1. 问题发生时间
待补充文章来源:https://www.toymoban.com/news/detail-423987.html
2. 怎么发现的
待补充
3. 当时的现象
3.1 现象一
大多数情况下都正常,偶尔很慢。
3.1.1 主要考虑原因
- 数据库在刷新脏页,例如redo log写满了需要同步到磁盘。
- 或者执行的时候,遇到锁,如表锁、行锁。
- 此次执行的SQL语句存在问题,且真实业务数据量大,便会导致速度极慢的问题。
【补充】
脏页:当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。
redo log:mysql 设计了 redo log , 具体来说就是只记录事务对数据页做了哪些修改,这样就能完美地解决性能问题。
3.1.2 其他可能原因
- 网络不好
- 内存不足
- I/O吞吐量小
- 形成了瓶颈效应,不过一般公司不会出现这种情况,用的设施都很好的
3.2 现象二
这条SQL语句一直执行的很慢。
3.2.1 主要考虑原因
没有用上索引或者索引失效:
- 例如该字段没有索引
- 或者由于对字段进行运算、函数操作导致无法用索引。
4. 具体的指标
5. 排查的方案
从索引、架构、网络、I/O吞吐量、内存、锁、SQL语句等各个方面来分析。
由于涉及范围比较广,如果不能理清思路去逐步分析,便会使得排查效率极低。
为了快速定位,针对这个问题,我们得对系统有个全局监控。
在有了大概方向后,还得结合具体手段去定位慢查询SQL:
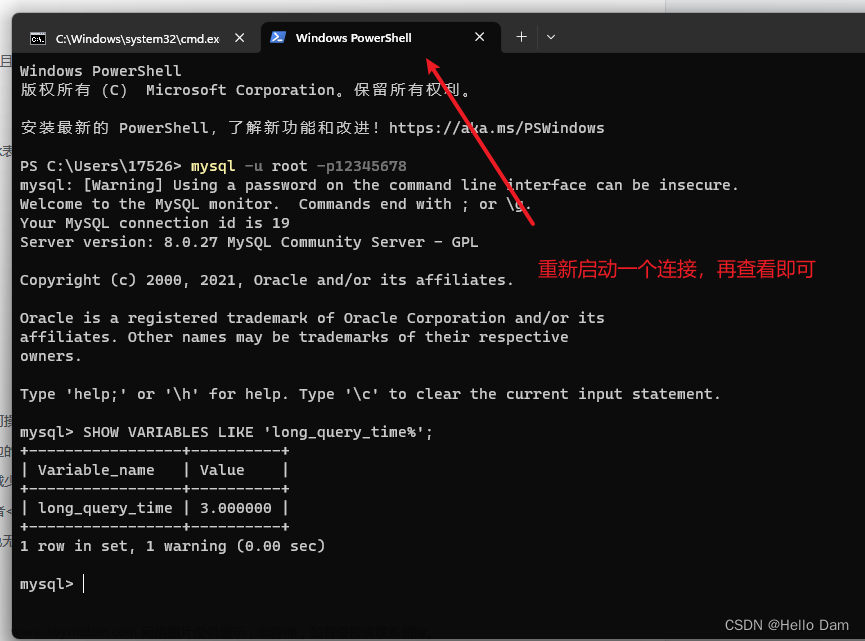
- 首先数据库中设置SQL慢查询,我们可以修改配置文件,在my.ini增加几行:主要是慢查询的定义时间(超过2秒就是慢查询),以及慢查询log日志记录(slow_query_log)或者直接通过命令行,通过MySQL数据库开启慢查询。
[mysqlId]
// 定义查过多少秒的查询算是慢查询,我这里定义的是2秒
long_query_time = 2
#5.8、5.1等版本配置如下选项
log-slow-queries="mysql_slow_query.log"
#5.5及以上版本配置如下选项
slow-query-log=On
slow_query_log_file="mysql_slow_query.log"
// 记录下没有使用索引的query
log-query-not-using-indexestpspb 16glos dndnorte/t
mysql>set global slow_query_log=ON
mysql>set global long_query_time = 3600;
mysql>set global
log_querise_not_using_indexes=ON;
- 然后当出现慢查询时,我们可以去分析’慢查询日志’。我们可以使用’show processlist’命令定位低效率执行SQL,也可以用‘explain’分析SQL的‘执行计划’。
【补充】
使用‘explain’字段,一般会关注哪些字段?
其实使用这个我们主要是看有没有使用到索引,索引失效,访问类型等问题。因此,我们大多情况都是看possible_keys、key、key_len(这三个一般套起来分析),还有就是Extra、type(看全表扫描还是索引、还是索引范围扫描)等等。
possible_keys:表示查询可能使用的索引。
key:实际使用的索引。
key_len: 使用索引字段的长度,结合起来看出索引使用情况。
Extra
using index:覆盖索引,不回表,尽量覆盖,可以提高效率。
using filesort:需要额外的排序,不能通过索引得到排序结果,尽量避免这种情况,会使得速度很慢。
6. 排查后的解决方案
索引+SQL语句+数据库结构优化+优化器优化+架构优化+I/O+内存+网络
6.1 索引
需要从建立索引就开始考虑,索引一般建在where和order by,数据基数要大,区分度要高,不要过度索引,在提高速度同时节约内存。
避免索引失效,然后可以尽量覆盖索引,5.6支持索引下推可以使得速度更快。
在写多读少的场景下,可以选择‘普通索引’而不要‘唯一索引’。因为更新时,普通索引可以使用change buffer进行优化,减少磁盘IO,将更新操作记录到change bugger,等查询来了将数据读到内存再进行修改。
6.2 SQL语句
我们有很多优化手段,随便举几个,比如分页查询优化,该方案适用于主键自增的表,可以把Limit查询转换成某个位置的查询。
select * from tb_sku where id>20000 limit 10;
Insert插入语句时,多条插入语句写成一条,同时可以利用主键索引特性让数据有序插入而使效率更高。
当然还有很多关于SQL写法的优化,这里略提。比如还有,注意union和union all的区别,union all好;注意使用DISTINCT,在没有必要时不要用,它同union一样会使查询变慢,注意临时表、视图等等。
6.2.1 数据库结构
可以考虑将字段多的表分解成多个表。有些字段使用频率高,有些低,数据量大时,会由于使用频率低的存在而变慢,可以考虑分开。
而对于经常联合查询的表,可以考虑建立中间表。
6.2.2 架构
在真实业务场景中,数据量大,并发压力大,我们可以考虑分库分表,纵向、横向分割表,减少表的尺寸,还有采用读/写分离(主库写,从库读)集群模式。
当然采用集群,无疑要增加成本,分库分表又要考虑分布式事务、分布式ld、一致性等等问
题,因此有好也有坏,当你采用某种措施之前也得考虑其性价比,最终带来的好处更多还是坏处更多。
6.2.3 其他
除了这些,我们有时也会考虑,把数据、日志、索引放到不同‘I/O’设备上,增加读取速度,‘升级硬件’,'提高网速’等等。不过也不能一味地去追求速度,因为也得考虑成本,所以具体问题需要具体分析。
7. 解决后的指标
待补充
参考资料:
【大厂面试】分析一下SQL执行慢的原因?如何排查,优化思路?文章来源地址https://www.toymoban.com/news/detail-423987.html
到了这里,关于SQL执行慢的问题排查和优化思路的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!