,假设20秒,只要在20秒内任意时间条件成立了,就不再等待,继续执行下一行代码
隐性等待:implicitly_wait(等待上限)
条件:元素存在于页面即可。【存在就是在html当中能够搜索到。可见是页面当中占据了一定的大小】
一般创建会话之后,就可以调用隐性等待。只需要调用一次,整个会话【一次会话(打开浏览器到关闭浏览器)】生效。如果超过等待上限,元素还不存在,则报超时错误。
显性等待:有一个专门的条件模块 WebDriverWait类
等待 - 等待上限,等待期间去轮询条件的周期。确定每xx久,去看一次条件是否成立
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# WebDriverWait(driver, 等待上限, 每隔多久去查看条件成立默认是0.5秒).until(条件)直到条件成立
# WebDriverWait(driver, 等待上限, 每隔多久去查看条件成立默认是0.5秒).until_not(条件) 直到条件不成立
# expected_conditions 每一个条件就是一个函数,部分条件如下⬇️:
# visibility_of_element_located(元素定位元组) -- 指定元素可见
# presence_of_element_located(元素定位元组) --- 指定元素存在
# element_to_be_clickable(元素定位元组或者driver.find_element) --- 指定元素可点击
locator = (By.XPATH,"//span[@id='navLogin'")
WebDriverWait(driver,20).until(EC.visibility_of_element_located(locator=locator))常用组合:
显性等待 + sleep(0.5-2)
3个等待之间完全不冲突....
八、窗口切换
1、触发新窗口出现
1.1、sleep(0.5 ~1)
2、获取所有的窗口句柄 -- 句柄理解为是个窗口id,每次都会变
列表 - 窗口打开的顺序。最新打开的窗口,会追加在列表末尾。
3、切换
driver.switch_to.window(窗口句柄)
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://testingpai.com")
#1、触发新的窗口
driver.find_element(By.XPATH,"//a[contains(text(),'长歌测试半生,归来仍是少')]").click()
#2、稍作等待
time.sleep(0.5)
#3、获取所有的窗口句柄
wins = driver.window_handles
print("当前会话中的所有窗口句柄:",wins)
print("当前窗口的句柄:",driver.current_window_handle)
#4、切换到最新打开的窗口
driver.switch_to.window(wins[-1])
print("切换之后的窗口句柄:",driver.current_window_handle)
#5、找到元素获取文本
locator = (By.XPATH,"//span[@aria-label='总访问计数']//span")
WebDriverWait(driver,10).until(EC.visibility_of_element_located(locator))
value=driver.find_element(*locator).text
print(f"总访问量为:{value}")
#6、再切换窗口
driver.switch_to.window(wins[-2])
time.sleep(7)
driver.quit()九、iframe切换
find_element的时候,是不会跨html的。
iframe == 里面存放的就是一个html
如果我们要找iframe当中的元素进行操作,那么必须切换进入iframe当中的html才能找得着。
1、怎么知道要操作的元素是否在iframe当中??
F12当中写完定位表达式找到元素后,看查找框上面的,元素的绝对定位路径中是否有html(不是开头)
当你明确元素定位没有错,等待也够,依然报找不着的,考虑一下是不是在iframe当中。
2、如果在iframe当中,切换进入iframe。
driver.switch_to.frame(3种)
1种-字符串:id或者name属性
2种-元素对象:driver.find_element()
3种-整数:iframe元素的索引。从0开始的哟
3、回到默认的html当中去
driver.switch_to.default_content()
4、默认html -> iframe -> iframe
回到上一层iframe
driver.switch_to.parent_frame()
十、alert
js弹框
案例地址:https://www.w3school.com.cn/js/js_popup.asp
如果遇到了js弹框,不把它关掉,啥也别想干。
目标:将它关掉
Alert类 -- 能处理警告框、确认框和提示框。
实例化: Alert(driver)
方法:
accept() -- 确定
dismiss() -- 取消
send_keys() -- 输入内容
import time
driver = webdriver.Chrome()
driver.implicitly_wait(20)
driver.get("https://www.w3school.com.cn/tiy/t.asp?f=eg_js_prompt")
driver.switch_to.frame('iframeResult')
driver.find_element(By.XPATH,'//button[text()="试一试"]').click()
time.sleep(2)
alert = driver.switch_to.alert
alert.accept()
time.sleep(7)
driver.quit()十一、鼠标操作
能不用鼠标操作,就不用鼠标操作,而且当你的代码执行时有鼠标操作,你不能动鼠标。
ActionChains类 ---
鼠标操作方法:
move_to_element(element) --悬浮
click(element) -- 点击
double_click(element) --双击
context_click(element) -- 右键
drag_and_drop(ele1, ele2) -- 拖拽
pause() -- 暂停
执行鼠标操作:perform()
使用步骤:
1、实例化ActionChains(driver)
2、调用鼠标操作方法 -- 可以调多个
3、调用perform() --执行鼠标操作
from selenium.webdriver.common.action_chains import ActionChains
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://testingpai.com/")
#1、实例化ActionChains类
ac = ActionChains(driver)
#2、调用鼠标操作方法 --可以调多个-- 悬浮+点击
ele = driver.find_element(By.XPATH,'//span[contains(text(),"柠檬")]')
ac.move_to_element(ele).pause(0.5).click(ele) #链式调用
#3、调用perform(),执行鼠标操作
ac.perform()
#4、选择下拉列表当中某个元素,点击操作
driver.find_element(By.XPATH,'//details-menu//a[text()="柠檬班官网"]').click()
time.sleep(7)
driver.quit()
十二、js滚动条操作
为什么要滚动滚动条??
1、查看其它元素
第一种: 页面太长,元素已经加载出来,但是看不见。(两种方法)
1.1.元素属性:ele.location_once_scrolled_into_view -- 【与窗口顶部对齐】,与底部对齐选择下面这个
1.2. js代码:arguments[0].scrollIntoView(true);
true 【与窗口顶部对齐】
false 【与窗口底部对齐】
python selenium当中如何去执行js代码?
driver.execute_script(js代码字符串, 参数)
1.3、js如何接收传进来的参数??
--- js代码中,使用arguments来接收外部参数。 列表类型。
--- arguments[0] 表示第一个参数
--- arguments[n] 表示第n+1个参数
driver = webdriver.Chrome()
driver.get("http://testingpai.com/article/1595507317340")
#找到元素
ele = driver.find_element(By.XPATH,'//h5[text()="1、BeautifulReport风格的报告"]')
#将元素拖动到可见区域中来---默认与顶部对齐
# ele.location_once_scrolled_into_view
#使用js代码--与页面底部对齐
# driver.execute_script("arguments[0].scrollIntoView(false)",ele)
time.sleep(7)
driver.quit()第二种:分页加载,滚动条边滚动边加载内容。 -- 翻页。
只能滚动滚动条
- window.scrollTo(0,0):滑动到指定坐标位置
- window.scrollBy(0,0):基于当前位置滑动指定像素距离 --
- document.documentElement.scrollTop:获取当前滚动距离最上方的距离(垂直方向)
- document.documentElement.scrollLeft:获取当前滚动距离最左侧的距离(水平方向)
driver = webdriver.Chrome()
driver.get("https://www.jd.com/?cu=true&utm_source=baidu-search&utm_medium=cpc&utm_campaign=t_262767352_baidusearch&utm_term=106807362512_0_c994b5c473db4a1b8ee23ea1d0cff6f6")
time.sleep(3)
for _ in range(6):
driver.execute_script("window.scrollBy(0,800);")
time.sleep(2)
# 等待你要找的元素可见,如果可见就不滚啦。。如果不可见,继续滚。最多滚10次。
time.sleep(7)
driver.quit()十三、js点击操作
用element的点击操作,没有生效的情况下,可以选择使用js去完成点击操作。
js点击元素的代码: 元素.click();
注意:js代码是立即去操作页面,不会去等待。在调用js代码之前,要等待元素是可见的。
driver.execute_script("arguments[0].click()", ele)
driver = webdriver.Chrome()
driver.implicitly_wait(20)
driver.get('https://www.iloveyou.com/#/login')
# 等待元素可见
loc = (By.XPATH, '//span[text()="登录"]/parent::button')
WebDriverWait(driver,10).until(EC.visibility_of_element_located(loc))
# driver.find_element(*loc).click()
ele = driver.find_element(*loc)
# 执行js代码 ---
driver.execute_script("arguments[0].click()", ele)
time.sleep(7)
driver.quit()十四、上传操作
一、pywinauto
1、pip install pywinauto
2、使用(windows)
from pywinauto.keyboard import SendKeys
SendKeys('文件路径1')
SendKeys('文件路径2') # 支持传多个
SendKeys('{ENTER}')
二、pyautogui文章来源:https://www.toymoban.com/news/detail-423941.html
1、pip install pyautogui
2、使用(跨平台、windows、linux、mac、文件路径不能有中文、不支持多文件上传)
pyautogui.typewrite(r'D:\fk88.png') 选择文件
pyautogui.press(keys='enter',presses=3) 确认上传
参数:1、keys:按键; 2、presses=1:重复按多少次; 3、interval=0.0:间隔(浮动,可选):每次按下之间的秒数文章来源地址https://www.toymoban.com/news/detail-423941.html
到了这里,关于python+selenium实现UI自动化(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!