HDFS的通讯协议
HDFS架构
HDFS(Hadoop分布式文件系统) 是Apache Hadoop Core 项目的一部分,被设计为可运行在通用硬件上、能处理超大文件的分布式文件系统,其具有高容错、高吞吐、易扩展、高可靠等特性。
HDFS架构
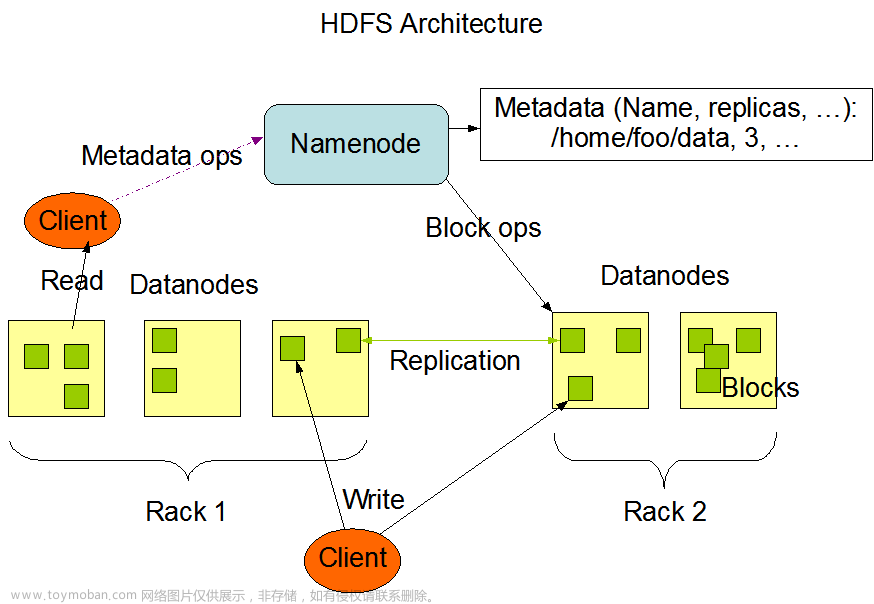
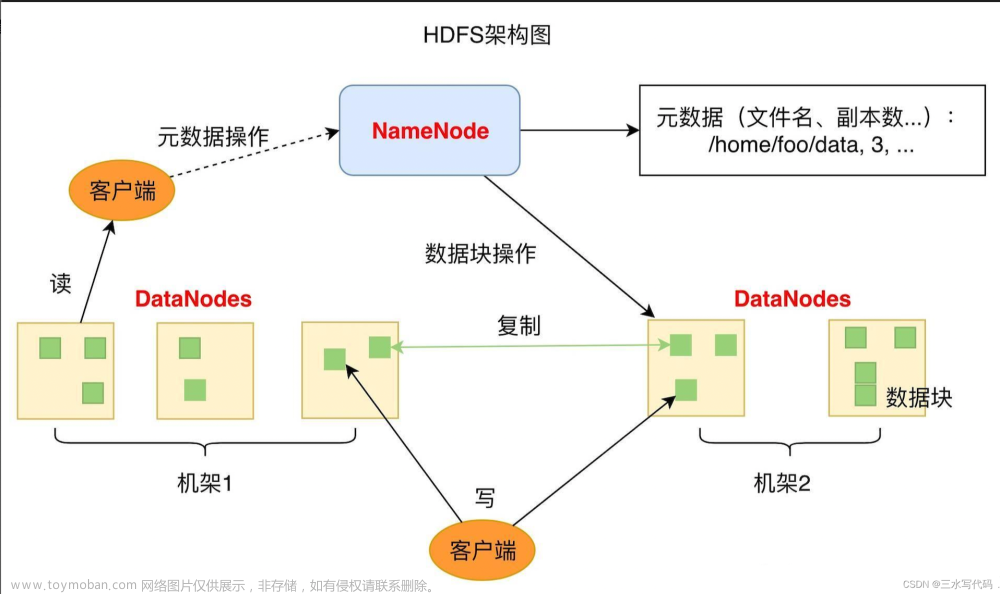
HDFS是一个主/从体系结构的分布式系统,在HDFS集群中,有一个NameNode 和一组DataNode,用户可以通过HDFS客户端同NameNode和DataNode交互访问数据。其中NameNode 是主,DataNode 是从。NameNode 负责管理文件系统的命名空间(namespace)以及数据块到具体的DataNode的映射关系等信息。DataNode负责管理它所在节点上的存储。
HDFS基本概念
1.数据块(Block)
HDFS中的数据以数据块的新式存储的,数据块是HDFS文件处理的最小单元,由于HDFS文件一般比较大,为了减少寻址开销,所以数据块一般也比较大,默认是128M,这些数据块会以文件的形式存储在DataNode所在节点的磁盘上。
在HDFS中,所有的文件都会被切分成若干数据块,分布在DataNode节点上进行存储,为了保证HDFS能在通用硬件上的高容错性,高可靠性,HDFS会将同一数据块进行冗余备份到不同的DataNode上(默认3副本),所以如果某一个DataNode损坏,或者其块数据损坏,并不会影响文件的读取。
在HDFS读写操作时,数据块都是最小的单元,HDFS客户端会首先到NameNode查找文件对应的数据块信息,然后根据数据块信息到对应的DataNode上读取数据。在进行数据写入时,HDFS客户端也会首先跟NameNode交互,申请数据块写入的DataNode信息,然后与对应的DataNode建立数据管道写入数据。
2.NameNode
HDFS是一个典型的主/从架构的分布式系统,NameNode是主/从架构中的主节点。其管理着文件系统的命名空间(namespace),包括文件系统目录树、文件/目录信息以及文件的数据块索引,这些数据既会存储在NameNode的内存中,也会被持久化到NameNode所在节点的磁盘上(fsImage 和 编辑日志文件)。同时NameNode还会存储数据块和DataNode的对应关系,这部分数据不会持久化到磁盘上,而是会在NameNode启动时动态构建,块信息也会随着DataNode 的数据块上报而变动。
NameNode 是HDFS的主节点,如果NameNode单点故障,文件系统就会不可用。为了解决单点故障问题,在Hadoop2.X版本后,引入了NameNode HA 的支持,在HA模式下,会启动2个NameNode,他们之间的元数据信息是完全同步的,当Active NameNode 出现宕机的情况,StandBy NameNode 会切换成Active状态,从而不影响 HDFS集群的服务。
NameNode 的内存中除了保存文件系统的namespace外,还保存了文件系统中所有的数据块与DataNode节点的对应关系,因此,NameNode 的内存将会成为HDFS的横向扩展的瓶颈,而当数据块过多,也会引起NameNode频繁的GC,影响系统的稳定性。所以在Hadoop2.X 也引入了HDFS 联邦,HDFS联邦允许添加NameNode从而实现namespace 的扩展,每个NameNode都管理文件系统namespace 中的一部分,是一个独立的命名空间卷(namespace volume)。命名空间卷之间是相互独立的,互相不通讯。甚至一个命名空间卷消失也不会影响由其他NameNode管理的namespace 的可用性。如 一个NameNode 只管理/user 目录下的所有文件,另外一个NameNode管理 /share 目录下的所有文件,他们相互独立运行。
3.DataNode
DataNode 是HDFS中的从节点,DataNode 会根据HDFS客户端请求或者NameNode调度将新的数据块写入到本地的存储,或者读取存储在本地的数据块。
DataNode会不断的向NameNode 发送心跳、数据块汇报、缓存汇报;NameNode会通过心跳、数据块汇报、缓存汇报向数据节点发送响应指令,DataNode会执行这些指令,比如创建、删除、复制数据等等
4.HDFS客户端
HDFS客户端提供了多种客户端接口给用户使用,包括命令行接口,浏览器接口、代码API接口。用户通过这些接口来操作HDFS。这些接口的实现都是简历在DFSClient 类的基础上的,DFSClient 类封装了客户端与HDFS其他节点之间的复杂交互
5.HDFS通讯协议
HDFS是一个分布式文件系统,内部数据交互相当复杂,通常涉及到DataNode、NameNode、客户端之间的配合,相互调用才能实现,为了降低代码的耦合性,HDFS将这些节点间的调用抽象成了不同的接口,实现了HDFS之间的通讯协议。
HDFS通讯协议
HDFS RPC接口
Hadoop 的RPC调用使得HDFS进程能像调用本地方法一样调用另外一个进程中的方法,并可以传递JAVA基本数据类型或者自定义类型作为参数,同时收到返回值。如果RPC调用过程中出现异常,在本地也能收到对应的异常。
当下Hadoop RPC 是基于Protobuf实现的,Hadoop RPC 接口主要定义在org.apache.hadoop.hdfs.protocol 包和 org.apache.hadoop.server.protocol包中,主要包含以下接口:
- ClientProtocol:ClientProtocol定义了客户端与NameNode直接的接口,这个接口中方法众多,客户端对HDFS所有的操作都经过这个接口,读写文件也是先通过这个接口与NameNode协商后,再与DataNode交互进行数据的读出和写入
- ClientDataNodeProtocol:客户端与DataNode之间的接口,这其中定义的方法主要是用于客户端获取数据节点信息时调用,真正的数据读写交互则是通过流式接口进行的
- DatanodeProtocol:DataNode通过这个接口与NameNode通讯,同时,NameNode会通过这个接口中的方法向DataNode下发指令,这个是NameNode与DataNode通讯的唯一方式,内含DataNode向NameNode注册、汇报数据块,NameNode也会通过这个接口返回一些指令,用于复制、删除、恢复数据块
- InterDatanodeProtocol:DataNode与DataNode之间的接口,DataNode之间会通过这个接口星湖通讯,主要用于数据块的恢复,同步DataNode节点上存储的数据块副本信息
- NamenodeProtocol:SecondaryNameNode与NameNode之间的接口,SecondaryNameNode作为同步NameNode中的元数据文件和元数据合并相关的操作,其对应的接口在这里
- 其他接口:主要包含安全相关接口(RefreshAuthorizationPolicyProtcol、RefreshUserMappingsProtocol)、HA相关接口(HASrviceProtocol)等
下面重点介绍 ClientProtocol、ClientDataNodeProtocol、DatanodeProtocol、InterDatanodeProtocol和NamenodeProtocol 等接口的定义
-
ClientProtocol
在ClientProtocol定义了所有客户端发起的,由NameNode响应的操作,接口大致分为以下几类:- HDFS文件读相关操作
- HDFS文件写及追加写相关操作
- HDFS namespace 管理相关操作
- 系统问题与管理相关操作
- 快照相关操作
- 缓存相关操作
- 其他操作
HDFS文件读、写、追加写、namespace管理的操作,都可以在FileSystem类中找到对应的方法,这些方法都是用来支持Hadoop文件系统实现的。对于系统问题和管理相关的操作,则是由DFSAdmin 这个工具类发起的,其中的方法用于支持管理员配置和管理HDFS,ClientProtocol还包括安全、XAttr等方法
1.读写数据相关方法
客户端读取文件方法主要是两个 LocatedBlocks getBlockLocations(String src, long offset, long length) throws IOException 和 void reportBadBlocks(LocatedBlock[] blocks) throws IOException。客户端会调用ClientProtocol.getBlockLocations() 方法 获取HDFS文件指定范围内所有的数据块的位置信息。其方法参数是HDFS文件的文件名和读取范围,返回的是指定范围内所有的数据块的文件名和其位置信息,使用 LocatedBlocks 对象对结果进行封装。每个数据块的位置信息指的是存储这个数据块的副本的所有DataNode信息,这些DataNode会以与当前客户端的远近顺序排列。
客户端会调用ClientProtocol.reportBadBlocks() 方法向NameNode汇报错误的数据块。当客户端从DataNode 读取数据块,且发现数据块的校验和不正确时,就会调用这个方法向NameNode汇报这个错误的数据块
2.写/追加写相关方法
在ClientProtocol中定义了8个方法只是HDFS文件的写操作包括:HdfsFileStatus create(String src, FsPermission masked, String clientName, EnumSetWritable<CreateFlag> flag, boolean createParent, short replication, long blockSize, CryptoProtocolVersion[] supportedVersions, String ecPolicyName, String storagePolicy) throws IOException; LastBlockWithStatus append(String src, String clientName, EnumSetWritable<CreateFlag> flag) throws IOException; LocatedBlock addBlock(String src, String clientName, ExtendedBlock previous, DatanodeInfo[] excludeNodes, long fileId, String[] favoredNodes, EnumSet<AddBlockFlag> addBlockFlags) throws IOException; boolean complete(String src, String clientName, ExtendedBlock last, long fileId) throws IOException; void abandonBlock(ExtendedBlock b, long fileId, String src, String holder) throws IOException; LocatedBlock getAdditionalDatanode(final String src, final long fileId, final ExtendedBlock blk, final DatanodeInfo[] existings, final String[] existingStorageIDs, final DatanodeInfo[] excludes, final int numAdditionalNodes, final String clientName ) throws IOException; LocatedBlock updateBlockForPipeline(ExtendedBlock block, String clientName) throws IOException; void updatePipeline(String clientName, ExtendedBlock oldBlock, ExtendedBlock newBlock, DatanodeID[] newNodes, String[] newStorageIDs) throws IOException;create() 方法用于在HDFS的文件系统目录树中创建一个新的空文件,创建路径由src参数指定,这个空文件创建后对于其他客户端是只读的,直到这个文件被关闭或者租约过期。客户端在写一个新的文件时,会首先调用create() 方法在文件系统中创建一个空文件,接着调用addBlock() 方法来获取存储文件数据的数据块的位置信息(向nn申请数据块存储在哪些dn上),接着客户端可根据返回的位置信息与DataNode简历数据流管道,向DataNode写入数据
append() 方法用于打开一个已有的文件,如果这个文件的最后一个数据块没有写满,则返回这个数据块的位置信息;如果这个文件的最后一个数据块正好写满,则创建一个新的数据块,并添加到这个文件中,然后返回这个新添加的数据块的位置信息。客户端会先调用append() 方法获取最后一个可写入的数据块信息,然后简历数据流管道,并向DataNode追加数据,如果正好写满,则会跟create() 方法一样,先调用addBlock() ,再与对应的DataNode建立数据流管道,然后写入
addBlock() 方法用于向指定文件添加一个新的数据块,并获取存储这个数据块的所有DataNode 的位置信息,在调用addBlock() 方法时,还需要传入上一个数据块的引用。NameNode在分配新的数据块时,会顺便提交上一个数据块,excludeNodes 则是DataNode的黑名单,保存了一些客户端无法链接的DataNode,favoredNodes 则是客户端希望的数据块副本的DataNode列表
complete() 方法会在整个客户端完成文件写入操作后,用于通知NameNode。这个操作会提交新写入HDFS文件的所有数据块,当这些数据块的副本数量满足系统配置的最小副本数(默认为1),complete方法会返回true,此时NameNode中的文件状态会由构建中状态转化成正常状态,如果返回的是false,客户端就需要重复调用 complete直到返回true
以上一些方法是在正常的读取,写入流程中与NameNode交互的接口,当系统出现故障时,以下这些方法可用于在异常情况下的恢复操作:
客户端调用 abandonBlock() 方法放弃申请新的数据块,当客户端获取一个新申请到的数据块时,发现无法与该数据块所在的DataNode建立连接,就会调用此方法,然后可以再次调用addBlock() 方法重写获取数据块,并在传入参数时,将上次创建的数据块所在的DataNode加入黑名单。
客户端调用getAdditionalDatanode() 方法向NameNode申请一个新的DataNode 来替换出在写入数据和过程中出现故障的DataNode,然后再调用updateBlockForPipeline() 方法向NameNode申请为新的数据块分配新的时间戳,这样故障节点上没能写完整的数据块的时间戳就会过期,在后续进行数据块汇报的过程中就会被删除。最后,客户端可以使用新的时间戳与新的DataNode建立数据流管道,来执行对数据块的写操作,管道建立成功后,还需要调用 updatePipeline() 方法更新NameNode中当前数据块的数据流管道信息
由此可见,上述方法中,前半部分是正常的数据写入读取的相关操作,后半段是在写入过程中,出现了节点异常的相关恢复方法。注意对于任意客户端在打开文件时,都需要定期调用ClientProtocol.renewLease() 方法来续约,如果NameNode长时间没收到Client 的续约更新消息,就会认为Client 发生故障了。
3.namespace相关管理
在ClientProtocol中有很重要的一部分操作是针对NameNode 的 namespace 进行修改的,FileSystem类也定义了一系列的对文件系统namespace修改的api,HDFS满足FileSystem类抽象的所有方法
4.系统问题与管理操作
ClientProtocol中另外一个重要的部分就是支持DFSAdmin 工具接口方法,DFSAdmin是提供HDFS管理员管理HDFS集群的命令行工具,下图展示了对应接口与 hdfs dfsadmin 命令的对应关系
5.快照相关操作
在Hadoop2.X添加了新的快照特性,用户可以为HDFS 的任意路径创建快照。快照保存了一个时间点上的HDFS某个路径中的所有数据拷贝,快照可以将失效的集群回滚到快照对应的时间点上,在创建快照之前,必须通过 hdfs dfsadmin -allowSnapshot命令开启目录快照功能,下标中展示了ClientPortcol 中的方法与对应的指令的关系
6.缓存相关操作
HDFS2.3版本添加了集中式缓存管理。用户就可以指定一些经常被使用的数据或者优先级任务对应的数据,让他们常驻内存而不被淘汰到磁盘上,提升Hadoop系统和上层应用的执行效率 -
ClientDatanodeProtocol
ClientDatanodeProtocol 定义了客户端与DataNode之间的接口,其主要分为2部分:一部分是支持HDFS文件读取操作的,另外一部分支持DFSAdmin中与DataNode管理相关的命令
-
long getReplicaVisibleLength(ExtendedBlock b) throws IOException;
客户端会调用本方法从数据节点或者某一个数据块副本的真实数据长度。当客户端读取一个HDFS文件时,需要获取这个文件对应的所有数据块的长度,用于简历数据块的输入流,然后进行数据读取,但是NameNode 的元数据中文件最后一个数据块的长度可能与实际的不一致,所以需要调用这个方法获取真实长度 -
BlockLocalPathInfo getBlockLocalPathInfo(ExtendedBlock block,Token token) throws IOException;
HDFS对于本都读取,也就是客户端与DataNode在同一物理机,是做了很多优化的。客户端会调用这个方法获取指定数据块文件和其校验文件在当前物理机上的本地路径,然后利用这个本地路径直接执行读取操作,而不是通过流式接口执行远程读取,这样优化了读取性能 -
void refreshNamenodes() throws IOException;
在管理员用户执行 hdfs dfsadmin datanodehost:port 命令,用于触发指定的DataNode重新加载配置文件,停止服务哪些已经从配置文件中删除的块池(blockPool),开始服务新添加的块池,当前命令就是通过调用 ClientDatanodeProtocol .refreshNamenodes() 实现的 -
void deleteBlockPool(String bpid, boolean force) throws IOException;
当前方法用于删除指定DataNode 中 bpid对应的块池 -
void shutdownDatanode(boolean forUpgrade) throws IOException;
用于关闭某一个DataNode -
DatanodeLocalInfo getDatanodeInfo() throws IOException;
获取某一个dataNode的信息,包括其运行的版本,启动时间等等 -
void startReconfiguration() throws IOException;
本方法异步触发DataNode从磁盘重新加载配置文章来源:https://www.toymoban.com/news/detail-424620.html -
ReconfigurationTaskStatus getReconfigurationStatus() throws IOException;
本方法获取上次DataNode 异步加载配置的成功状态文章来源地址https://www.toymoban.com/news/detail-424620.html
-
到了这里,关于hadoop源码解析-HDFS通讯协议(上- ClientProtocol 和 ClientDataNodeProtocol)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!