本文目标
Oracle->Debezium->Kafka->Flink->PostgreSQL
Flink消费Kafka中客户、产品、订单(ID)三张表的数据合并为一张订单(NAME)表。
前置环境
Oracle内创建三张表
-- 客户信息表
CREATE TABLE "YINYX"."T_CUST" (
"CUST_ID" NUMBER(9,0) VISIBLE NOT NULL,
"CUST_NAME" VARCHAR2(32 BYTE) VISIBLE
);
ALTER TABLE "YINYX"."T_CUST" ADD CONSTRAINT "SYS_C007568" PRIMARY KEY ("CUST_ID");
-- 产品信息表
CREATE TABLE "YINYX"."T_PROD" (
"PROD_ID" NUMBER(9,0) VISIBLE NOT NULL,
"PROD_NAME" VARCHAR2(32 BYTE) VISIBLE
);
ALTER TABLE "YINYX"."T_PROD" ADD CONSTRAINT "SYS_C007569" PRIMARY KEY ("PROD_ID");
-- 订单信息表
CREATE TABLE "YINYX"."T_ORDER" (
"ORDER_ID" NUMBER(9,0) VISIBLE NOT NULL,
"CUST_ID" NUMBER(9,0) VISIBLE,
"PROD_ID" NUMBER(9,0) VISIBLE,
"AMOUNT" NUMBER(9,0) VISIBLE
);
ALTER TABLE "YINYX"."T_ORDER" ADD CONSTRAINT "SYS_C007570" PRIMARY KEY ("ORDER_ID");
PostgreSQL内创建一张表
CREATE TABLE "public"."t_order_out" (
"order_id" int8 NOT NULL,
"cust_name" varchar(50) COLLATE "pg_catalog"."default",
"prod_name" varchar(50) COLLATE "pg_catalog"."default",
"amount" int8
);
ALTER TABLE "public"."t_order_out" ADD CONSTRAINT "t_order_out_pkey" PRIMARY KEY ("order_id");
其他前置环境
Oracle、PostgreSQL、Kafka、FLink、Debezium-Server的部署参见本系列其他文章搭建。
Oracle内建表
采用前置条件中的语句建表即可,如果遇到日志抓取问题,可以用如下语句停止、启动、删除xstream出站服务器
sqlplus sys/manager@hostyyx:1521/ORCLCDB as sysdba
BEGIN
DBMS_APPLY_ADM.START_APPLY(apply_name => 'xstrmout');
END;
/
BEGIN
DBMS_APPLY_ADM.STOP_APPLY(apply_name => 'xstrmout');
END;
/
BEGIN
DBMS_APPLY_ADM.DROP_APPLY(apply_name => 'xstrmout');
END;
/
PostgreSQL内建表
采用前置条件中的语句建表即可。
启动Kafka
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties
./kafka-server-start.sh -daemon ../config/server.properties
./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic yyx.YINYX.T_CUST
启动Debezium-Server
[yinyx@hostyyx debezium-server]$ cat conf/application.properties
quarkus.http.port=8999
rkus.log.level=INFO
quarkus.log.console.json=false
debezium.source.connector.class=io.debezium.connector.oracle.OracleConnector
debezium.source.offset.storage.file.filename=data/ora_offsets.dat
debezium.source.offset.flush.interval.ms=0
debezium.source.database.hostname=127.0.0.1
debezium.source.database.port=1521
debezium.source.database.user=c##xstrm
debezium.source.database.password=xstrm
debezium.source.database.dbname=ORCLCDB
debezium.source.database.pdb.name=ORCLPDB1
debezium.source.database.connection.adapter=xstream
debezium.source.database.out.server.name=xstrmout
#debezium.source.snapshot.mode=schema_only
debezium.source.snapshot.mode=initial
debezium.source.schema.include.list=YINYX
debezium.source.table.include.list=YINYX.T1,YINYX.T_CUST,YINYX.T_PROD,YINYX.T_ORDER
debezium.source.log.mining.strategy=online_catalog
debezium.source.topic.prefix=yyx
debezium.source.key.converter.schemas.enable=false
debezium.source.value.converter.schemas.enable=false
debezium.source.schema.history.internal.kafka.bootstrap.servers=127.0.0.1:9092
debezium.source.schema.history.internal.kafka.topic=ora_schema_history
debezium.source.decimal.handling.mode=string
debezium.source.lob.enabled=true
debezium.source.database.history.skip.unparseable.ddl=true
debezium.source.tombstones.on.delete=false
debezium.sink.type=kafka
debezium.sink.kafka.producer.bootstrap.servers=127.0.0.1:9092
debezium.sink.kafka.producer.key.serializer=org.apache.kafka.common.serialization.StringSerializer
debezium.sink.kafka.producer.value.serializer=org.apache.kafka.common.serialization.StringSerializer
debezium.format.key.schemas.enable=false
debezium.format.value.schemas.enable=false
[yinyx@hostyyx debezium-server]$
./run.sh
启动FLink
./start-cluster.sh
./sql-client.sh
FLink内创建任务
-- Kafka内T_CUST客户信息表变更信息映射表
CREATE TABLE tcust_kafka (
CUST_ID BIGINT NOT NULL,
CUST_NAME STRING NULL,
PRIMARY KEY(CUST_ID) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'topic' = 'yyx.YINYX.T_CUST',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'scan.startup.mode' = 'earliest-offset',
'debezium-json.schema-include' = 'false',
'properties.group.id' = 'gyyx',
'format' = 'debezium-json'
);
-- Kafka内T_PROD产品信息表变更信息映射表
CREATE TABLE tprod_kafka (
PROD_ID BIGINT NOT NULL,
PROD_NAME STRING NULL,
PRIMARY KEY(PROD_ID) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'topic' = 'yyx.YINYX.T_PROD',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'scan.startup.mode' = 'earliest-offset',
'debezium-json.schema-include' = 'false',
'properties.group.id' = 'gyyx',
'format' = 'debezium-json'
);
-- Kafka内T_ORDER订单信息表变更信息映射表
CREATE TABLE torder_kafka (
ORDER_ID BIGINT NOT NULL,
CUST_ID BIGINT NULL,
PROD_ID BIGINT NULL,
AMOUNT BIGINT NULL,
PRIMARY KEY(ORDER_ID) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'topic' = 'yyx.YINYX.T_ORDER',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'scan.startup.mode' = 'earliest-offset',
'debezium-json.schema-include' = 'false',
'properties.group.id' = 'gyyx',
'format' = 'debezium-json'
);
-- 客户信息表在PG库内的同步测试,本案例没有用到
CREATE TABLE tcust_pg (
cust_id BIGINT NOT NULL,
cust_name STRING NULL,
PRIMARY KEY(cust_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://127.0.0.1:6432/test',
'username' = 'test',
'password' = 'test',
'driver' = 'org.postgresql.Driver',
'table-name' = 't_cust'
);
-- 同步测试,用于验证基本同步通道是否正确
insert into tcust_pg(cust_id, cust_name) select CUST_ID, CUST_NAME from tcust_kafka;
-- PG库内的转换目标表,本案例的输出结果
CREATE TABLE torderout_pg (
order_id BIGINT NOT NULL,
cust_name STRING NULL,
prod_name STRING NULL,
amount BIGINT NULL,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://127.0.0.1:6432/test',
'username' = 'test',
'password' = 'test',
'driver' = 'org.postgresql.Driver',
'table-name' = 't_order_out'
);
-- 提交转换任务给FLink,三个Kafka数据源关联同步到到一个PG目标表
insert into torderout_pg(order_id, cust_name, prod_name, amount)
select o.ORDER_ID, c.CUST_NAME, p.PROD_NAME, o.AMOUNT, o.CUST_ID, o.PROD_ID from torder_kafka o
inner join tcust_kafka c on o.CUST_ID=c.CUST_ID
inner join tprod_kafka p on o.PROD_ID=p.PROD_ID;
相关功能验证
Oracle是否正常
用SQL语句检查表是否都正常
PostgreSQL是否正常
用SQL语句检查表是否都正常
debezium是否正常
启动后出现版本信息并不能立刻抓到日志,还需要等1到5分钟才开始抓,正常在Oracle内修改后2秒左后可以抓到日志
2022-12-29 22:28:26,568 INFO [io.deb.con.ora.OracleConnection] (debezium-oracleconnector-yyx-change-event-source-coordinator) Database Version: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.3.0.0.0
2022-12-29 22:35:52,051 INFO [io.deb.con.com.BaseSourceTask] (pool-7-thread-1) 1 records sent during previous 00:07:32.967, last recorded offset of {server=yyx} partition is {transaction_id=null, lcr_position=000000000032b3460000000100000001000000000032b345000000010000000102, snapshot_scn=3086106}
Kafka是否正常
[yinyx@hostyyx bin]$ ./kafka-topics.sh --list --bootstrap-server 127.0.0.1:9092
__consumer_offsets
logminer_schema_history
ora_schema_history
yyx
yyx.YINYX.T1
yyx.YINYX.T_CUST
yyx.YINYX.T_ORDER
yyx.YINYX.T_PROD
[yinyx@hostyyx bin]$
[yinyx@hostyyx bin]$ ./kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic yyx.YINYX.T_CUST
{"before":{"CUST_ID":1,"CUST_NAME":"zhangsan3"},"after":{"CUST_ID":1,"CUST_NAME":"zhangsan4"},"source":{"version":"2.0.0.Final","connector":"oracle","name":"yyx","ts_ms":1672327040000,"snapshot":"false","db":"ORCLPDB1","sequence":null,"schema":"YINYX","table":"T_CUST","txId":"3.20.832","scn":"3333134","commit_scn":null,"lcr_position":"000000000032dc0f0000000100000001000000000032dc0e000000010000000102","rs_id":null,"ssn":0,"redo_thread":null,"user_name":null},"op":"u","ts_ms":1672327045610,"transaction":null}
{"before":{"CUST_ID":1,"CUST_NAME":"zhangsan4"},"after":{"CUST_ID":1,"CUST_NAME":"zhangsan"},"source":{"version":"2.0.0.Final","connector":"oracle","name":"yyx","ts_ms":1672361625000,"snapshot":"false","db":"ORCLPDB1","sequence":null,"schema":"YINYX","table":"T_CUST","txId":"3.9.833","scn":"3345527","commit_scn":null,"lcr_position":"0000000000330c7800000001000000010000000000330c77000000010000000102","rs_id":null,"ssn":0,"redo_thread":null,"user_name":null},"op":"u","ts_ms":1672361629456,"transaction":null}
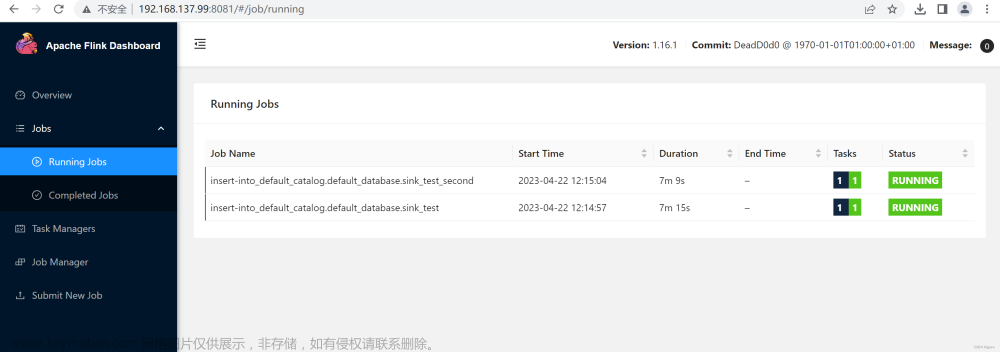
FLink是否正常
http://192.168.200.143:8081/#/job/running
可以看到正常运行的任务
本文目标效果验证
对Oracle内的T_ORDER表做增删改操作,ID信息需要在T_CUST、T_PROD表内有值,在2、3秒后查看PostgreSQL目标表内t_order_out表会同步更新。
Oracle内T_CUST表

Oracle内T_PROD表

Oracle内T_ORDER表
 文章来源:https://www.toymoban.com/news/detail-424278.html
文章来源:https://www.toymoban.com/news/detail-424278.html
PostgreSQL表内t_order_out表

10da4a7c-90d5-4804-885c-731805ea2792文章来源地址https://www.toymoban.com/news/detail-424278.html
到了这里,关于FLink多表关联实时同步的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!